学习正则,我们到底要学什么?
你好,我是涂伟忠。从今天开始,我们就要一起来学习正则表达式了。
我相信,作为一名程序员或者准程序员,你肯定是知道正则表达式的。作为计算机领域最伟大的发明之一,正则表达式简单、强大,它可以极大地提高我们工作中的文本处理效率。现在,各大操作系统、编程语言、文本编辑器都已经支持正则表达式,甚至我还和极客时间的编辑开玩笑说,他们也应该好好学学正则这门手艺。
但是,当我去和朋友深入聊天的时候,才发现很多人是没有系统学习过正则表达式的,他们和我笑着说,这东西不难,我每次用的时候都是去 Google 搜一搜,然后复制过来改一改,效率特别高,我听完之后哭笑不得。
再后来,我和极客时间合作了一个关于正则表达式的每日一课课程,在课程的留言里,很多用户讲了他们的困惑,我总结了下,主要有4点:
- 学过正则,但觉得过于复杂,根本记不住;
- 在网上找到的正则和自己的需求有一点出入,看不懂,也不知道该怎么改;
- 不清楚正则的流派和支持情况,搞不懂为何自己写的正则没达到效果;
- 不清楚正则的工作原理,结果写出的正则或者从网上随便找来的正则出现了性能问题。
为什么会出现这些问题呢?我觉得是核心原因主要是以下几点:
- 没重视过正则,觉得没必要专门花时间学习,用的时候才发现“书到用时方恨少”;
- 没系统学习过正则,只简单地使用过部分功能,自然也就不清楚正则流派及工作原理等内容了;
- 没找到正确的方法去学习和记忆,导致学了之后很快就忘了。
所以,我打算通过一个课程,用尽可能通俗易懂的方式,系统化地给你梳理和讲解正则的知识点,希望可以帮助你解决上面这些问题,让正则这个强大的工具在你手上发挥出真正的威力。
但是呢,真要开始学正则,我想你的心头可能会五味杂陈,内心也是纠结万分。美国一位知名程序员杰米·加文斯基(Jamie Zawinski)说过一句话:
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.
这句话流传在程序员中间,给人一种感觉,就是正则是很难掌握和利用好的工具。也正因如此,很多程序员并不愿意去学正则表达式,心里可能是这么想的:我在工作中用到正则的时候并不多啊,要用的时候搜一下就好了啊,为什么还要专门花时间和精力学它呢?
但我觉得,真实的情况可能是这样的: 不是工作中用不到,而是当你不熟悉一个技能的时候, 遇到问题时根本不会考虑它。比如我们要删除掉文本中的所有数字,不知道正则的话,你可能会想到从0到9这样一个个替换,操作10次,但如果知道正则,那么只需要替换一次就可以搞定这个问题。
正则是什么,能做什么?
说了这么多,到底什么是正则呢?它能做什么呢?
我们先来说概念。正则,就是正则表达式,英文是 Regular Expression,简称 RE。顾名思义,正则其实就是一种 描述文本内容组成规律的表示方式。
在编程语言中,正则常常用来简化文本处理的逻辑。在Linux命令中,它也可以帮助我们轻松地查找或编辑文件的内容,甚至实现整个文件夹中所有文件的内容替换,比如 grep、egrep、sed、awk、vim 等。另外,在各种文本编辑器中,比如 Atom,Sublime Text 或 VS Code 等,在查找或替换的时候也会使用到它。总之,正则是无处不在的,已经渗透到了日常工作的方方面面。
简单来说,正则是一个非常强大的文本处理工具,它的应用极其广泛。我们可以利用它来校验数据的有效性,比如用户输入的手机号是不是符合规则;也可以从文本中提取想要的内容,比如从网页中抽取数据;还可以用来做文本内容替换,从而得到我们想要的内容。
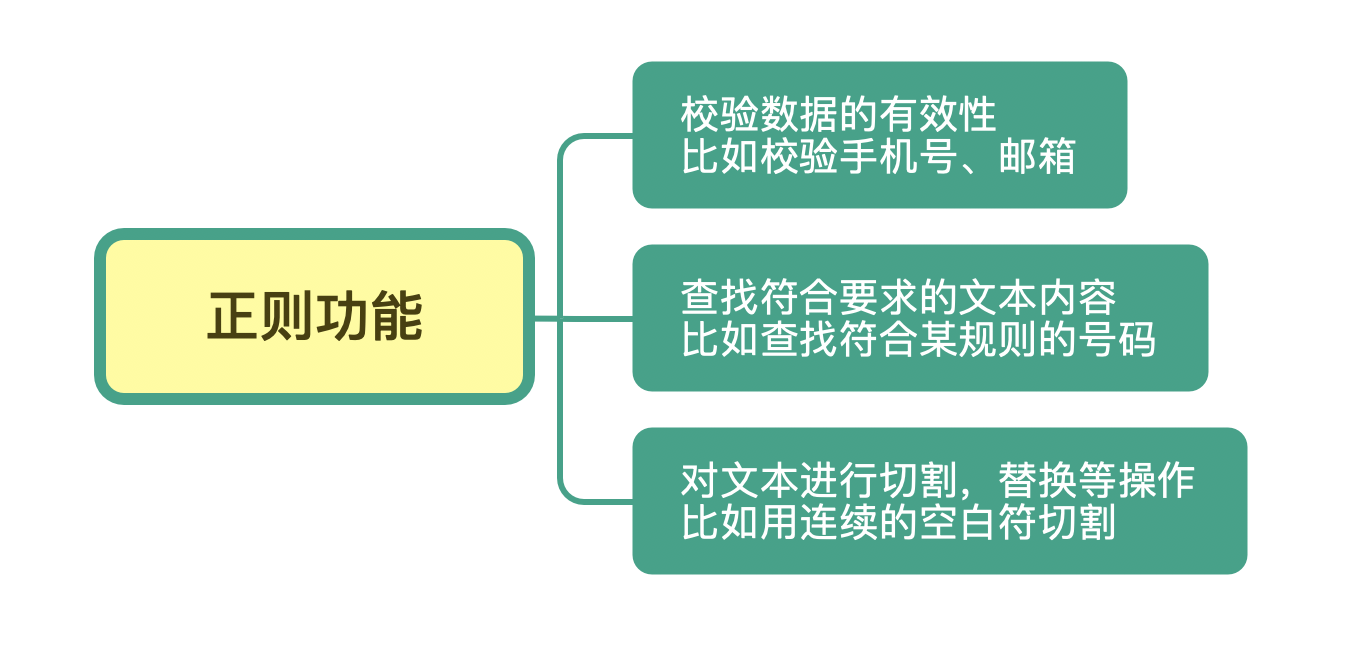
通过它的功能和分布的广泛你也能看出来,正则是一个非常值得花时间和精力好好学习的基本技能。之前你花几十分钟才能搞定的事情,可能用正则很快就搞定了;之前不能解决的问题,你系统地学习正则后,可能发现也能轻松解决了。
学习正则,我们到底要学什么?
那么问题来了,想要掌握正则,我们到底要学什么?我在课程中又是怎么安排这些内容的呢?
1.正则的基本知识
正则的很多基本知识其实并不难,只是难记。不过,记住一个东西并不是我们的最终目的,我们的目的是理解并且会用正则这个工具。
比如正则中的各种元字符,在课程中,我会讲有关元字符的记忆技巧,让你不再对元字符感到头疼。再比如各种模式和分组,它们可以在查找和替换时发挥强大的威力。
下面我用Python语言示例,从文本中找出连续出现的重复单词。我们可以看到,正则可以很方便地搞定这个需求。
>>> import re
>>> test_str = "the little cat cat in the hat hat."
>>> re.sub(r'(\w+) \1', r'\1', test_str)
'the little cat in the hat.'
但上面的示例在任何情况下都能很好地工作么?我们要不要考虑单词的边界?反向引用又有哪些要注意的点?所有这些问题都会在课程中一一进行讲解。
2.在常见的编辑器中使用正则的方法
我们经常需要从大段文本中抽取需要的内容,学会使用正则之后,不用写代码就可以完成类似的日常工作。举个例子,假如我们在Sublime Text 3 中使用正则,查找重复出现的单词,并且想把它替换成单个单词。
菜单中的 Find -> Replace,在查找栏中输入 (\w+) \1,在替换栏中输入子组的引用 \1 ,然后点击 Replace All 就可以完成替换工作了。这样,通过少量的正则,我们就完成了文本的处理工作了。是不是很方便呢?
3.正则中进阶的内容
除此之外,我还会在课程中讲一些更高阶的正则内容,这部分主要有正则中的断言(包括单词边界、行开始和结束、环视),三种主要流派的区别以及对应的软件实现,正则的工作机制和常见的优化方式等。
掌握这些内容可以让我们更好地理解正则, 也可以避过很多坑。比如,为什么在编程语言中能工作的正则,在Linux命令 grep 中就不能工作了呢?正则匹配的原理又是什么?如何写出性能更好的正则呢?
综合以上这三点,我希望你能掌握的是正则中一些重要的概念和功能,这是我们学习和使用正则的基础;然后是有关正则的记忆方法,通过合理的方式,事半功倍地达到学习效果,这是我们学习正则的利器;此外,我还会运用大量的示例让你了解正则在实际工作场景中的使用,只有与现实案例结合,我们的学习才不会脱节,这是我们学习正则的原则。
明确原则、打好基础、掌握利器,我相信你一定可以拿下正则这项技能,在工作中随心所用。学完后,你一定会觉得,手写正则原来也没有那么难。
话不多说,我们这就开始吧!
导读 | 余晟:我是怎么学习和使用正则的?
你好,我是余晟。受伟忠的邀请,今天我来和你聊聊我是怎么学习和使用正则的。
刚工作那会儿,因为密集用到正则表达式,所以我花了不少时间去钻研正则相关的问题,因此获得了机会,翻译了《精通正则表达式》(第三版),后来又写了一本书《正则指引》。到如今,许多年过去了,这些东西还历历在目,我也很乐意拿出来和你分享一下,希望在学习正则的道路上,能给你一些启发。
我经常在网上看到,许多⼈抱怨正则表达式“难学”,我知道,它确实不好学。但同时,我也去看过大家的抱怨,发现和我之前的做法⼀样:用到什么功能,就去网上搜⼀个例⼦来改改,能跑通就满意。至于这例子到底如何构成的,自己是不是都懂了,其实心里没底,能大概看懂五六分,就已经很满足了。
这样浮光掠影的使用方法或许能解决眼前的问题,但⼀定不算“学会”。它有点像打井,每次挖到⼀点水就满足了,根本不管有没有持续性,也不关心挖没挖到含水层。结果就是,每次要喝水的时候,你都得重新打⼀眼井。
那么对于正则表达式,我们有没有可能打出一口“永不干涸”的深井呢?当然有,那就是 ⼀次性多投入点时间,由表及里,由术及道。一旦掌握了方法,之后就会简单很多了。
按照我的经验,如果每天花一刻钟或者半小时,坚持个把礼拜,通常都能登堂入室,达到“不会忘”的境界。不要以为这时间很多,我知道有些人很喜欢找“正则表达式五分钟入门”,其实每次都没有入门,日积月累,反而浪费了几十甚至上百个五分钟。
那多投入时间很好理解,但是什么叫掌握方法呢?用我的话说,就是摆脱了字符的限制,深入到概念思维的层面。不要盯着那些鬼画桃符⼀般的字符和表示法皱眉,要摆脱桃符,把真正的“鬼”给认出来——虽然它们不那么容易看见。 也正因为这样,我们才需要⼀次性多投入点时间。
那最终怎样才算“入门”了呢?按照我的经验,就是通过学习掌握方法,后来无论用正则表达式解决什么问题,都能自发遵循下面的流程去走,甚至能达到不需要这个流程,也能做到解决问题,那基本上就算入门了。
第⼀步,做分解。 拿到一个问题后,我们要先思考:这个问题可以分为几个子问题?每个子问题是否独立?我们拿最常见的电子邮件地址匹配来说。从文本结构来看,它可以分为“username + @ + domain name”这三个独立的部分。怎么画呢?我们可以先画出逻辑结构图。通过这个过程来厘清思路。当然,这是软件⼯程最基本的思路,相信你做起来应该问题不大。
第⼆步,分析各个子问题。 某个位置上可能有多个字符?那就用字符组。某个位置上可能有多个字符串?那就用多选结构。出现的次数不确定?那就用量词。对出现的位置有要求?那就用锚点锁定位置…… 某种程度上,这就像武术里的见招拆招,每个问题都有对应的解法,只要熟练掌握了,知道什么时候用字符组,什么时候用多选结构,什么时候用量词,什么时候用锚点,就很容易搭建起完整的概念模型。
第三步,套皮。 你大概注意到了,到现在,我们还没有谈论正则表达式的典型标志,比如方括号、星号、花括号。要知道,这些典型标志无非只是一些符号而已,真正重要的是字符组、多选结构、量词等等这些概念。一旦你的概念模型清楚了,写出正则表达式就非常简单了,无非是查阅语法手册,把之前得到的概念模型按照对应语言或工具的约定写下来而已。
许多人觉得正则表达式难懂,总是纠缠于“这里为什么要多一个星号?那里为什么是方括号而不是花括号?”,原因恰恰在于对概念模型不清楚。虽然各种语言或工具对正则表达式的支持大同小异,但细微差别仍然不可忽视。不过只要你心怀正念,洞若观火,这些差异其实并不是大问题。
第四步,调试。 很多人都说,正则表达式的麻烦之处在于它像个黑箱子,很难调试,迄今为止仍然没有特别好用的⼯具,所以我们没法⼀步步跟进去看匹配的具体过程,只能笼统地知道“匹配了”或者“没匹配”。
那到底怎么调试呢?我的经验是,复杂⼀点的正则表达式不能⼀次写对,这是很正常的。与其纠结“这个正则表达式看起来这么复杂,此处到底要用星号\还是加号+,不如先搞清楚,星号( \ )或加号( + )限定的到底是正则表达式中的哪一部分,对应要匹配文本中的哪一部分。这两个问题搞清楚了,整个问题就迎刃而解了。
另外,还有⼀点统摄全局的经验想和你说一下, 那就是学会了正则表达式之后,务必要保持克制。写正则表达式很容易上瘾,毕竟它的功能那么强⼤,处理速度那么快,⼜像天书符咒那样充满了“神秘”色彩。于是,“写⼀条其他⼈看不懂的正则表达式,⼀次性解决所有问题”,就成了某些程序员的执念。但是,从软件工程的角度来看,这种办法绝对是噩梦,不但其他人无法理解,自己过⼀段时间也会挠头。
那到底该怎么“克制”呢?我的经验有以下三点。
第⼀,能用普通字符串处理的,坚决⽤普通字符串处理 。 字符串处理的速度不见得差,可读性却好上很多。如果要在大段文本中定位所有的today或者tomorrow,用最简单的字符串查找,直接找两遍,明显比to(day|morrow)看起来更清楚。
第⼆,能写注释的正则表达式,⼀定要写注释。正则表达式的语法非常古老,不够直观,为了便于阅读和维护,如今大部分语言里都可以通过x打开注释模式。有了注释,复杂正则表达式的结构也能一目了然。
第三,能用多个简单正则表达式解决的,⼀定不要苛求用一个复杂的正则表达式。这里最明显的例子就是输入条件的验证。比如说,常见的密码要求“必须包含数字、小写字母、大写字母、特殊符号中的至少两种,且长度在8到16之间”。
你当然可以绞尽脑汁用一个正则表达式来验证,但如果放下执念,⽤多个正则表达式分别验证“包含数字”“包含小写字母”“包含大写字母”“包含特殊符号”这四个条件,要求验证成功结果数大于等于2,再配合一个正则表达式验证长度,这样做也是可行的。虽然看起来繁琐,但可维护性绝对远远强于单个正则表达式。
小结
好了,到此为⽌,我的经验介绍完了,可以交棒了。
这些年,很多人问过我,我当时到底是怎么学会正则的?说实话,我那会儿根本没想什么,纯粹出于“干一行爱一行”的朴素想法。要用得多,就找书来,哪怕是囫囵吞枣,也要一鼓作气看完。 我一直觉得,真正值得学的东西,没有什么“平滑学习曲线”。在前面的阶段,你总得狠下心来,过了一个又一个坎儿,然后才能有一马平川。
我觉得,正则表达式属于“没有维护成本”的技能。一旦学会了,每⼀次遇到这类问题都可以“零成本出击”。所以,长期来看,这绝对是一笔“无本万利”的生意。希望你能通过这个专栏早日达到一马平川!
元字符:如何巧妙记忆正则表达式的基本元件?
你好,我是涂伟忠。今天是课程的第一讲,我们一起来学习组成正则表达式的基本单元——元字符。
元字符的概念
在开篇词中,我们提到了正则常见的三种功能,它们分别是:校验数据的有效性、查找符合要求的文本以及对文本进行切割和替换等操作。
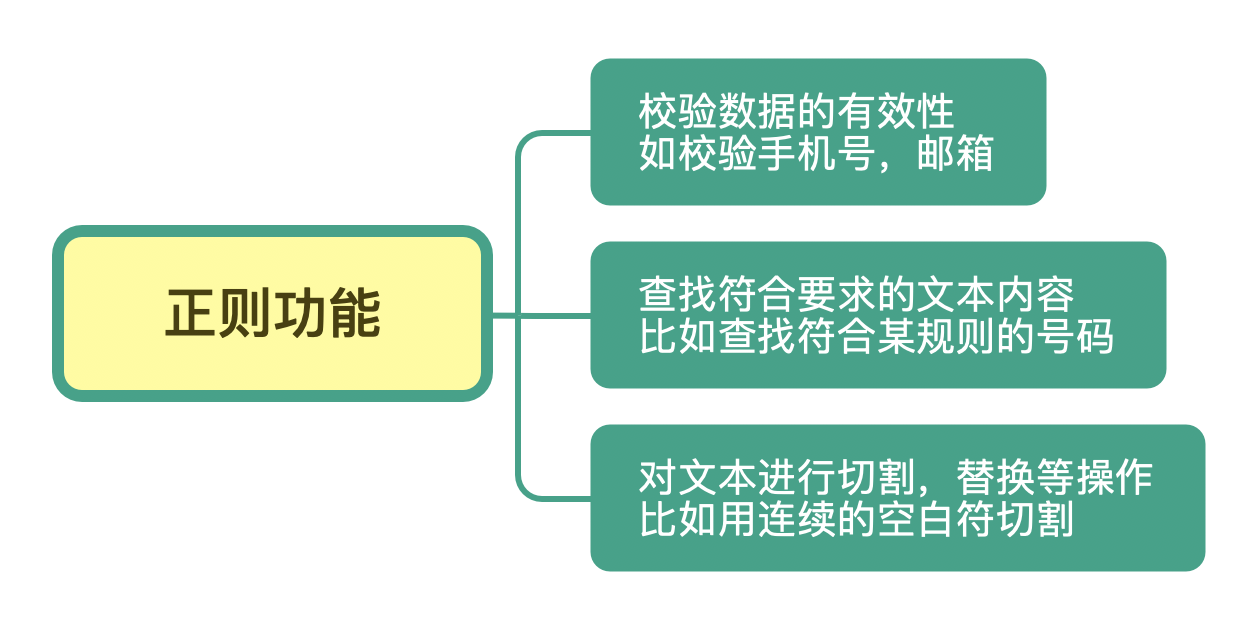
那你可能会好奇,正则是如何完成这些工作的呢?让我们先从简单的字符串查找和替换讲起。
我相信你一定在办公软件,比如Word、Excel 中用过这个功能。你可以使用查找功能快速定位关注的内容,然后使用替换,批量更改这些内容。
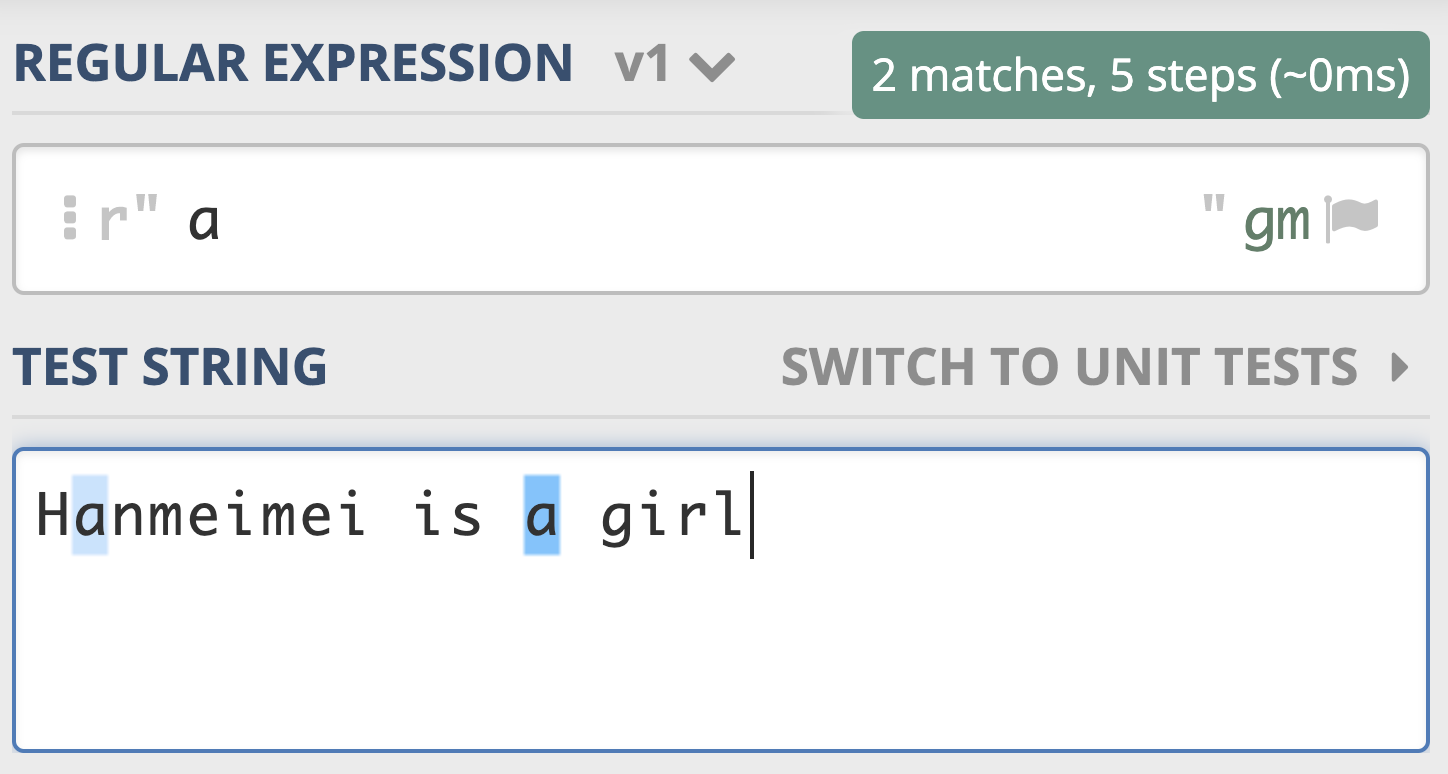
让我们再回过头看看正则表达式。正则表达式,简单地说就是描述字符串的规则。在正则中,普通字符表示的还是原来的意思,比如字符 a,它可以匹配“Hanmeimei is a girl”中的 H 之后的 a,也可以匹配 is 之后的 a,这个和我们日常见到的普通的字符串查找是一样的。
但除此之外,正则还可以做到普通的查找替换做不到的功能, 它真正的强大之处就在于可以查找符合某个规则的文本。
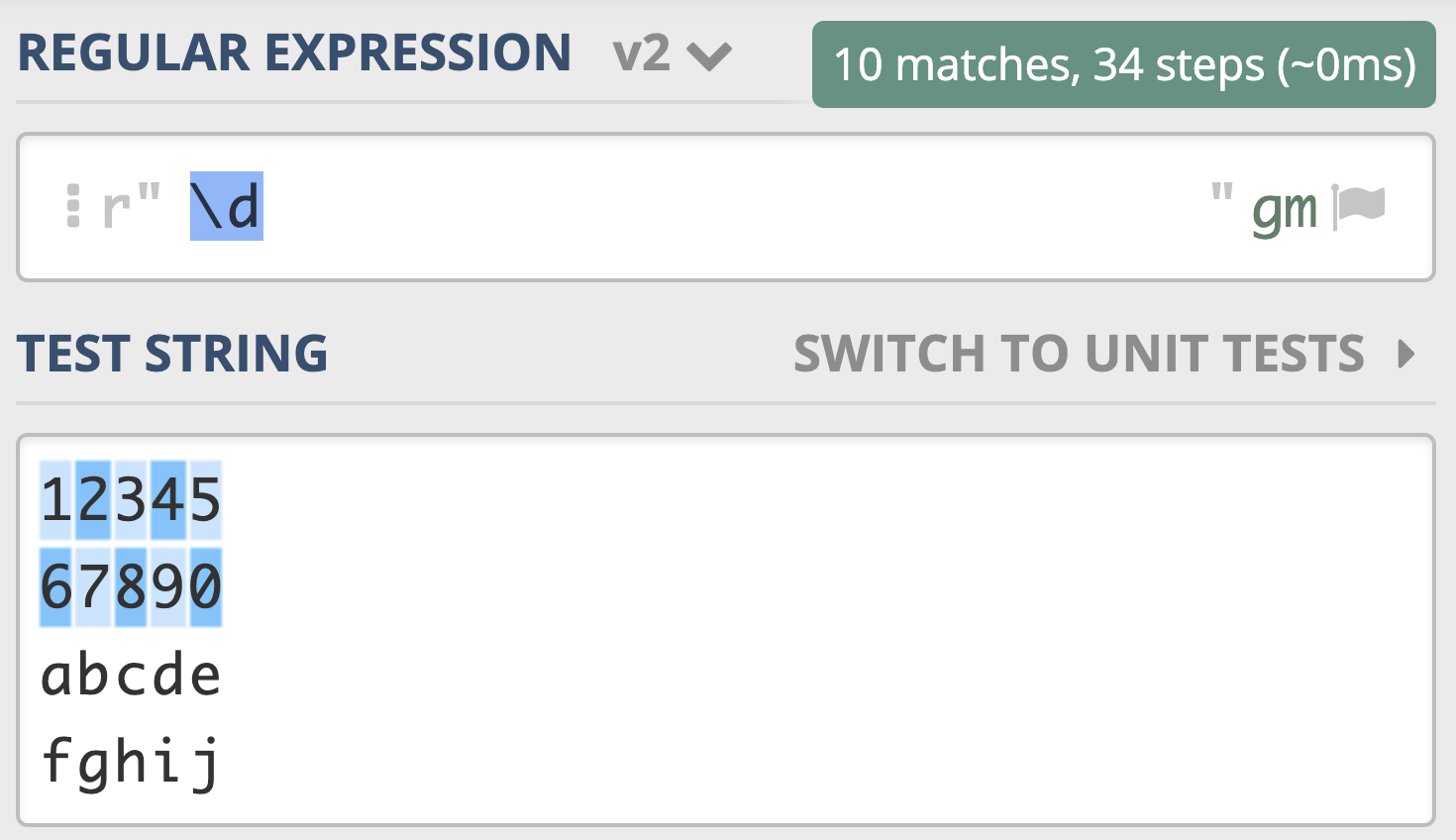
举个例子,假如你想查找文本中的所有数字,如果不会正则,可能需要手动敲数字,从0到9这样操作10次,一个个去查找,很麻烦。但如果用正则的话就方便很多了,我们直接使用 \d 就可以表示 0-9 这10个数字中的任意一个,如下图所示。
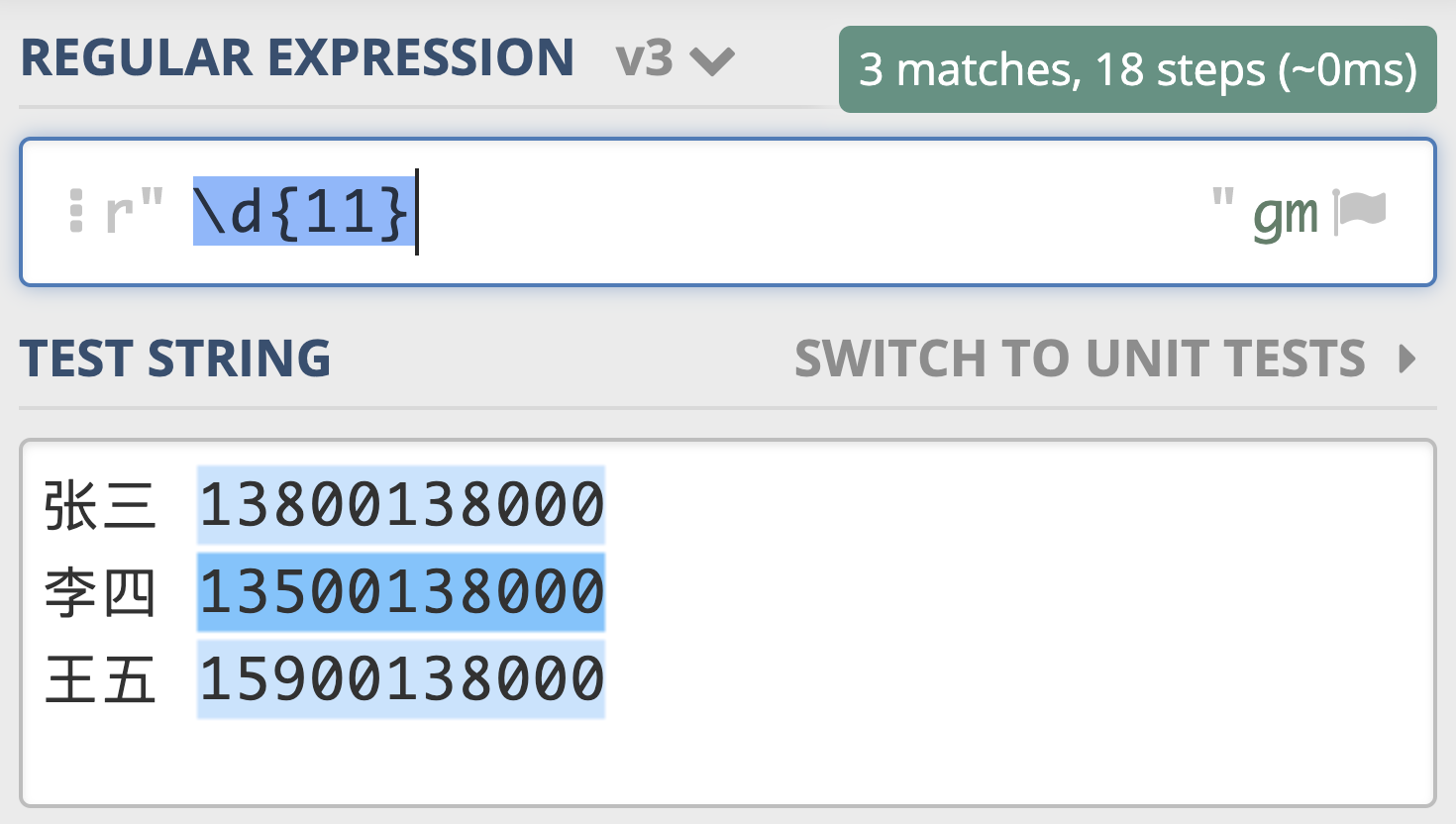
如果我们在后面再加上量词,就可以表示单个的数字出现了几次。比如 \d{11} 表示单个数字出现11次,即11位数字,如果文本中只有姓名和手机号,我们就可以利用这个查找出文本中的手机号了,如下图所示。
那么到这里,你有没有发现正则的不同呢?像查找数字一样,在正则中,我们不需要像往常一样输入一个确定的内容,只需要敲入特殊的符号就可以帮我们完成查找和替换,像上面案例中提到的 \d 和 {11},在正则中有一个专门的名称——元字符(Metacharacter)。
所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,元字符是构成正则表达式的基本元件。正则就是由一系列的元字符组成的,看到这里相信你也能明白元字符的重要性了吧。
但是,因为元字符很基础,又比较多,所以很多人看见正则就头疼。那么今天,我就通过分类的方式,教你理解并且巧妙地记忆、使用元字符。
元字符的分类与记忆技巧
正则表达式中有很多的“元字符”,比如刚刚提到的 \d,它在正则中不代表 \ (反斜杠) 加字母 d,而是代表任意数字,这种表示特殊含义的字符表示,就是元字符。正则表达式中,元字符非常多,那么我们如何才能记住它们呢?
这里我给你介绍一个方法,就是分类记忆。元字符虽然非常多,但如果我们按照分类法去理解记忆,效果会好很多。事实上,这个方法不光可以用在记忆元字符上,也可以用在记忆各种看似没有章法的内容上。
首先,我可以把元字符大致分成这几类:表示单个特殊字符的,表示空白符的,表示某个范围的,表示次数的量词,另外还有表示断言的,我们可以把它理解成边界限定,我会在后面的章节中专门讲解断言(Assertions)相关的内容。
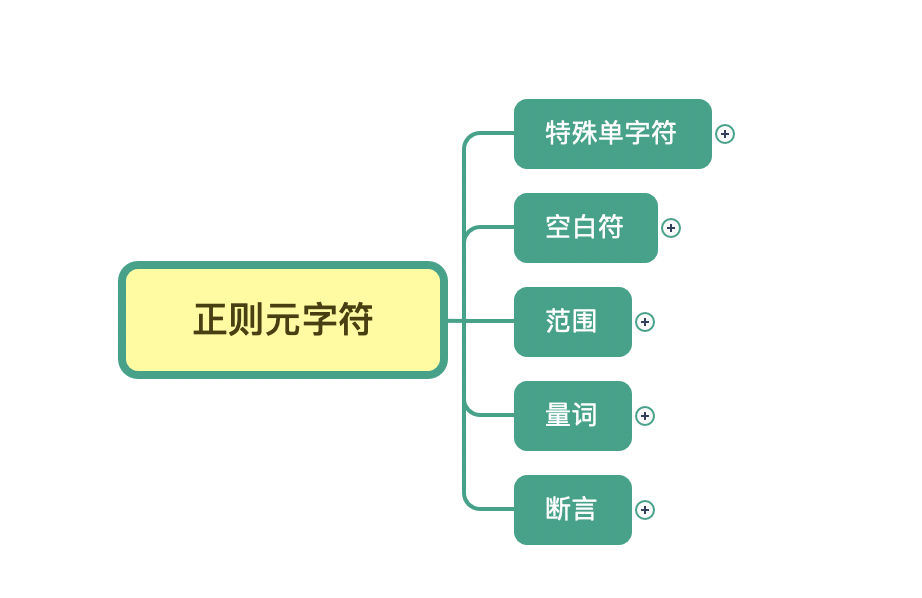
那么接下来,我们就按照前面说的元字符的分类,来逐一讲解下。
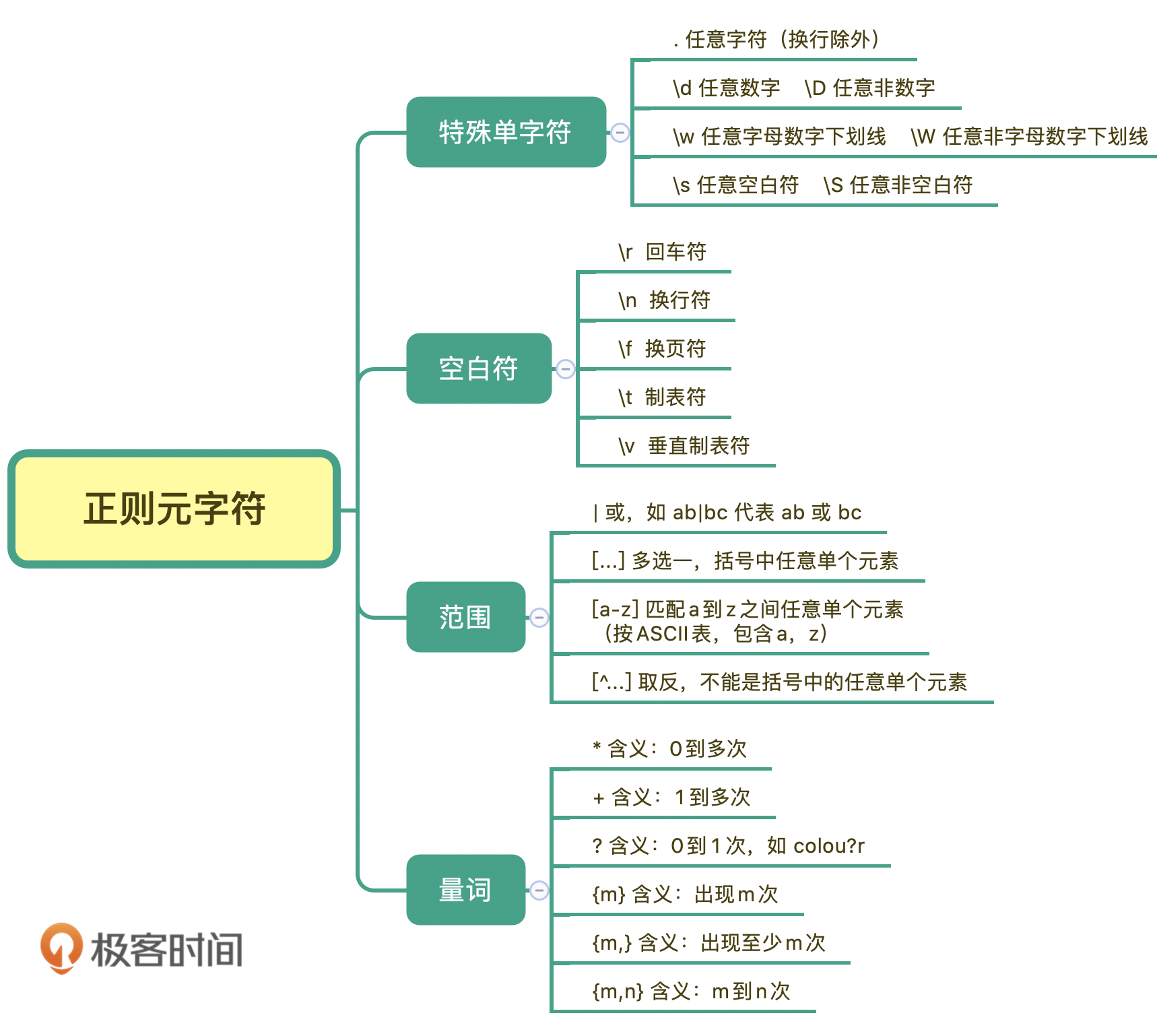
1.特殊单字符
首先,我们来看下表示特殊单个字符的元字符,比如英文的点(.)表示换行以外的任意单个字符,\d 表示任意单个数字,\w 表示任意单个数字或字母或下划线,\s 表示任意单个空白符。另外,还有与之对应的三个 \D、\W 和 \S,分别表示着和原来相反的意思。

现在我们来看一下测试,我把常见数字,字母,部分标点符号作为文本,用 \d 去查找,可以看到只能匹配上10个数字。
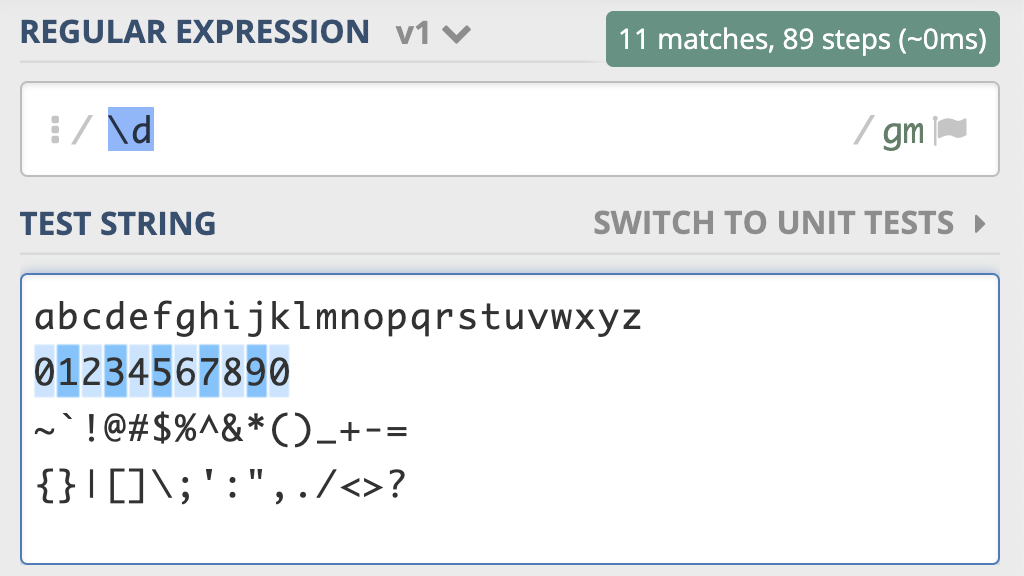
这是元字符 \d 测试用例的链接,你不妨测试一下: https://regex101.com/r/PnzZ4k/1
元字符 \w 能匹配所有的数字、字母和下划线,如下图所示:
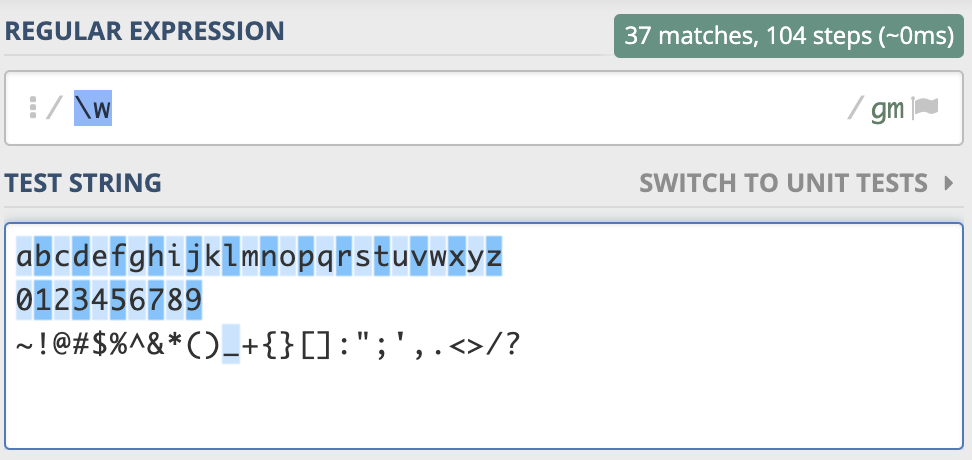
同样的,元字符 \w 测试用在这里: https://regex101.com/r/PnzZ4k/2
你可以自己去尝试一下 \W,\D,\s 和 \S ,以及英文的点的匹配情况,这里我不展开了。
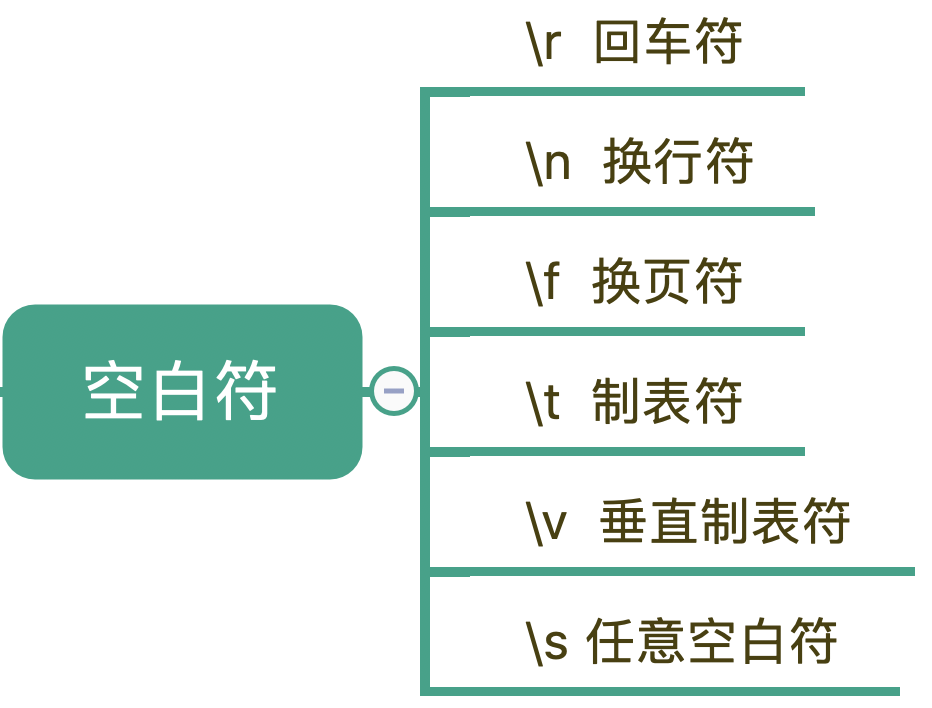
2.空白符
除了特殊单字符外,你在处理文本的时候肯定还会遇到空格、换行等空白符。其实在写代码的时候也会经常用到,换行符 \n,TAB制表符 \t 等。
有编程经验的程序员肯定都知道,不同的系统在每行文本结束位置默认的“换行”会有区别。比如在Windows 里是 \r\n,在 Linux 和 MacOS 中是 \n。
在正则中,也是类似于 \n 或 \r 等方式来表示空白符号,只要记住它们就行了。平时使用正则,大部分场景使用 \s 就可以满足需求,\s 代表任意单个空白符号。
我们可以看到, \s 能匹配上各种空白符号,也可以匹配上空格。换行有专门的表示方式,在正则中,空格就是用普通的字符英文的空格来表示。
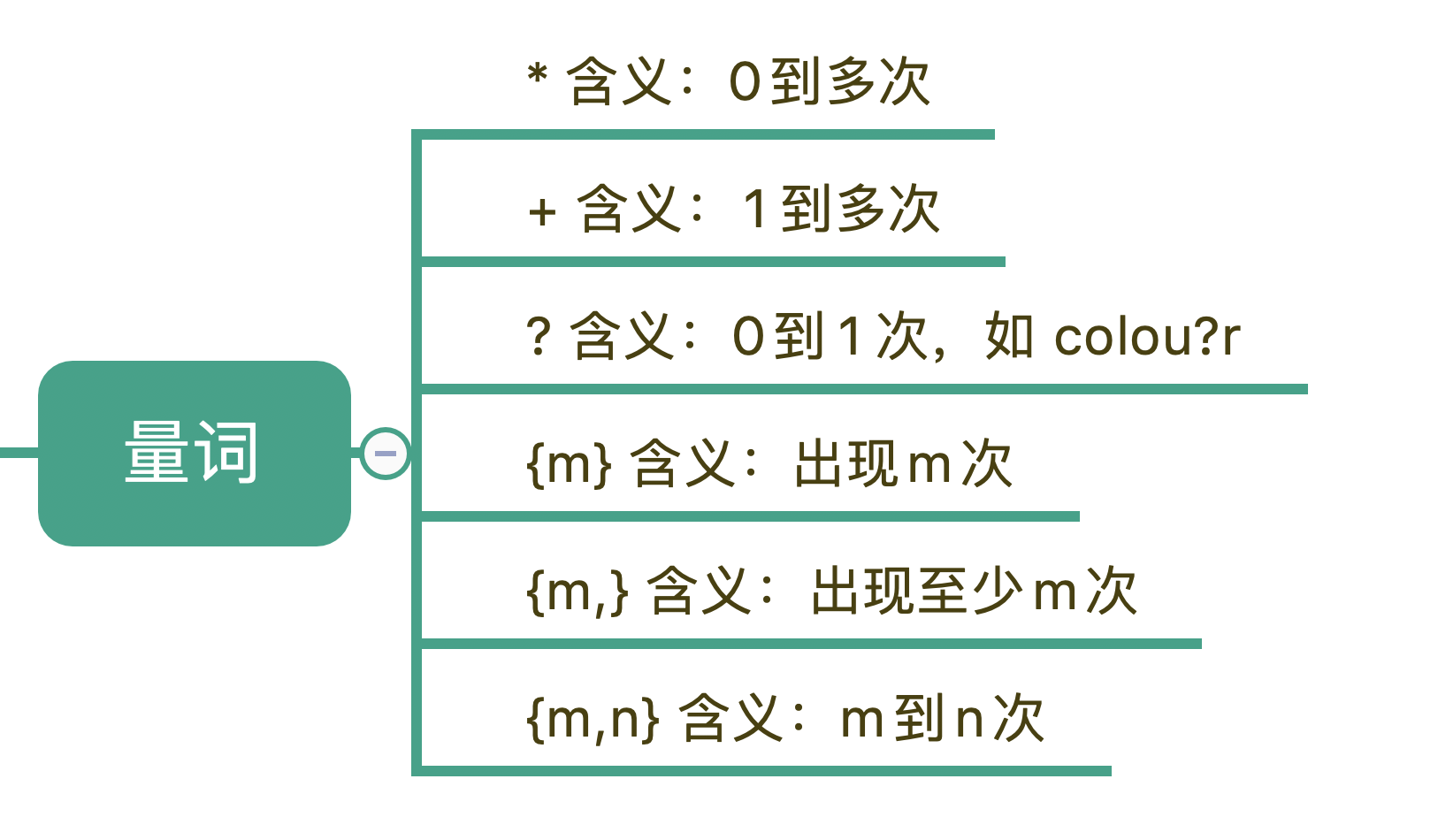
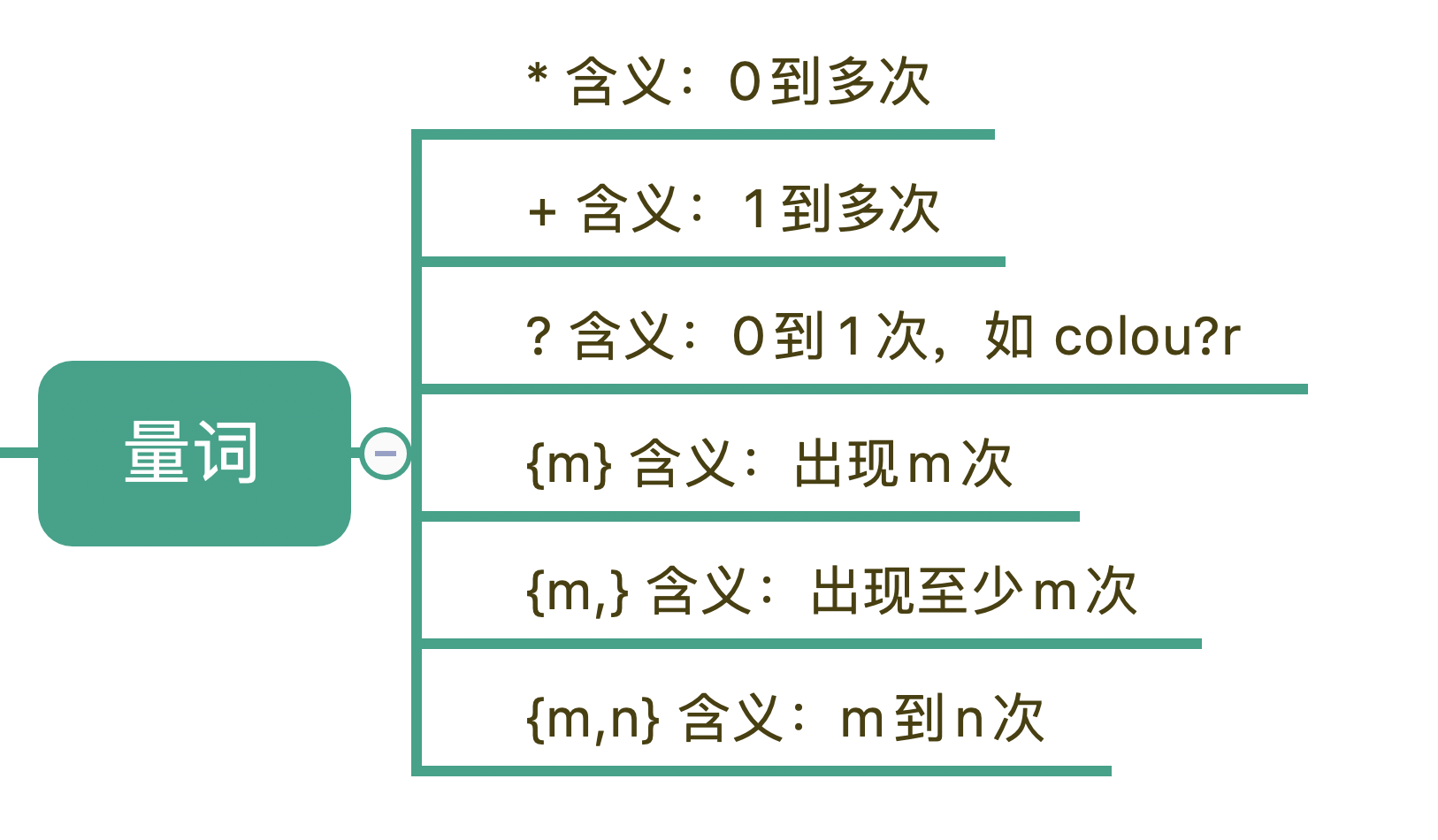
3.量词
刚刚我们说到的“基础”的元字符也好,“空白符”也好,它们都只能匹配单个字符,比如\d只能匹配一个数字。但更多时候,我们需要匹配单个字符,或者某个部分“重复N次”“至少出现一次”“最多出现三次”等等这样的字符,这个时候该怎么办呢?
这就需要用到表示量词的元字符了。
在正则中,英文的星号(*)代表出现0到多次,加号(+)代表1到多次,问号(?)代表0到1次,{m,n}代表m到n次。
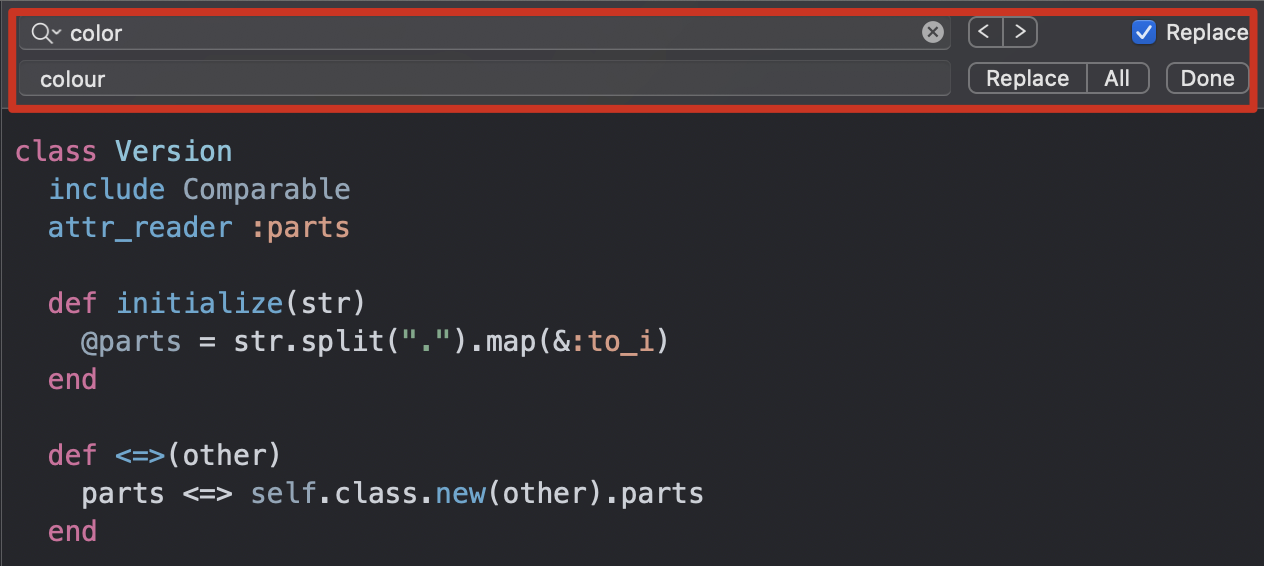
比如,在文本中“颜色”这个单词,可能是带有 u 的 colour,也可能是不带 u 的 color,我们使用 colou?r 就可以表示两种情况了。在真实的业务场景中,比如某个日志需要添加了一个user字段,但在旧日志中,这个是没有的,那么这时候可以使用问号来表示出现0次或1次,这样就可以表示user字段 存在和不存在 两种情况。
下面这段文本由三行数字组成,当我们使用 \d+ 时,能匹配上3个,但使用 \d* 时能匹配上6个,详细匹配结果可以参考下面的图片:
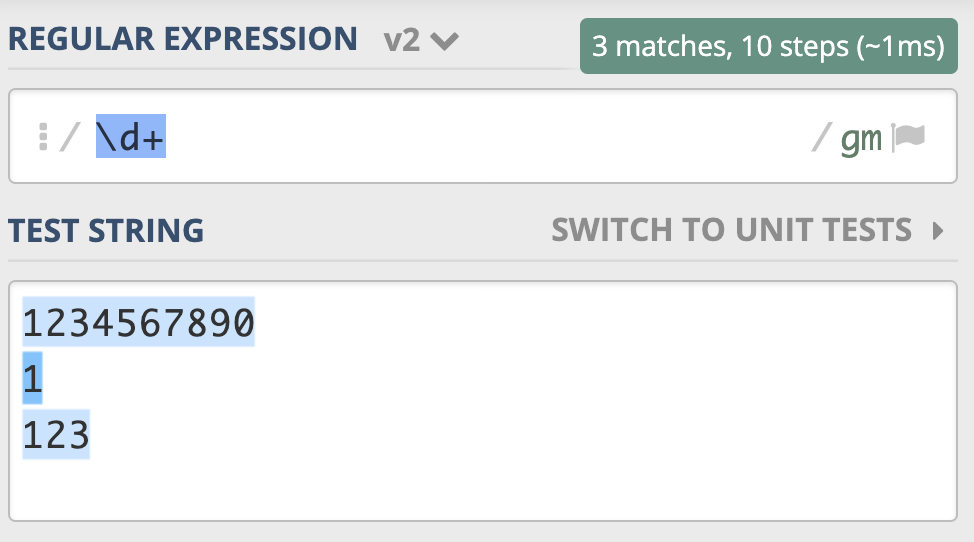
我把正则 \d+ 示例链接放在下面了,你可以看一下: https://regex101.com/r/PnzZ4k/8
其它的比如表示 m 到 n 次的,你可以自己去尝试,一定要多加练习,这样你才能记得牢。
4.范围
学习了量词,我们就可以用 \d{11} 去匹配所有手机号,但同时也要明白,这个范围比较大,有一些不是手机号的数字也会被匹配上,比如11个0,那么我们就需要在一个特殊的范围里找符合要求的数字。
再比如,我们要找出所有元音字母aeiou的个数,这又要如何实现呢?在正则表达式中,表示范围的元字符可以轻松帮我们搞定这样的问题。
在正则表达式中,表示范围的符号有四个分类,如下图所示。

首先是管道符号,我们用它来隔开多个正则,表示满足其中任意一个就行,比如 ab|bc 能匹配上 ab,也能匹配上 bc,在正则有多种情况时,这个非常有用。
中括号[]代表多选一,可以表示里面的任意单个字符,所以任意元音字母可以用 [aeiou] 来表示。另外,中括号中,我们还可以用中划线表示范围,比如 [a-z] 可以表示所有小写字母。如果中括号第一个是脱字符(^),那么就表示非,表达的是不能是里面的任何单个元素。
比如某个资源可能以 http:// 开头,或者 https:// 开头,也可能以 ftp:// 开头,那么资源的协议部分,我们可以使用 (https?|ftp):// 来表示。
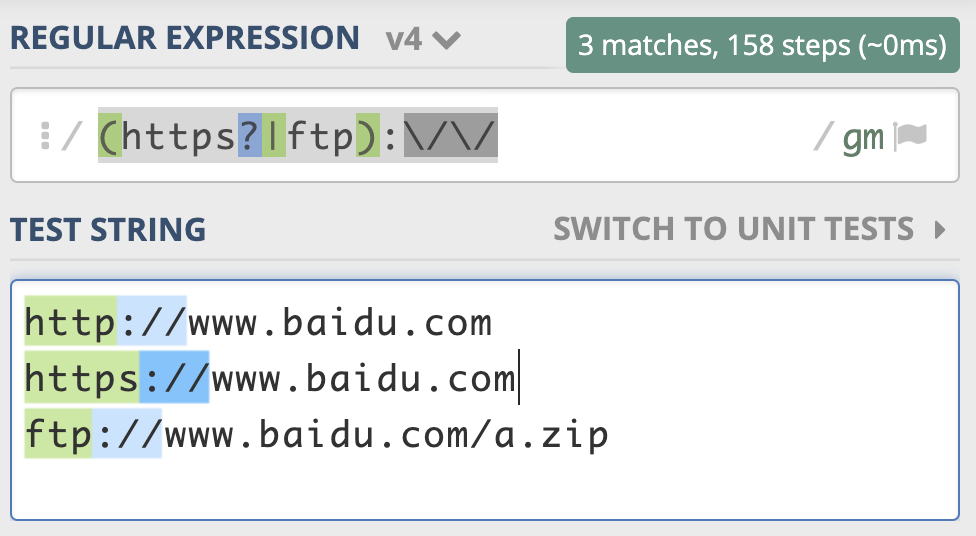
同样地,我把示例链接也放在了下面,你可以参考一下: https://regex101.com/r/PnzZ4k/5
总结
今天我通过大量的示例讲解了元字符,希望可以帮助你加强对正则各类元字符的理解,想办法记住它们,这是掌握正则这个强大工具的第一步。
我在这里给你强调一下学习的方法。你可以看到我在每一个案例中加入了测试链接,目的就是希望你能借此多做练习。在学习过程中,一定要找时间去练习,去观察匹配的结果,这样可以帮助你加深记忆。如果只是看和听,没有足够的练习,实际上很难记得牢,所以一定要自己多动手操作尝试。
还有一个方法,你可以把学到的知识,试着讲给其它的同事或同学,最好的学习方法就是去教别人,一个知识点,如果你能给别人讲明白,证明你真的搞懂了,真的掌握了这个知识。
好了,学习完今天的内容,最后我来给你总结一下。正则表达式中元字符的分类记忆,你可以在脑海中回忆一下。今天我们学习了正则表达式的部分元字符,特殊单字符、空白符、范围、量词等。我整理成了一张脑图,你可以看一下,对照着练习、记忆。
思考题
通过今天的学习,不知道你元字符掌握到何种程度了呢?那么不妨练习一下吧!我在这里给出一些手机号的组成规则:
- 第1位固定为数字1;
- 第2位可能是3,4,5,6,7,8,9;
- 第3位到第11位我们认为可能是0-9任意数字。
你能不能利用今天学到的知识,写出一个“更严谨”的正则来表示手机号呢?
好,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,让我们一起进步,共同掌握正则表达式这个强大的工具。
量词与贪婪:小小的正则,也可能把CPU拖垮!
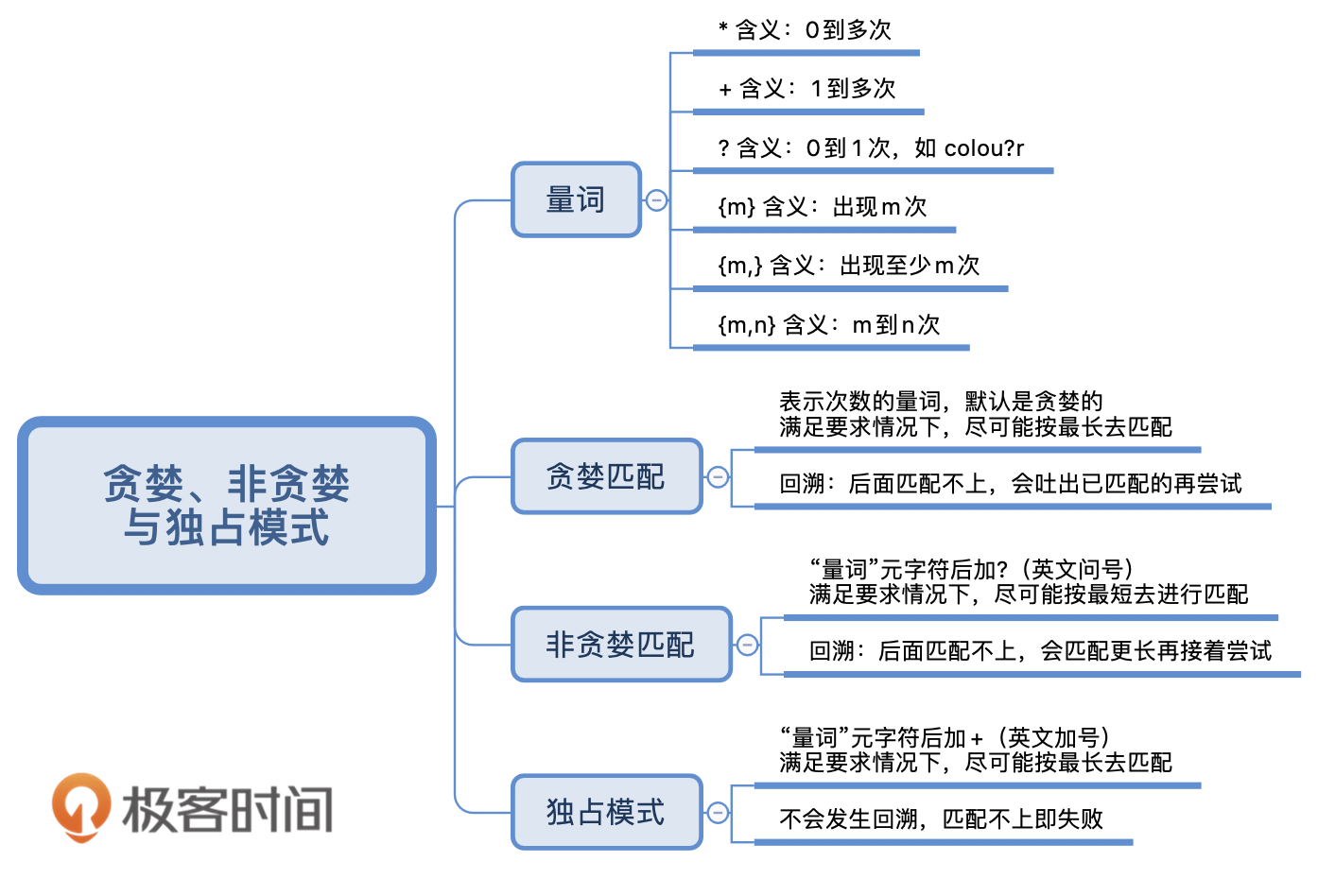
你好,我是涂伟忠。在上一讲中,我们已经学习了正则中和一些元字符相关的内容。这一节我们讲一下正则中的三种模式,贪婪匹配、非贪婪匹配和独占模式。
这些模式会改变正则中量词的匹配行为,比如匹配一到多次;在匹配的时候,匹配长度是尽可能长还是要尽可能短呢?如果不知道贪婪和非贪婪匹配模式,我们写的正则很可能是错误的,这样匹配就达不到期望的效果了。
为什么会有贪婪与非贪婪模式?
由于本节内容和量词相关的元字符密切相关,所以我们先来回顾一下正则中表示量词的元字符。
在这6种元字符中,我们可以用 {m,n} 来表示 (*)(+)(?) 这3种元字符:
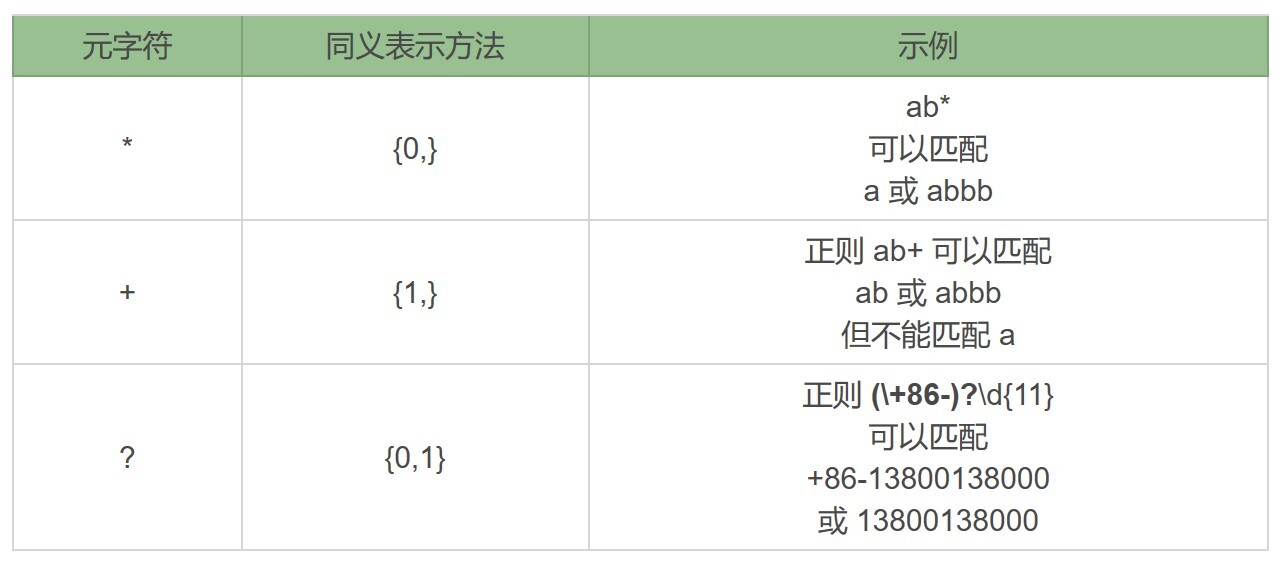
表示量词的星号(*)和 加号(+)可能没你想象的那么简单,我用一个例子给你讲解一下。我们先看一下加号(+),使用 a+ 在 aaabb 中查找,可以看到只有一个输出结果:
对应的Python代码如下:
>>> import re
>>> re.findall(r'a+', 'aaabb')
['aaa']
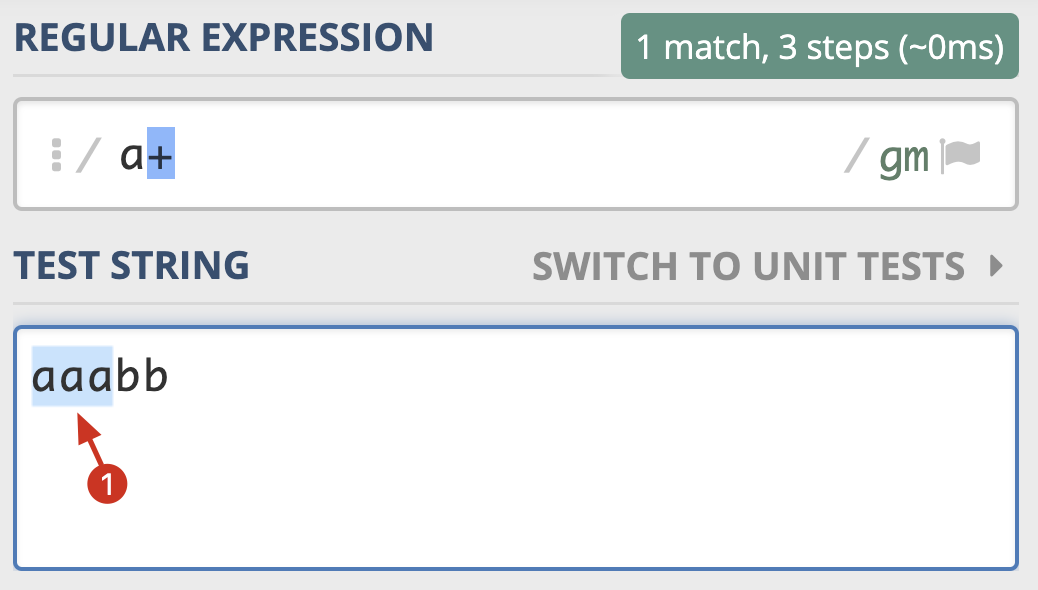
加号应该很容易理解,我们再使用 a* 在 aaabb 这个字符串中进行查找,这次我们看到可以找到4个匹配结果。
使用Python示例如下,我们可以看到输出结果,也是得到了4个匹配结果:
>>> import re
>>> re.findall(r'a*', 'aaabb')
['aaa', '', '', '']
但这一次的结果匹配到了三次空字符串。为什么会匹配到空字符串呢?因为星号(*)代表0到多次,匹配0次就是空字符串。到这里,你可能会有疑问,如果这样,aaa 部分应该也有空字符串,为什么没匹配上呢?
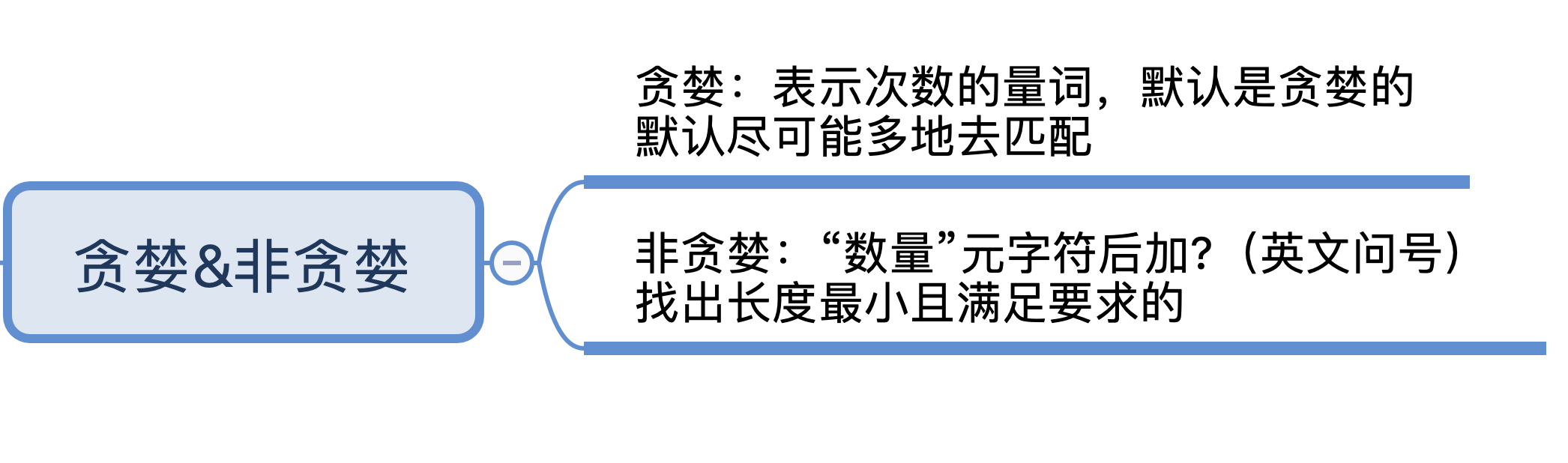
这就引入了我们今天要讲的话题,贪婪与非贪婪模式。这两种模式都必须满足匹配次数的要求才能匹配上。贪婪模式,简单说就是尽可能进行最长匹配。非贪婪模式呢,则会尽可能进行最短匹配。正是这两种模式产生了不同的匹配结果。
贪婪、非贪婪与独占模式
贪婪匹配(Greedy)
首先,我们来看一下贪婪匹配。在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
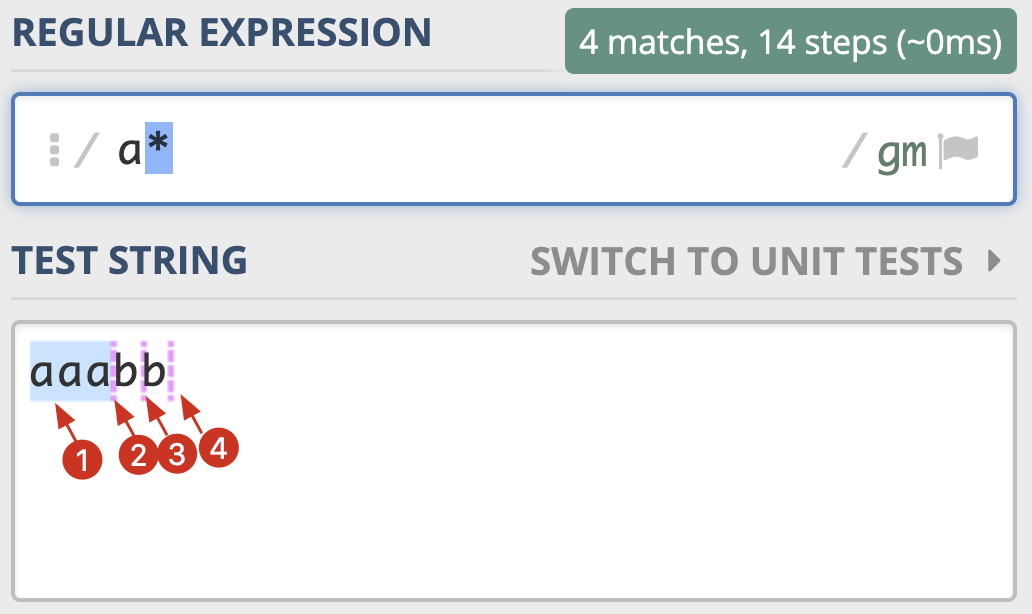
首先,我们来看一下在字符串 aaabb 中使用正则 a* 的匹配过程。

a* 在匹配开头的 a 时,会尝试尽量匹配更多的 a,直到第一个字母 b 不满足要求为止,匹配上三个a,后面每次匹配时都得到了空字符串。
相信看到这里你也发现了,贪婪模式的特点就是尽可能进行最大长度匹配。所以要不要使用贪婪模式是根据需求场景来定的。如果我们想尽可能最短匹配呢?那就要用到非贪婪匹配模式了。
非贪婪匹配(Lazy)
那么如何将贪婪模式变成非贪婪模式呢?我们可以在量词后面加上英文的问号(?),正则就变成了 a*?。此时的匹配结果如下:
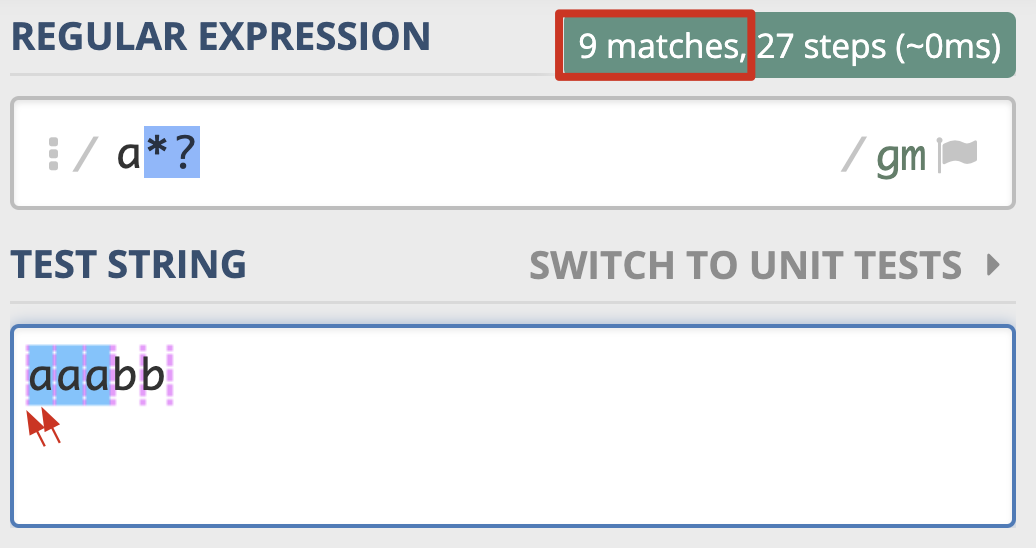
>>> import re
>>> re.findall(r'a*', 'aaabb') # 贪婪模式
['aaa', '', '', '']
>>> re.findall(r'a*?', 'aaabb') # 非贪婪模式
['', 'a', '', 'a', '', 'a', '', '', '']
这一次我们可以看到,这次匹配到的结果都是单个的a,就连每个a左边的空字符串也匹配上了。
到这里你可能就明白了,非贪婪模式会尽可能短地去匹配,我把这两者之间的区别写到了下面这张图中。
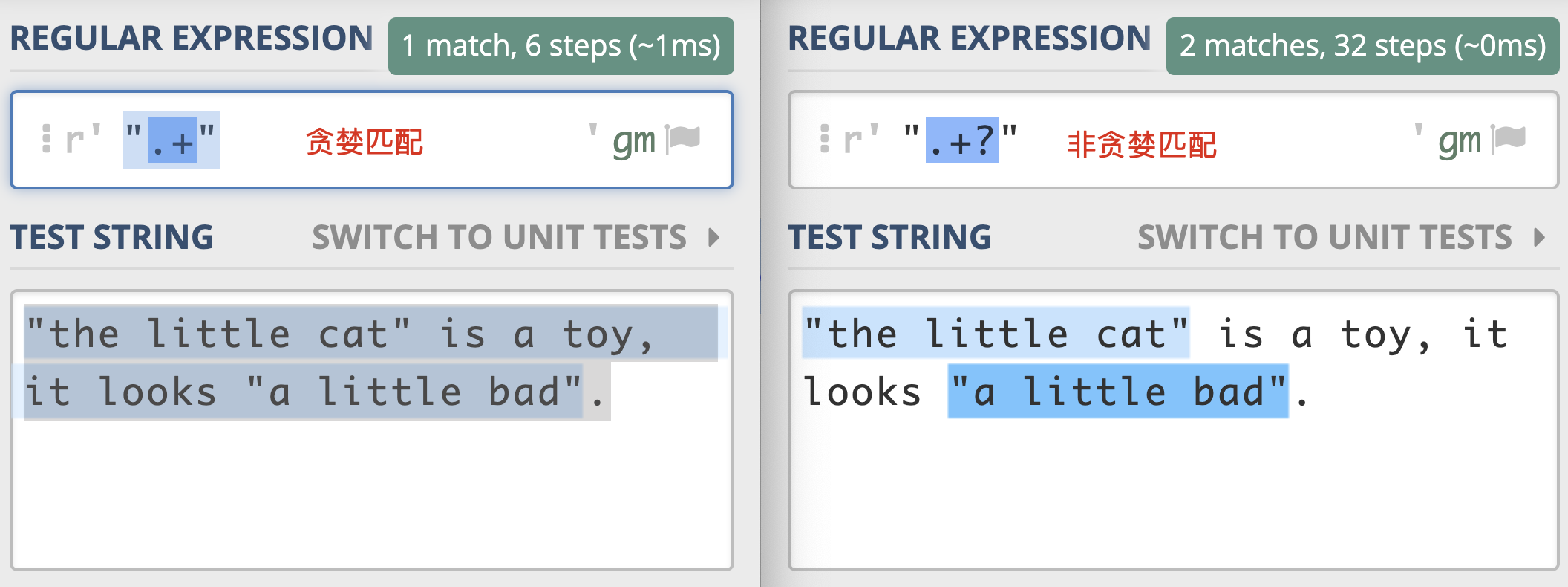
为了让你加深理解,我们再来看一个示例,这一次让我们查找一下引号中的单词。
从下面这个示例中,我们可以很容易看出两者对比上的差异。左右的文本是一样的,其中有两对双引号。不同之处在于,左边的示例中,不加问号时正则是贪婪匹配,匹配上了从第一个引号到最后一个引号之间的所有内容;而右边的图是非贪婪匹配,找到了符合要求的结果。
独占模式(Possessive)
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能。但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式,独占模式,它类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好。
你可能会问,那什么是回溯呢?我们来看一些例子,例如下面的正则:
regex = “xy{1,3}z”
text = “xyyz”
在匹配时,y{1,3}会尽可能长地去匹配,当匹配完 xyy 后,由于 y 要尽可能匹配最长,即三个,但字符串中后面是个 z 就会导致匹配不上,这时候正则就会 向前回溯,吐出当前字符 z,接着用正则中的 z 去匹配。

如果我们把这个正则改成非贪婪模式,如下:
regex = “xy{1,3}?z”
text = “xyyz”
由于 y{1,3}? 代表匹配1到3个 y,尽可能少地匹配。匹配上一个 y 之后,也就是在匹配上 text 中的 xy 后,正则会使用 z 和 text 中的 xy 后面的 y 比较,发现正则 z 和 y 不匹配,这时正则就会 向前回溯,重新查看 y 匹配两个的情况,匹配上正则中的 xyy,然后再用 z 去匹配 text 中的 z,匹配成功。

了解了回溯,我们再看下独占模式。
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号(+)。
regex = “xy{1,3}+yz”
text = “xyyz”

需要注意的是 Python 和 Go 的标准库目前都不支持独占模式,会报错,如下所示:
>>> import re
>>> re.findall(r'xy{1,3}+yz', 'xyyz')
error: multiple repeat at position 7
报错显示,加号(+)被认为是重复次数的元字符了。如果要测试这个功能,我们可以安装 PyPI 上的 regex 模块。
注意:需要先安装 regex 模块,pip install regex
>>> import regex
>>> regex.findall(r'xy{1,3}z', 'xyyz') # 贪婪模式
['xyyz']
>>> regex.findall(r'xy{1,3}+z', 'xyyz') # 独占模式
['xyyz']
>>> regex.findall(r'xy{1,2}+yz', 'xyyz') # 独占模式
[]
你也可以使用 Java 或 Perl 等其它语言来测试独占模式,查阅相关文档,看一下你所用的语言对独占模式的支持程度。
如果你用 a{1,3}+ab 去匹配 aaab 字符串,a{1,3}+ 会把前面三个 a 都用掉,并且不会回溯,这样字符串中内容只剩下 b 了,导致正则中加号后面的 a 匹配不到符合要求的内容,匹配失败。如果是贪婪模式 a{1,3} 或非贪婪模式 a{1,3}? 都可以匹配上。

这里我简单总结一下,独占模式性能比较好,可以节约匹配的时间和CPU资源,但有些情况下并不能满足需求,要想使用这个模式还要看具体需求(比如我们接下来要讲的案例),另外还得看你当前使用的语言或库的支持程度。
正则回溯引发的血案
学习到了这里,你是不是觉得自己对贪婪模式、非贪婪模式,以及独占模式比较了解了呢?其实在使用过程中稍不留神,就容易出问题,在网上可以看到不少因为回溯引起的线上问题。
这里我们挑选一个比较出名的,是阿里技术微信公众号上的发文。Lazada卖家中心店铺名检验规则比较复杂,名称中可以出现下面这些组合:
-
英文字母大小写;
-
数字;
-
越南文;
-
一些特殊字符,如“&”,“-”,“_”等。
负责开发的小伙伴在开发过程中使用了正则来实现店铺名称校验,如下所示:
^([A-Za-z0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
这个正则比较长,但很好理解,中括号里面代表多选一,我们简化一下,就成下面这样:
^([符合要求的组成1]|[符合要求的组成2])+$
脱字符(^)代表以这个正则开头,美元符号($)代表以正则结尾,我们后面会专门进行讲解。这里可以先理解成整个店铺名称要能匹配上正则,即起到验证的作用。
你需要留意的是,正则中有个加号(+),表示前面的内容出现一到多次,进行贪婪匹配,这样会导致大量回溯,占用大量CPU资源,引发线上问题,我们只需要将贪婪模式改成独占模式就可以解决这个问题。
我之前说过,要根据具体情况来选择合适的模式,在这个例子中,匹配不上时证明店铺名不合法,不需要进行回溯,因此我们可以使用独占模式,但要注意并不是说所有的场合都可以用独占模式解决,我们要首先保证正则能满足功能需求。
仔细再看一下 这个正则,你会发现 “组成1” 和 “组成2” 部分中,A-Za-z 英文字母在两个集合里面重复出现了,这会导致回溯后的重复判断。这里要强调一下,并不是说有回溯就会导致问题,你应该尽量减少回溯后的计算量,这些在后面的原理讲解中我们会进一步学习。
另外,腾讯云技术社区也有类似的技术文章,你如果感兴趣,可以点击这里 进行 查看。
说到这里,你是不是想起了课程开篇里面提到的一句话:
如果你有一个问题,你想到可以用正则来解决,那么你有两个问题了。
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.
所以一个小小的正则,有些时候也可能会把CPU拖垮,这也提醒我们在写正则的时候,一定要思考下回溯问题,避免使用低效的正则,引发线上问题。
最后总结
最后我来给你总结一下:正则中量词默认是贪婪匹配,如果想要进行非贪婪匹配需要在量词后面加上问号。贪婪和非贪婪匹配都可能会进行回溯,独占模式也是进行贪婪匹配,但不进行回溯,因此在一些场景下,可以提高匹配的效率,具体能不能用独占模式需要看使用的编程语言的类库的支持情况,以及独占模式能不能满足需求。
课后思考
最后,我们来做一个小练习吧。
有一篇英文文章,里面有很多单词,单词和单词之间是用空格隔开的,在引号里面的一到多个单词表示特殊含义,即引号里面的多个单词要看成一个单词。现在你需要提取出文章中所有的单词。我们可以假设文章中除了引号没有其它的标点符号,有什么方法可以解决这个问题呢?如果用正则来解决,你能不能写出一个正则,提取出文章中所有的单词呢(不要求结果去重)?
we found “the little cat” is in the hat, we like “the little cat”
其中 the little cat 需要看成一个单词
好了,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,并把文章分享给你的朋友或者同事,一起交流一下。
分组与引用:如何用正则实现更复杂的查找和替换操作?
你好,我是伟忠。今天我打算和你聊聊分组与引用。那什么场合下会用到分组呢?
假设我们现在要去查找15位或18位数字。根据前面学习的知识,使用量词可以表示出现次数,使用管道符号可以表示多个选择,你应该很快就能写出\d{15}|\d{18}。但经过测试,你会发现,这个正则并不能很好地完成任务,因为18位数字也会匹配上前15位,具体如下图所示。
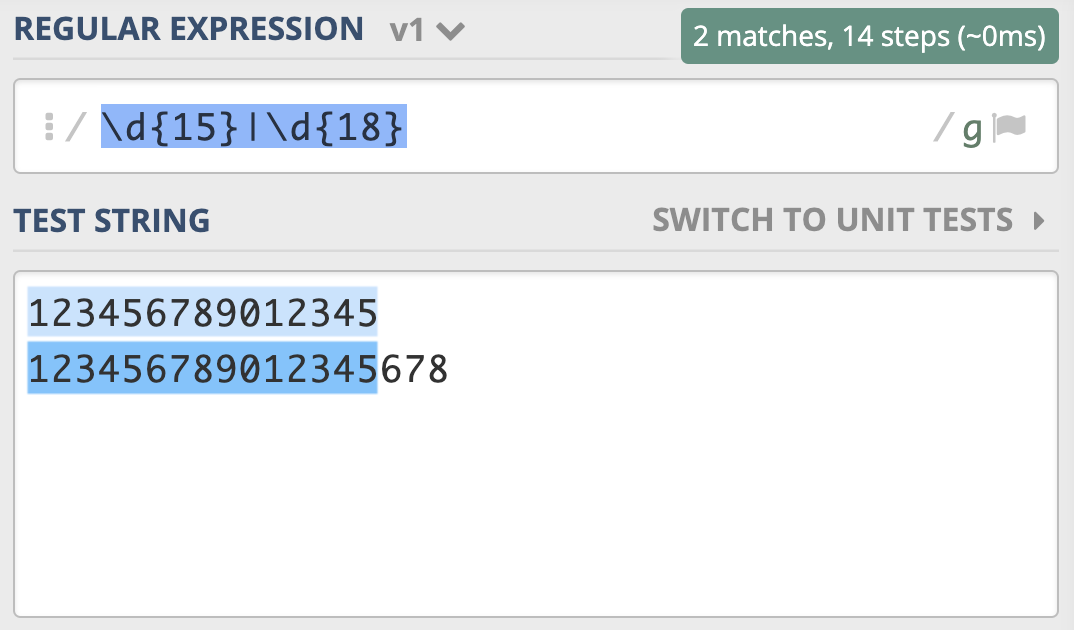
为了解决这个问题,你灵机一动,很快就想到了办法,就是把15和18调换顺序,即写成 \d{18}|\d{15}。你发现,这回符合要求了。
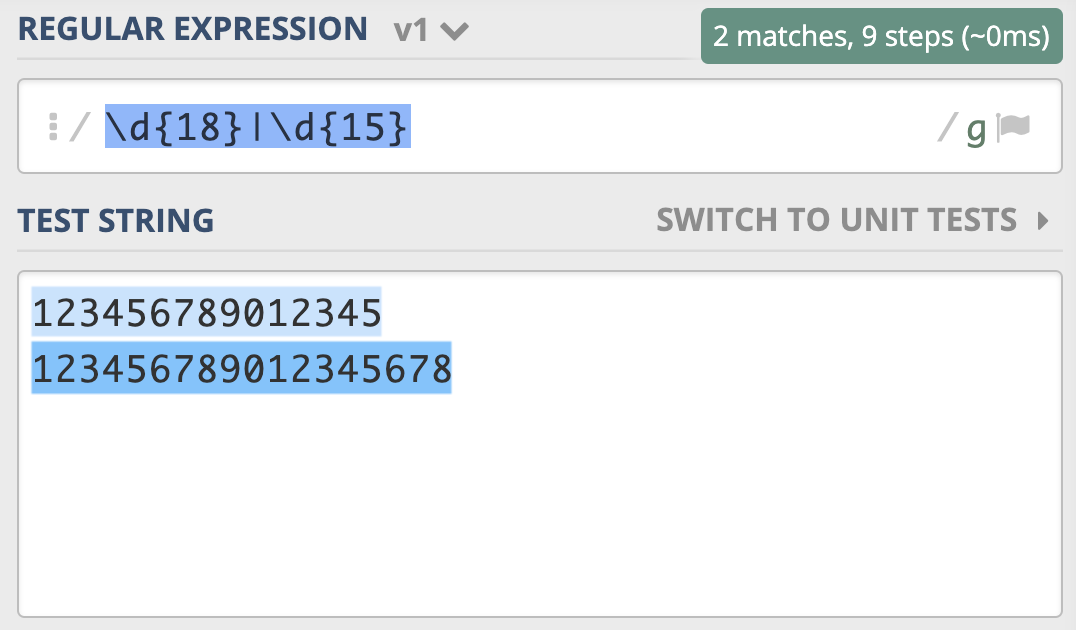
为什么会出现这种情况呢?因为在大多数正则实现中,多分支选择都是左边的优先。类似地,你可以使用 “北京市|北京” 来查找 “北京” 和 “北京市”。另外我们前面学习过,问号可以表示出现0次或1次,你发现可以使用“北京市?” 来实现来查找 “北京” 和 “北京市”。
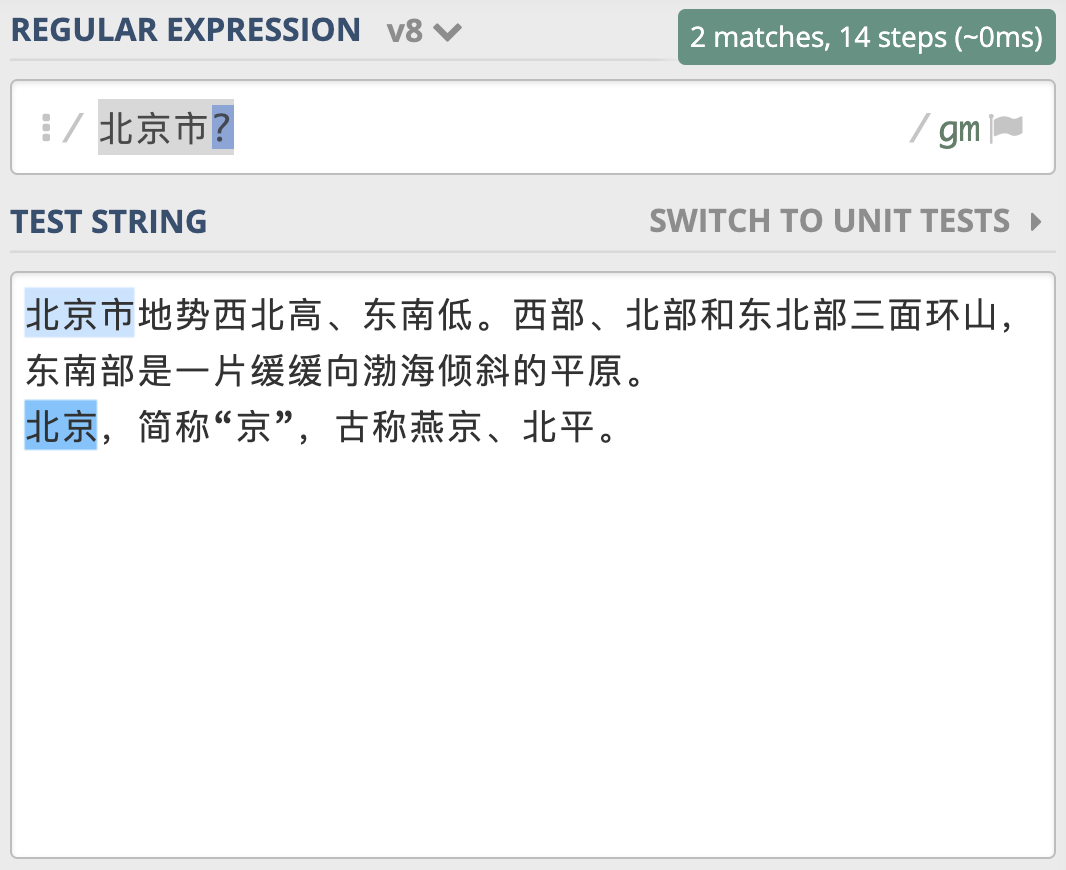
同样,针对15或18位数字这个问题,可以看成是15位数字,后面3位数据有或者没有,你应该很快写出了 \d{15}\d{3}? 。但这样写对不对呢?我们来看一下。
在上一节我们学习了量词后面加问号表示非贪婪,而我们现在想要的是 \d{3} 出现0次或1次。
示例一:
\d{15}\d{3}? 由于 \d{3} 表示三次,加问号非贪婪还是3次
示例二:
\d{15}(\d{3})? 在 \d{3} 整体后加问号,表示后面三位有或无
这时候,必须使用括号将来把表示“三个数字”的\d{3}这一部分括起来,也就是表示成\d{15}(\d{3})?这样。现在就比较清楚了:括号在正则中的功能就是用于分组。简单来理解就是,由多个元字符组成某个部分,应该被看成一个整体的时候,可以用括号括起来表示一个整体,这是括号的一个重要功能。其实用括号括起来还有另外一个作用,那就是“复用”,我接下来会给你讲讲这个作用。
分组与编号
括号在正则中可以用于分组,被括号括起来的部分“子表达式”会被保存成一个子组。
那分组和编号的规则是怎样的呢?其实很简单,用一句话来说就是,第几个括号就是第几个分组。这么说可能不好理解,我们来举一个例子看一下。
这里有个时间格式 2020-05-10 20:23:05。假设我们想要使用正则提取出里面的日期和时间。

我们可以写出如图所示的正则,将日期和时间都括号括起来。这个正则中一共有两个分组,日期是第 1 个,时间是第 2 个。
不保存子组
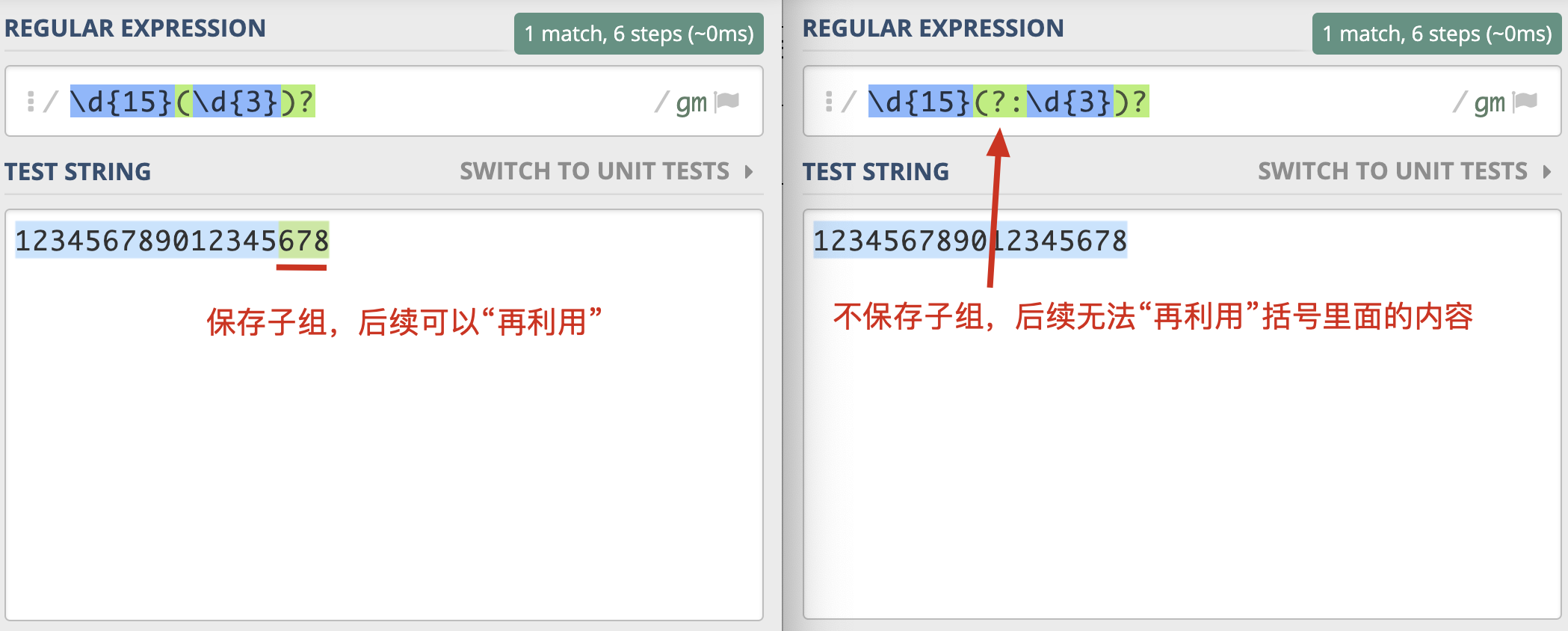
在括号里面的会保存成子组,但有些情况下,你可能只想用括号将某些部分看成一个整体,后续不用再用它,类似这种情况,在实际使用时,是没必要保存子组的。这时我们可以在括号里面使用 ?: 不保存子组。
如果正则中出现了括号,那么我们就认为,这个子表达式在后续可能会再次被引用,所以不保存子组可以提高正则的性能。除此之外呢,这么做还有一些好处,由于子组变少了,正则性能会更好,在子组计数时也更不容易出错。
那到底啥是不保存子组呢?我们可以理解成,括号只用于归组,把某个部分当成“单个元素”,不分配编号,后面不会再进行这部分的引用。

括号嵌套
前面讲完了子组和编号,但有些情况会比较复杂,比如在括号嵌套的情况里,我们要看某个括号里面的内容是第几个分组怎么办?不要担心,其实方法很简单,我们只需要数左括号(开括号)是第几个,就可以确定是第几个子组。
在阿里云简单日志系统中,我们可以使用正则来匹配一行日志的行首。假设时间格式是 2020-05-10 20:23:05 。

日期分组编号是 1,时间分组编号是 5,年月日对应的分组编号分别是 2,3,4,时分秒的分组编号分别是 6,7,8。
命名分组
前面我们讲了分组编号,但由于编号得数在第几个位置,后续如果发现正则有问题,改动了括号的个数,还可能导致编号发生变化,因此一些编程语言提供了命名分组(named grouping),这样和数字相比更容易辨识,不容易出错。命名分组的格式为 (?P<分组名>正则)。
比如在Django的路由中,命名分组示例如下:
url(r'^profile/(?P<username>\w+)/$', view_func)
需要注意的是,刚刚提到的方式命名分组和前面一样,给这个分组分配一个编号,不过你可以使用名称,不用编号,实际上命名分组的编号已经分配好了。不过命名分组并不是所有语言都支持的,在使用时,你需要查阅所用语言正则说明文档,如果支持,那你才可以使用。
分组引用
在知道了分组引用的编号 (number)后,大部分情况下,我们就可以使用 “反斜扛 + 编号”,即 \number 的方式来进行引用,而 JavaScript中是通过 $ 编号来引用,如 $ 1。
我给到了你一些在常见的编程语言中,分组查找和替换的引用方式:
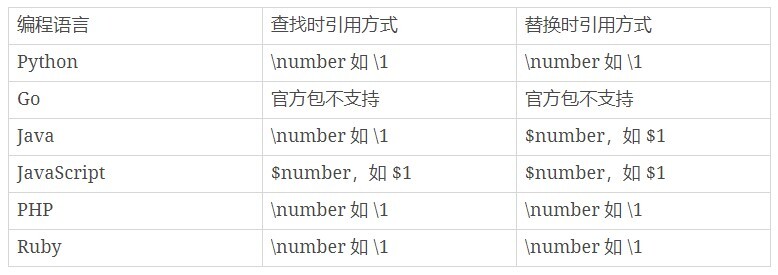
这些内容不要求你完全记住,只要有个印象就好,最关键的是要知道正则可以实现这样的功能,
需要用到的时候查一下相应的文档,就知道怎么用了。
分组引用在查找中使用
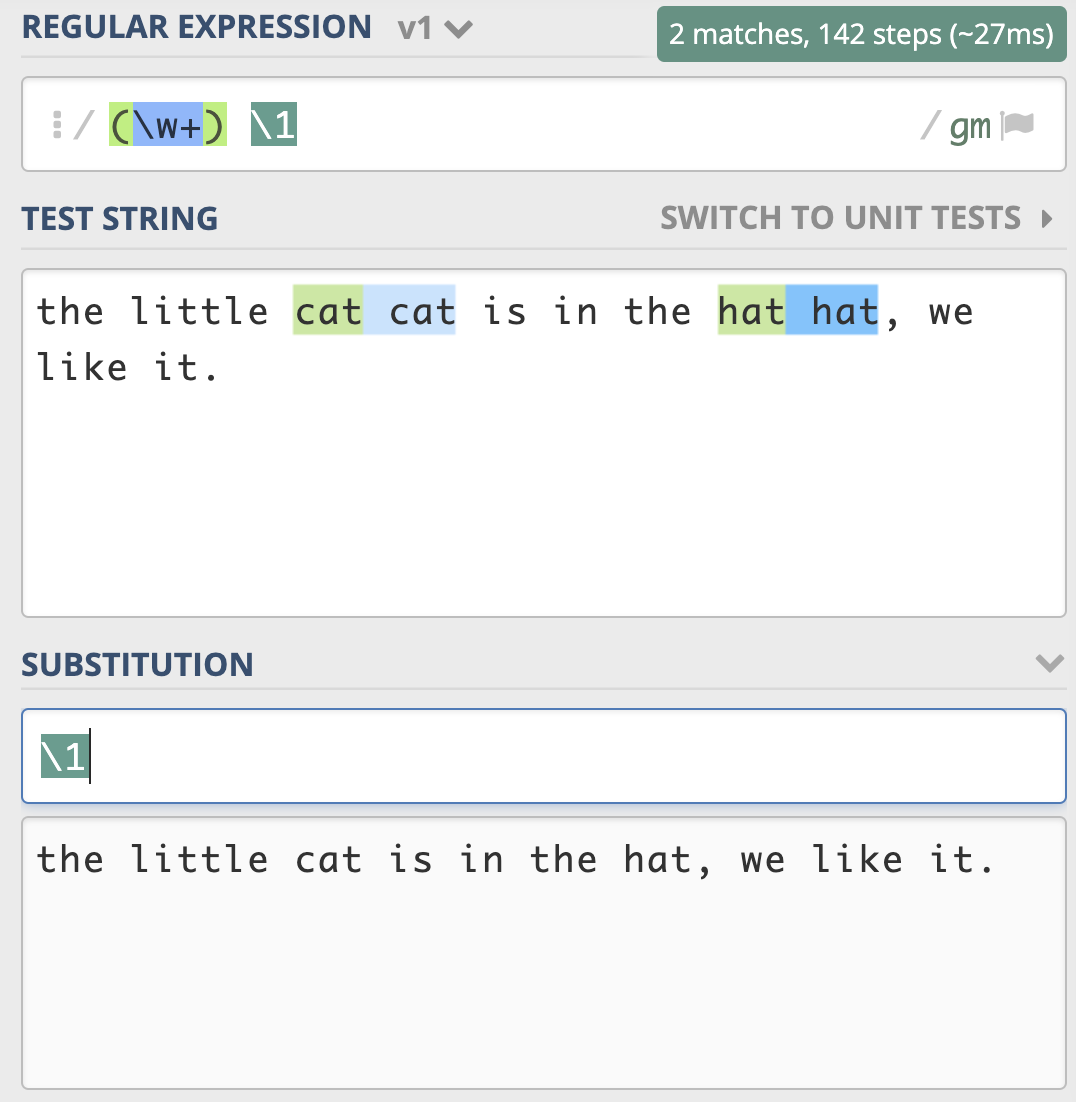
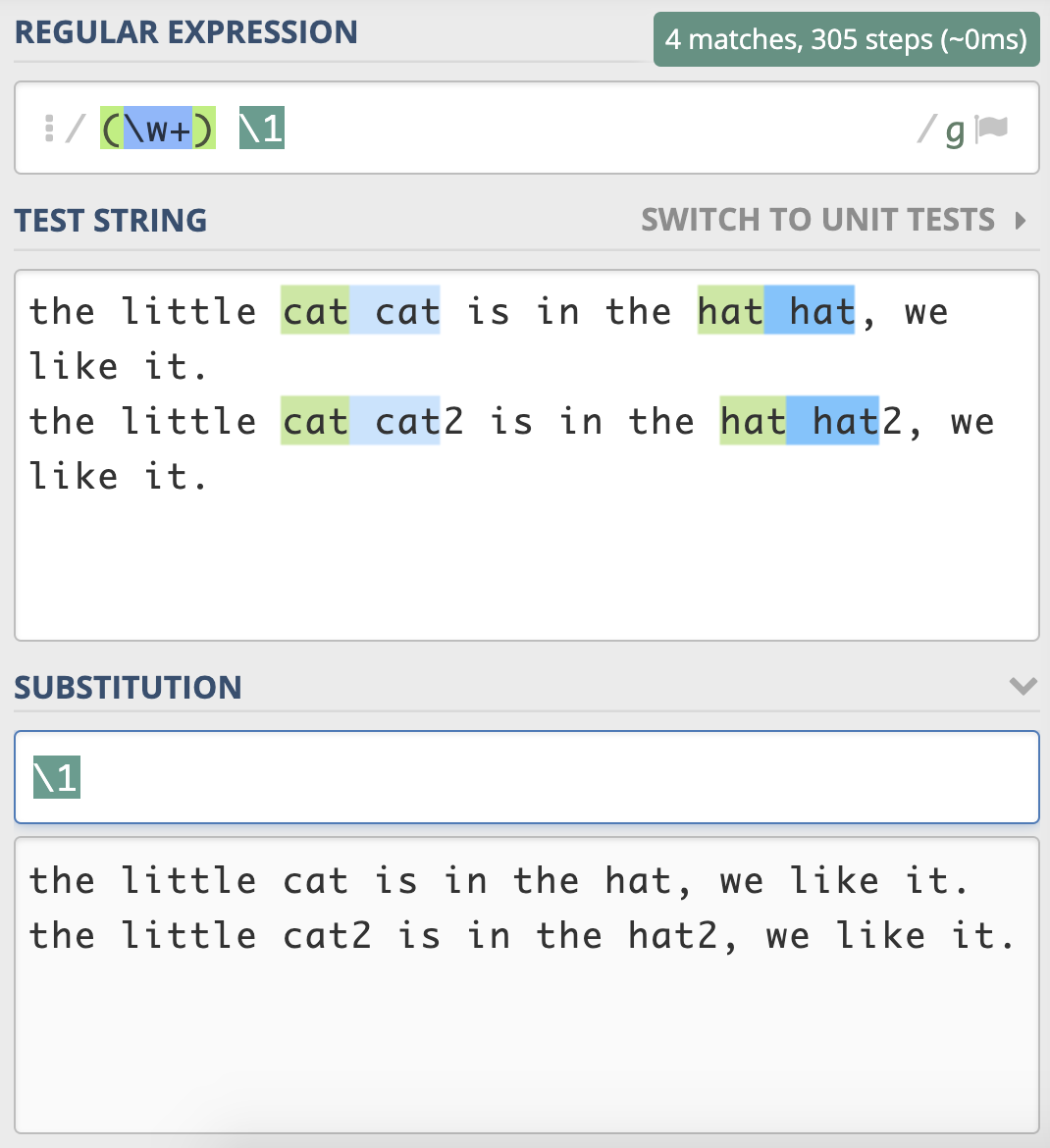
前面介绍了子组和引用的基本知识,现在我们来看下在正则查找时如何使用分组引用。比如我们要找重复出现的单词,我们使用正则可以很方便地使“前面出现的单词再次出现”,具体要怎么操作呢?我们可以使用 \w+ 来表示一个单词,针对刚刚的问题,我们就可以很容易写出 (\w+) \1 这个正则表达式了。
分组引用在替换中使用
和查找类似,我们可以使用反向引用,在得到的结果中,去拼出来我们想要的结果。还是使用刚刚日期时间的例子,我们可以很方便地将它替换成, 2020年05月10日这样的格式。
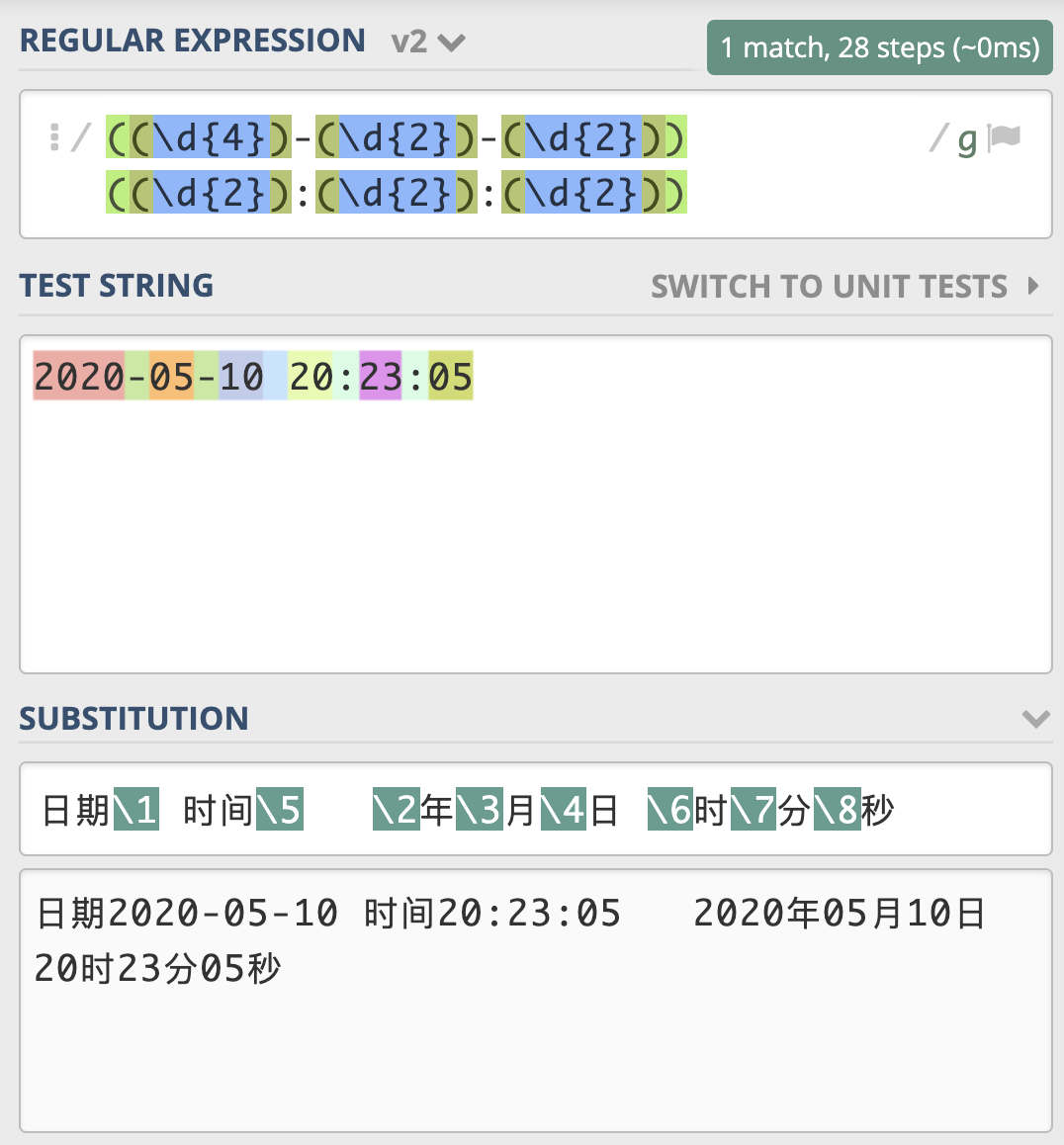
由于这个例子稍微复杂一些,这里我给出一个 示例链接 方便你学习,不知道学到这里,你有没有觉得子组和引用非常强大呢?
你可能很好奇,那在编程语言中如何实现这个功能呢?我下面以Python3为例,给出一个示例。
>>> import re
>>> test_str = "2020-05-10 20:23:05"
>>> regex = r"((\d{4})-(\d{2})-(\d{2})) ((\d{2}):(\d{2}):(\d{2}))"
>>> subst = r"日期\1 时间\5 \2年\3月\4日 \6时\7分\8秒"
>>> re.sub(regex, subst, test_str)
'日期2020-05-10 时间20:23:05 2020年05月10日 20时23分05秒'
在Python中 sub 函数用于正则的替换,使用起来也非常简单,和在网页上操作测试的几乎一样。
在文本编辑器中使用
Sublime Text 3 简介
接下来我用Sublime Text 3 来当例子,给你讲解一下正则查找和替换的使用方式。Sublime Text 3 是一个跨平台编辑器,非常小巧、强悍,虽然是一个收费软件,但可以永久试用,你自行可以下载安装。
当熟练使用编辑器之后,你会发现在很多工作里都可以使用它,不需要编写代码就可以完成。
下面我以文本编辑器 Sublime Text 3 为例,来讲解正则查找和替换的使用方式。首先,我们要使用的“查找”或“替换”功能,在菜单 Find 中可以找到。
下面是对编辑器查找-替换界面的图标简介,Find 输入栏第一个 .* 图标,表示开启或关闭正则支持。
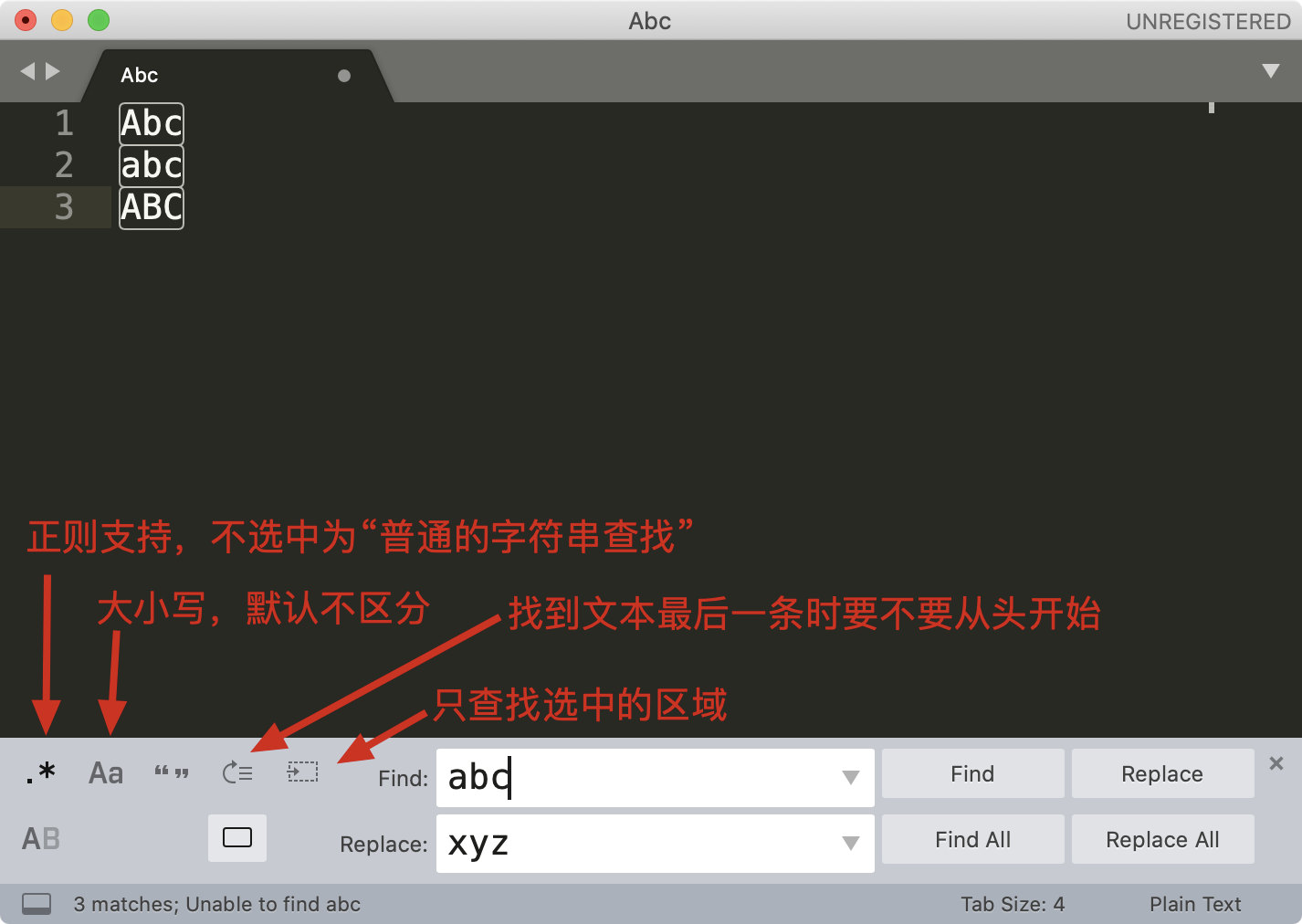
编辑器中进行正则查找
接下来,我们来演示用编辑器查找引号引起来的内容,课程中使用到的文本,建议你用 chrome 等浏览器等,打开极客时间网页版本 https://time.geekbang.org,点击右键查看源代码,把看到的代码复制到 Sublime Text 3 中。
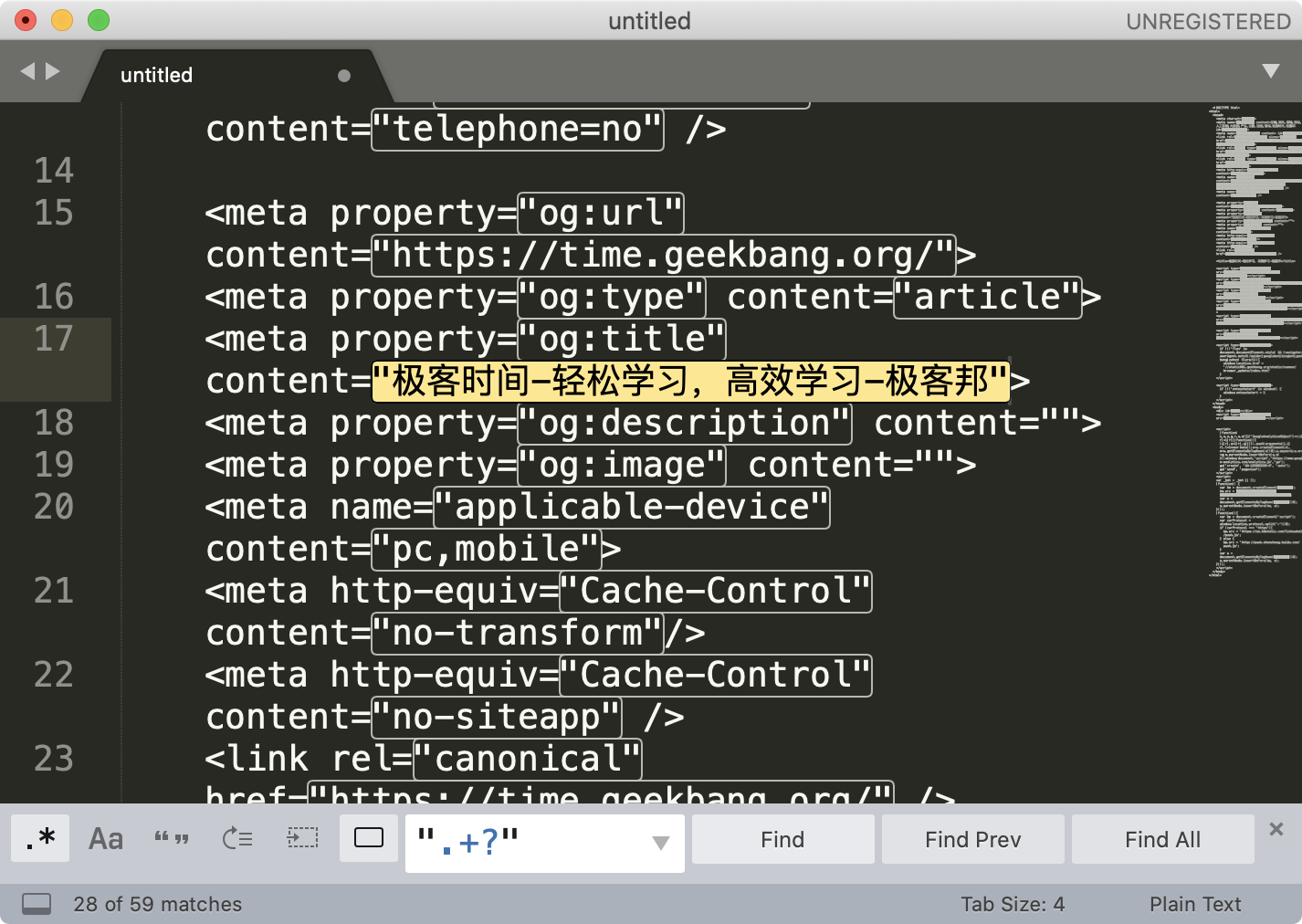
输入相应的正则,我们就可以看到查找的效果了。这里给一个小提示,如果你点击 Find All,然后进行剪切,具体操作可以在菜单中找到 Edit -> Cut,也可以使用快捷键操作。剪切之后,找一个空白的地方,粘贴就可以看到提取出的所有内容了。
我们可以使用正则进行资源链接提取,比如从一个图片网站的源代码中查找到图片链接,然后再使用下载工具批量下载这些图片。
在编辑器中进行正则替换
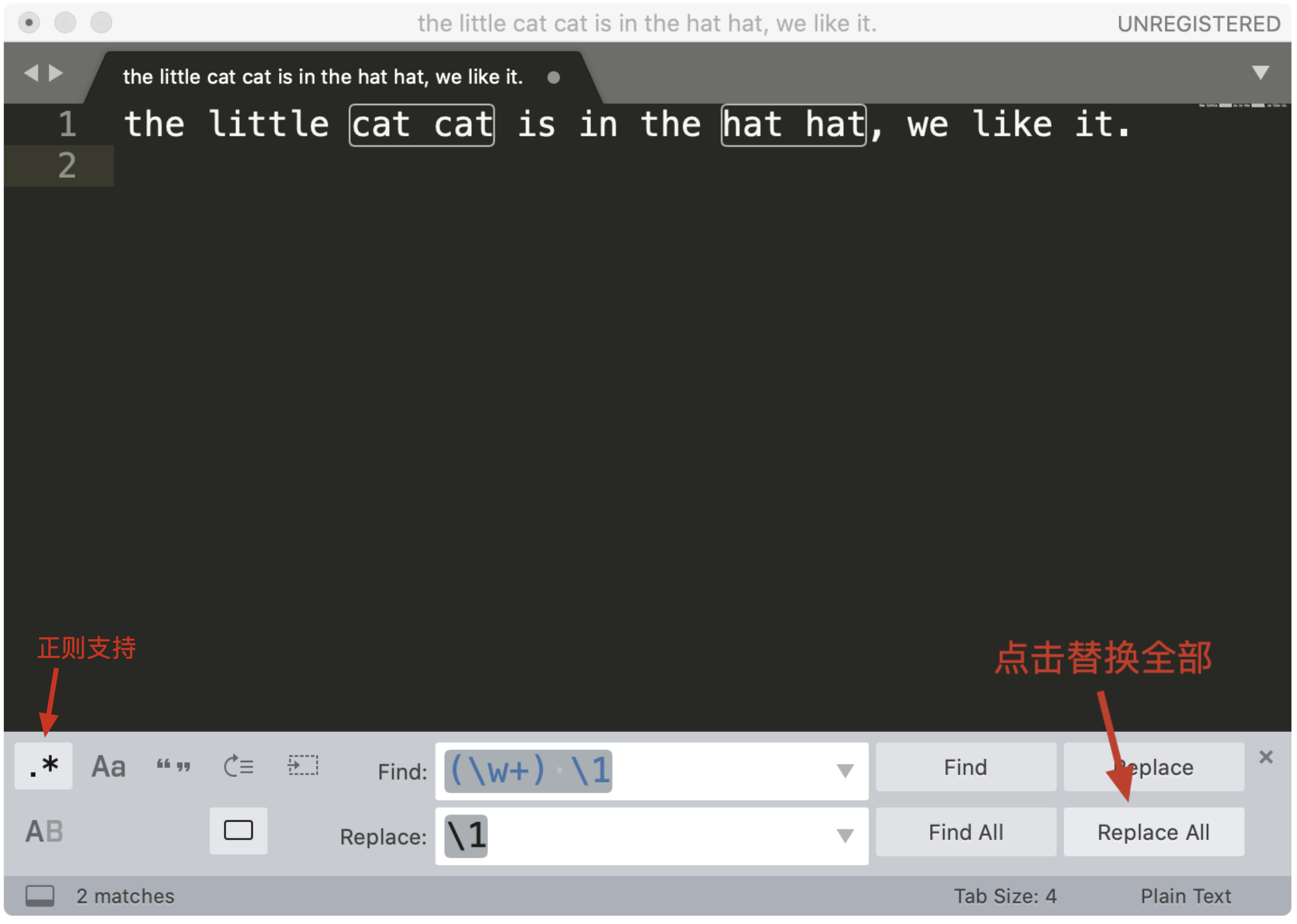
接着,我们再来看一下在编辑器中进行文本替换工作。你可以在编辑器中输入这些文本:
the little cat cat is in the hat hat, we like it.
如果我们要尝试从中查找连续重复出现两次的单词,我们可以用 \w+ 代表单词,利用我们刚刚学习的知识,相信你可以很快写出正则 (\w+) \1 。
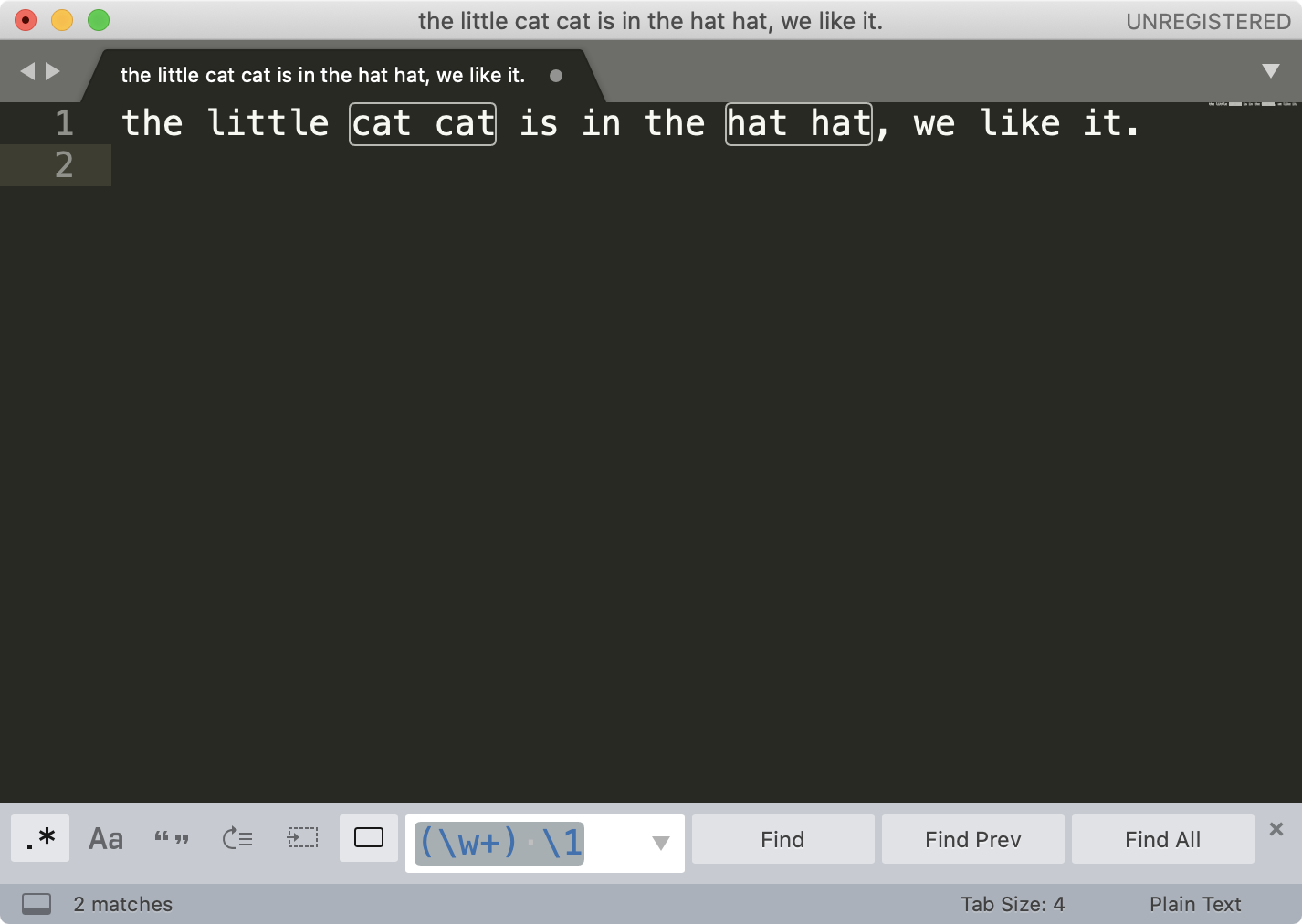
接着点击菜单中的 Find -> Replace,在替换栏中输入子组的引用 \1 ,然后点击 Replace All 就可以完成替换工作了。
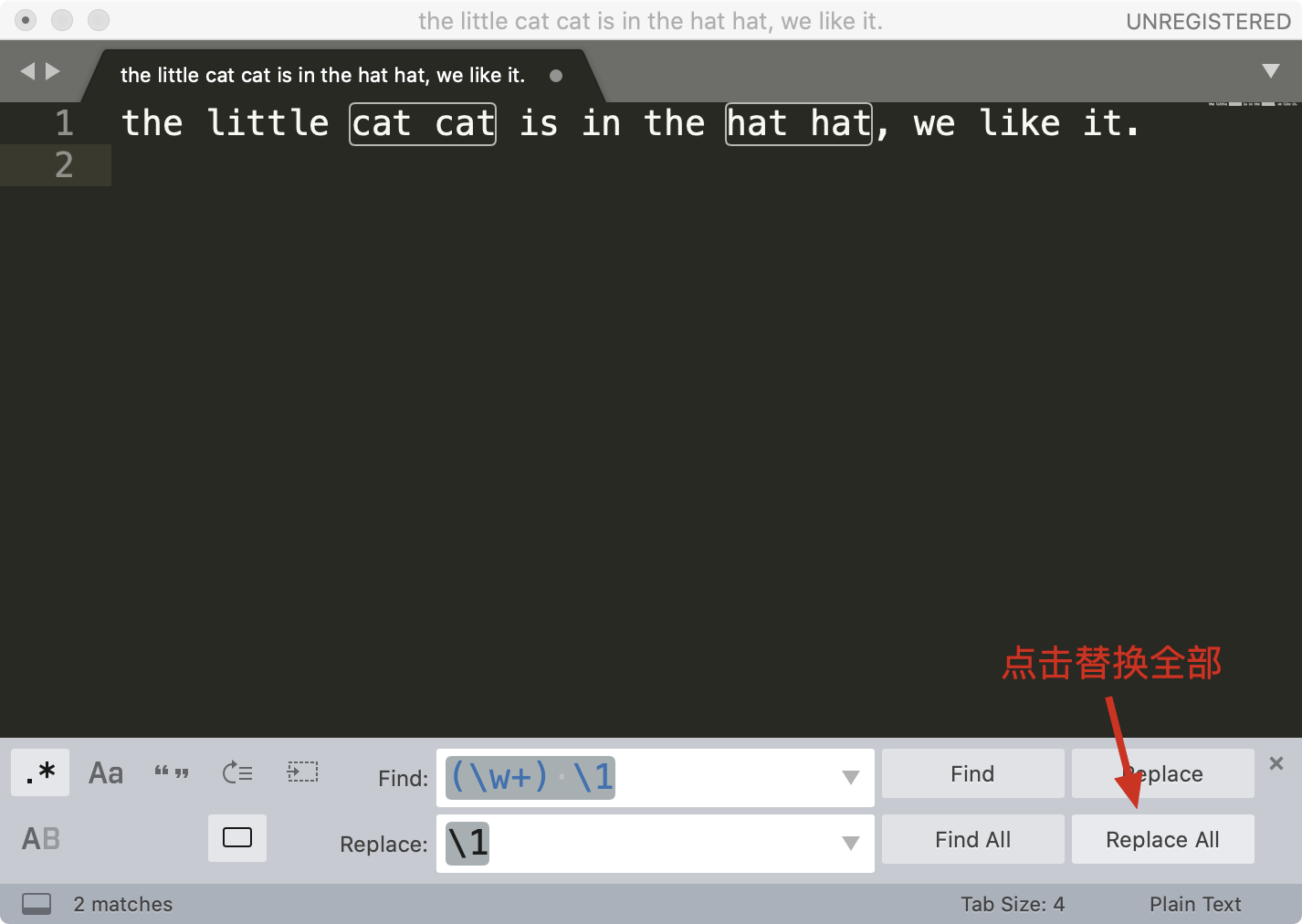
这样,通过少量的正则,我们就完成了文本的处理工作了。
几乎所有主流编辑器都是支持正则的,你可以在你喜欢的编辑器中尝试一下这个例子,在后面的工作中,也可以尝试使用它来完成一些复杂的文本查找和替换工作。
总结
好了,今天的内容讲完了,我来带你总结回顾一下。
今天我们学习到了正则中的分组和子组编号相关内容。括号可以将某部分括起来,看成一个整体,也可以保存成一个子组,在后续查找替换的时候使用。分组编号是指,在正则中第几个括号内就是第几个分组,而嵌套括号我们只要看左括号是第几个就可以了。如果不想将括号里面的内容保存成子组,可以在括号里面加上?:来解决。
搞懂了分组的内容,我们就可以利用分组引用,来实现将“原文本部分内容”,在查找或替换时进行再次利用,达到实现复杂文本的查找和替换工作。甚至在使用一些文本编辑器的时候,不写代码,我们就可以完成文本的查找替换处理工作,这往往可以节约很多开发时间。
课后思考
最后,我们来做一个小练习吧。有一篇英文文章,里面有一些单词连续出现了多次,我们认为连续出现多次的单词应该是一次,比如:
the little cat cat is in the hat hat hat, we like it.
其中 cat 和 hat 连接出现多次,要求处理后结果是
the little cat is in the hat, we like it.
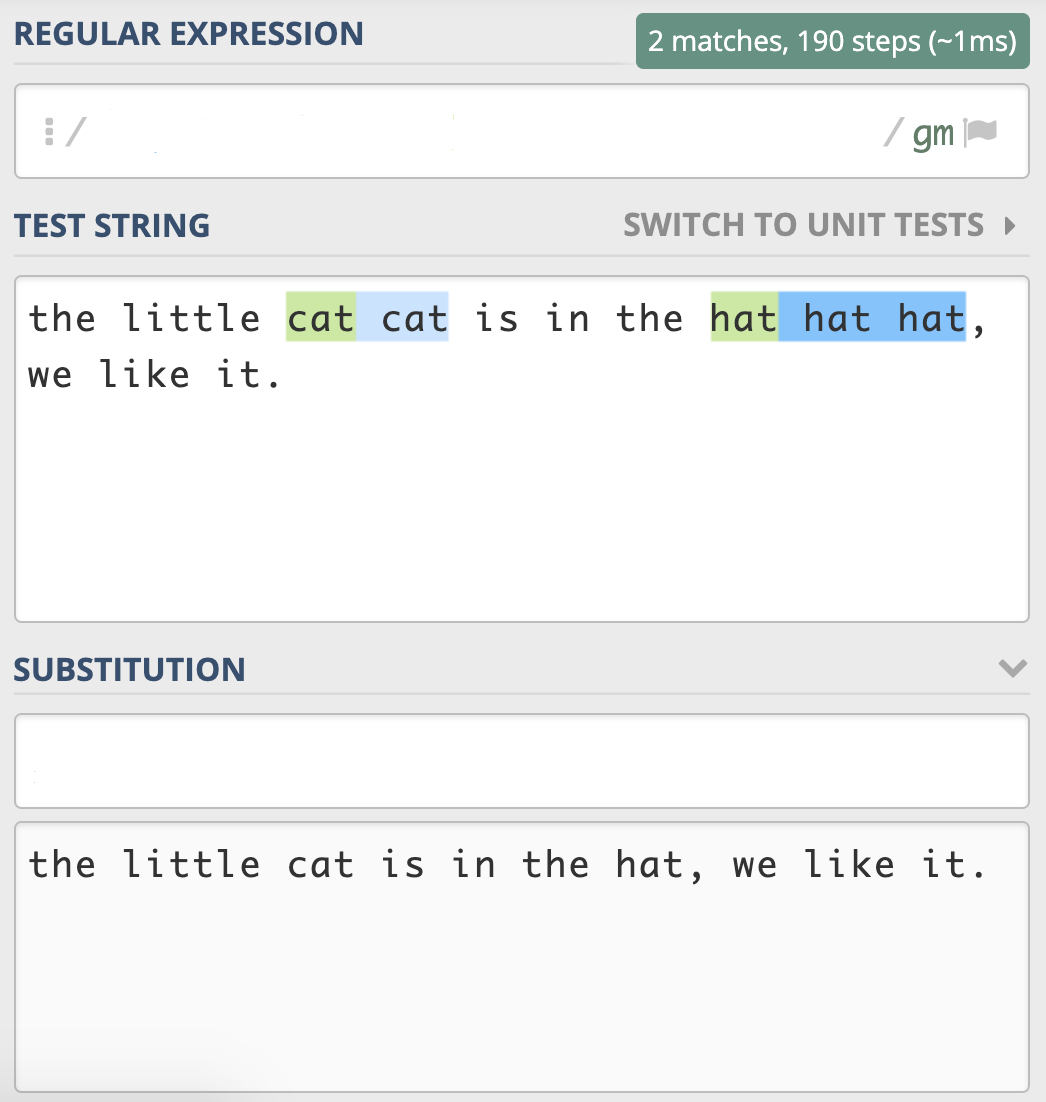
这个题目我给出了相应的地址 https://regex101.com/r/2RVPTJ/3,你可以直接在网页上进行测试,写入相应的 “正则查找部分” 和 “正则替换部分”,让结果符合预期。多动手练习,你才能更好地掌握学习的内容。
好,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论。也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。
匹配模式:一次性掌握正则中常见的4种匹配模式
你好,我是涂伟忠。今天我们一起来学习正则中的匹配模式(Match Mode)。
所谓匹配模式,指的是正则中一些 改变元字符匹配行为 的方式,比如匹配时不区分英文字母大小写。常见的匹配模式有4种,分别是不区分大小写模式、点号通配模式、多行模式和注释模式。我们今天主要来讲一下这4种模式。
需要注意的是,这里的“模式”对应的是英文中的mode,而不是pattern。有些地方会把正则表达式pattern也翻译成模式,你在网上看到的技术文章中讲的正则模式,有可能指的是正则表达式本身,这一点你需要注意区别。
不区分大小写模式(Case-Insensitive)
首先,我们来看一下不区分大小写模式。它有什么用呢?学一个知识的时候,我一般喜欢先从它的应用出发,这样有时候更能激发我学习的兴趣,也更容易看到学习成果。
下面我来举个例子说明一下。在进行文本匹配时,我们要关心单词本身的意义。比如要查找单词cat,我们并不需要关心单词是CAT、Cat,还是cat。根据之前我们学到的知识,你可能会把正则写成这样: [Cc][Aa][Tt],这样写虽然可以达到目的,但不够直观,如果单词比较长,写起来容易出错,阅读起来也比较困难。
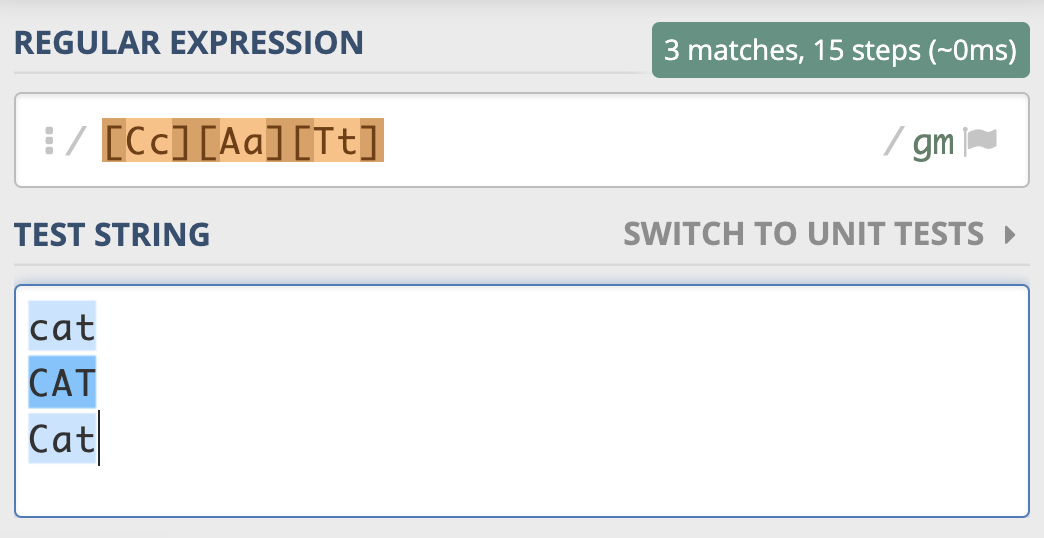
那么有没有更好的办法来实现这个需求呢?这时候不区分大小写模式就派上用场了。
我们前面说了,不区分大小写是匹配模式的一种。当我们把 模式修饰符 放在整个正则前面时,就表示整个正则表达式都是不区分大小写的。模式修饰符是通过 (?模式标识) 的方式来表示的。 我们只需要把模式修饰符放在对应的正则前,就可以使用指定的模式了。在不区分大小写模式中,由于不分大小写的英文是Case- I nsensitive,那么对应的模式标识就是 I 的小写字母 i,所以不区分大小写的 cat 就可以写成 (?i) cat。
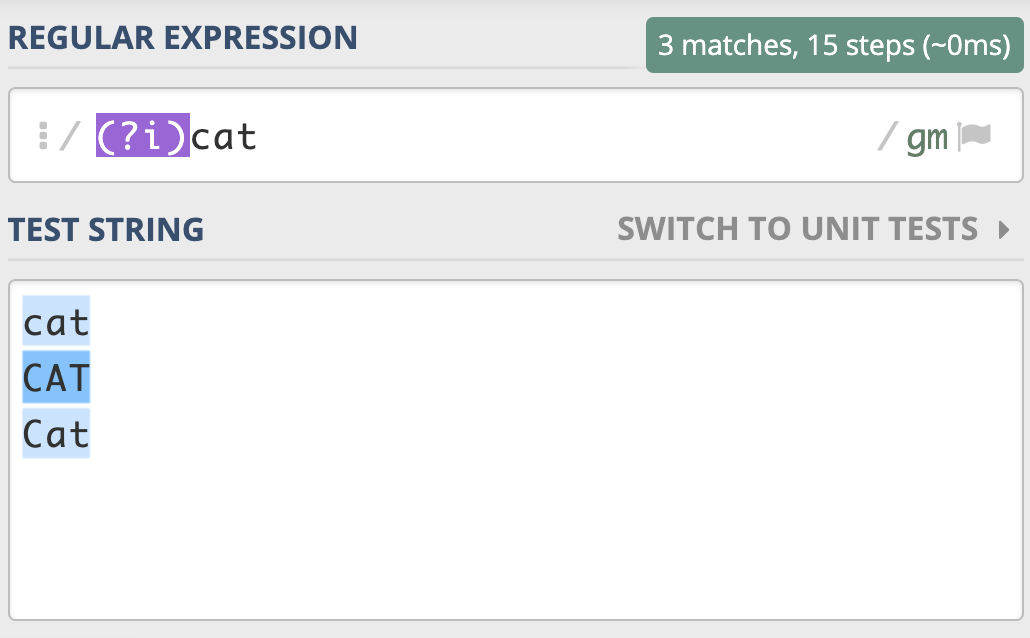
你看,和 [Cc][Aa][Tt] 相比,这样是不是清晰简洁了很多呢?
我们也可以用它来尝试匹配两个连续出现的 cat,如下图所示,你会发现,即便是第一个 cat 和第二个 cat 大小写不一致,也可以匹配上。
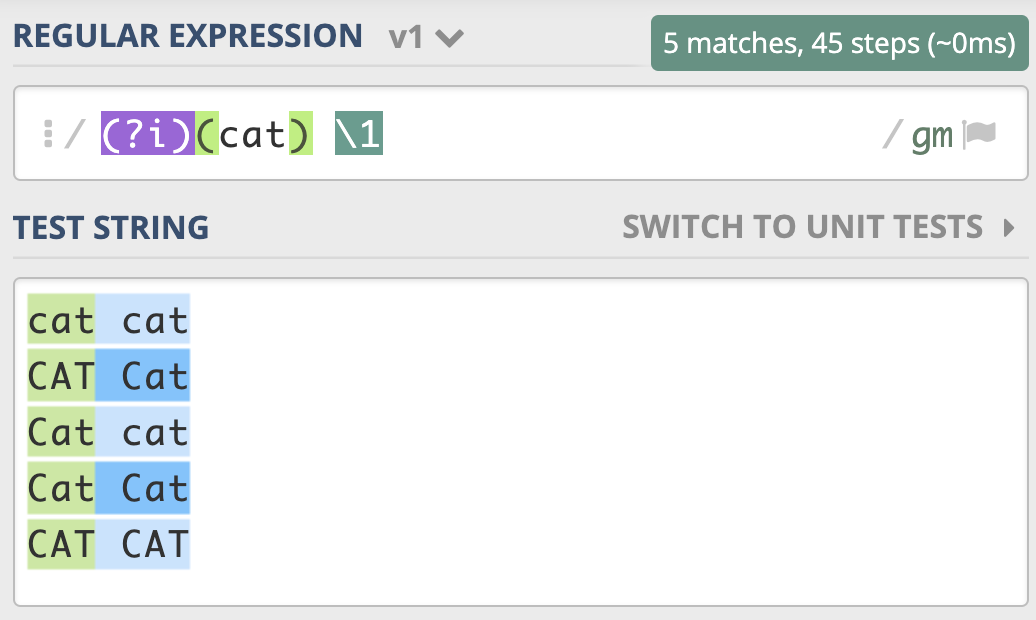
我给到了你一个测试链接,你可以在这里试试不区分大小写模式:
https://regex101.com/r/x1lg4P/1。
如果我们想要前面匹配上的结果,和第二次重复时的大小写一致,那该怎么做呢?我们只需要用括号把 修饰符和正则cat部分 括起来,加括号相当于作用范围的限定,让不区分大小写只作用于这个括号里的内容。同样的,我在 这里 给你放了一个测试链接,你可以自己看一下。
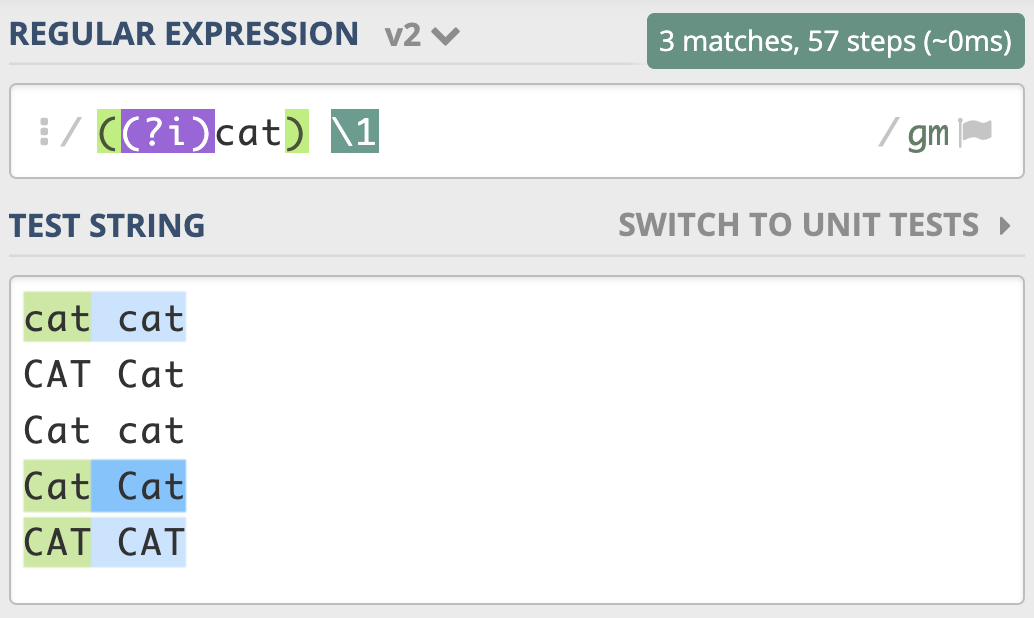
需要注意的是,这里正则写成了 ((?i)cat) \1,而不是((?i)(cat)) \1。也就是说,我们给修饰符和cat整体加了个括号,而原来 cat 部分的括号去掉了。如果 cat 保留原来的括号,即 ((?i)(cat)) \1,这样正则中就会有两个子组,虽然结果也是对的,但这其实没必要。在上一讲里我们已经讲解了相关的内容,如果忘记了你可以回去复习一下。
到这里,我们再进阶一下。如果用正则匹配,实现部分区分大小写,另一部分不区分大小写,这该如何操作呢?就比如说我现在想要,the cat 中的 the 不区分大小写,cat 区分大小写。
通过上面的学习,你应该能很快写出相应的正则,也就是 ( (?i) the) cat。实现的效果如下:
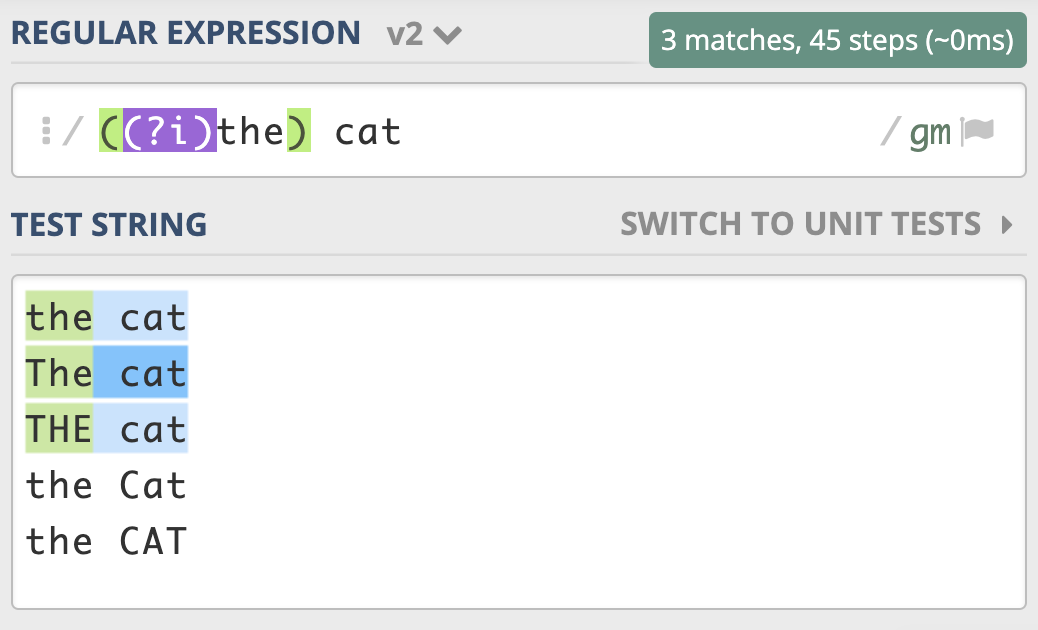
我把部分区分大小写,部分不区分大小写的测试链接放在 这里,你可以看一下。
有一点需要你注意一下,上面讲到的通过 修饰符指定匹配模式 的方式,在大部分编程语言中都是可以直接使用的,但在 JS 中我们需要使用 /regex/ i 来指定匹配模式。在编程语言中通常会提供一些预定义的常量,来进行匹配模式的指定。比如 Python 中可以使用 re.IGNORECASE 或 re.I ,来传入正则函数中来表示不区分大小写。我下面给出了你一个示例,你可以看一下。
>>> import re
>>> re.findall(r"cat", "CAT Cat cat", re.IGNORECASE)
['CAT', 'Cat', 'cat']
到这里我简单总结一下不区分大小写模式的要点:
- 不区分大小写模式的指定方式,使用模式修饰符 (?i);
- 修饰符如果在括号内,作用范围是这个括号内的正则,而不是整个正则;
- 使用编程语言时可以使用预定义好的常量来指定匹配模式。
点号通配模式(Dot All)
在基础篇的第一讲里,我为你讲解了元字符相关的知识,你还记得英文的点(.)有什么用吗?它可以匹配上任何符号,但不能匹配换行。当我们需要匹配真正的“任意”符号的时候,可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等。

但是这么写不够简洁自然,所以正则中提供了一种模式,让英文的点(.)可以匹配上包括换行的任何字符。
这个模式就是 点号通配模式,有很多地方把它称作单行匹配模式,但这么说容易造成误解,毕竟它与多行匹配模式没有联系,因此在课程中我们统一用更容易理解的“点号通配模式”。
单行的英文表示是 S ingle Line,单行模式对应的修饰符是 (?s),我还是选择用the cat来给你举一个点号通配模式的例子。如下图所示:
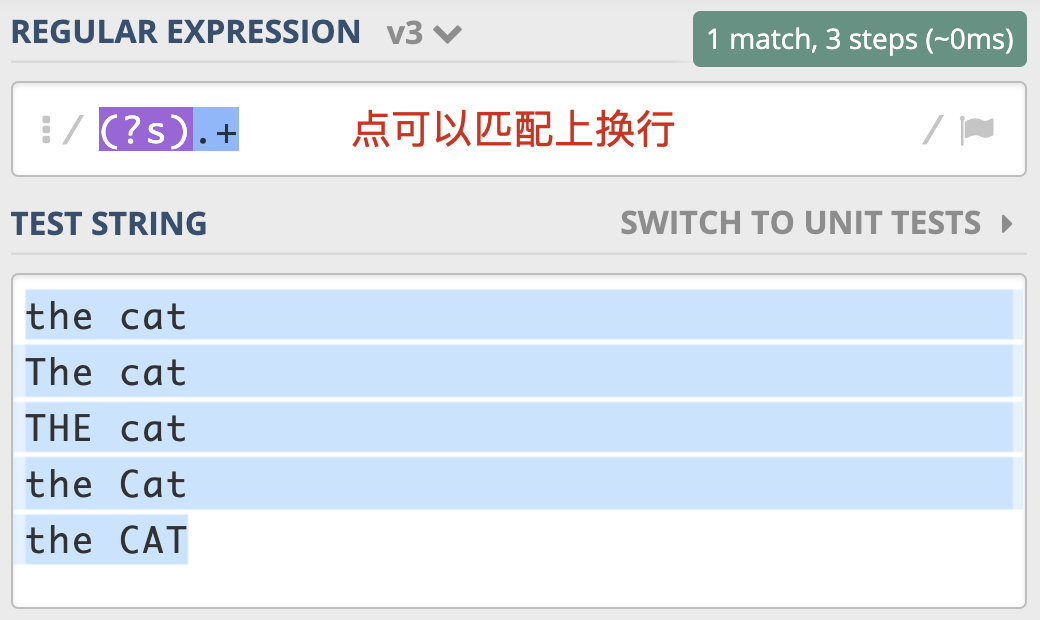
需要注意的是,JavaScript不支持此模式,那么我们就可以使用前面说的[\s\S]等方式替代。在Ruby中则是用Multiline,来表示点号通配模式(单行匹配模式),我猜测设计者的意图是把点(.)号理解成“能匹配多行”。
多行匹配模式(Multiline)
讲完了点号通配模式,我们再来看看多行匹配模式。通常情况下, ^ 匹配整个字符串的开头,$ 匹配整个字符串的结尾。多行匹配模式改变的就是 ^ 和 $ 的匹配行为。
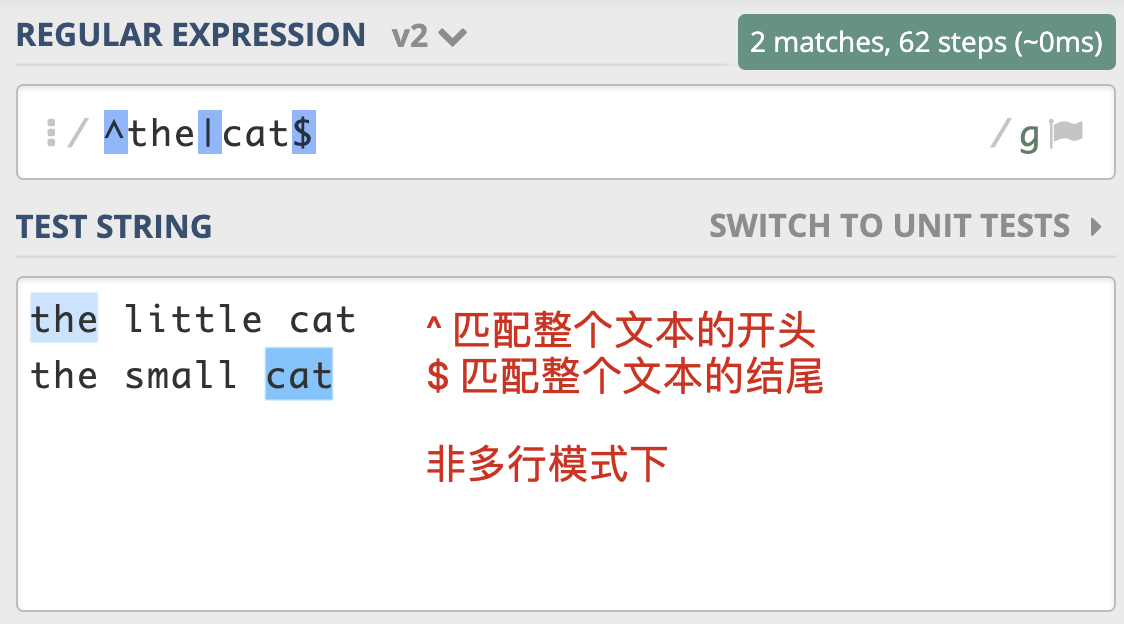
多行模式的作用在于,使 ^ 和 $ 能匹配上 每行 的开头或结尾,我们可以使用模式修饰符号 (?m) 来指定这个模式。
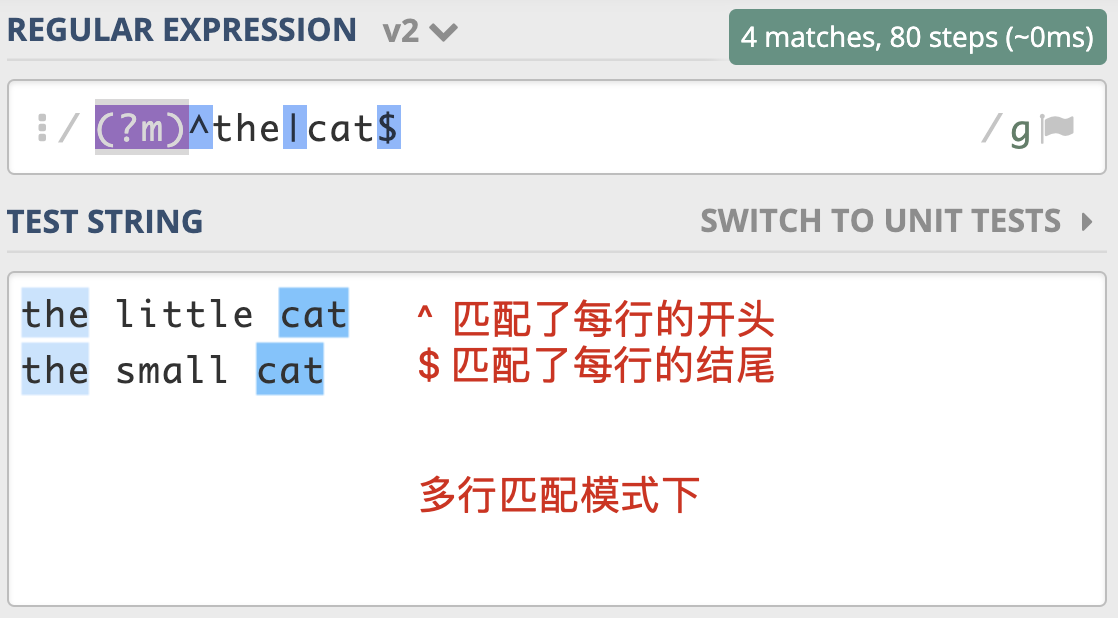
这个模式有什么用呢?在处理日志时,如果日志以时间开头,有一些日志打印了堆栈信息,占用了多行,我们就可以使用多行匹配模式,在日志中匹配到以时间开头的每一行日志。
值得一提的是,正则中还有 \A 和 \z(Python中是 \Z) 这两个元字符容易混淆,\A 仅匹配整个字符串的开始,\z 仅匹配整个字符串的结束,在多行匹配模式下,它们的匹配行为不会改变,如果只想匹配整个字符串,而不是匹配每一行,用这个更严谨一些。
注释模式(Comment)
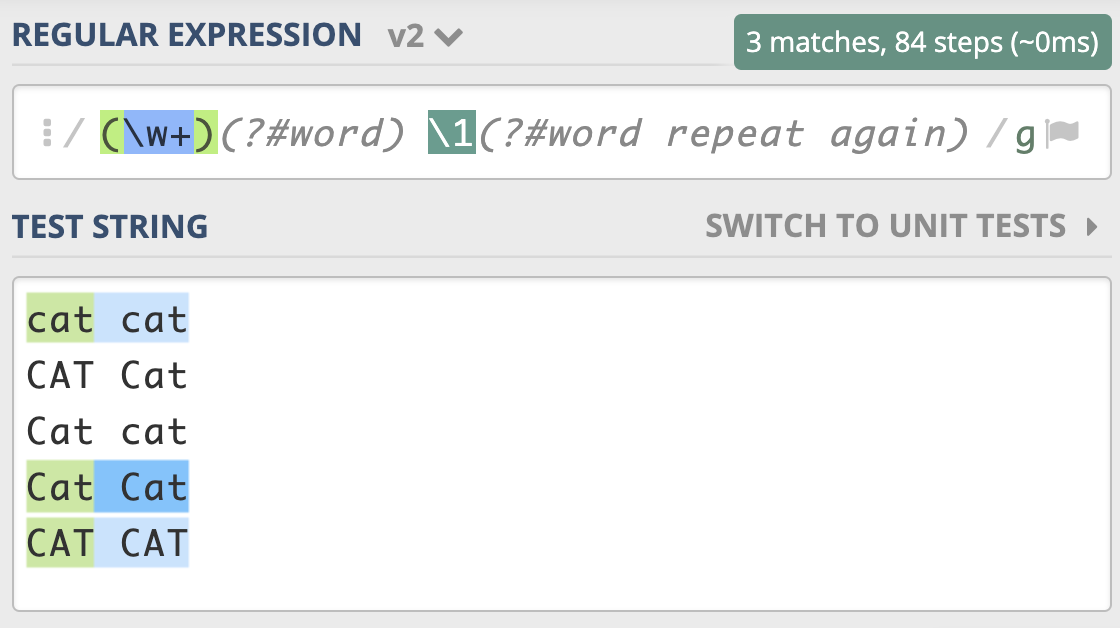
在实际工作中,正则可能会很复杂,这就导致编写、阅读和维护正则都会很困难。我们在写代码的时候,通常会在一些关键的地方加上注释,让代码更易于理解。很多语言也支持在正则中添加注释,让正则更容易阅读和维护,这就是正则的注释模式。正则中注释模式是使用(?#comment) 来表示。
比如我们可以把单词重复出现一次的正则 (\w+) \1 写成下面这样,这样的话,就算不是很懂正则的人也可以通过注释看懂正则的意思。
(\w+)(?#word) \1(?#word repeat again)
在很多编程语言中也提供了x模式来书写正则,也可以起到注释的作用。我用Python3给你举了一个例子,你可以参考一下。
import re
regex = r'''(?mx) # 使用多行模式和x模式
^ # 开头
(\d{4}) # 年
(\d{2}) # 月
$ # 结尾
'''
re.findall(regex, '202006\n202007')
# 输出结果 [('2020', '06'), ('2020', '07')]
需要注意的是在x模式下,所有的换行和空格都会被忽略。为了换行和空格的正确使用,我们可以通过把空格放入字符组中,或将空格转义来解决换行和空格的忽略问题。我下面给了你一个示例,你可以看看。
regex = r'''(?mx)
^ # 开头
(\d{4}) # 年
[ ] # 空格
(\d{2}) # 月
$ # 结尾
'''
re.findall(regex, '2020 06\n2020 07')
# 输出结果 [('2020', '06'), ('2020', '07')]
总结
最后,我来给你总结一下,正则中常见的四种匹配模式,分别是:不区分大小写、点号通配模式、多行模式和注释模式。
- 不区分大小写模式,它可以让整个正则或正则中某一部分进行不区分大小写的匹配。
- 点号通配模式也叫单行匹配,改变的是点号的匹配行为,让其可以匹配任何字符,包括换行。
- 多行匹配说的是 ^ 和 $ 的匹配行为,让其可以匹配上每行的开头或结尾。
- 注释模式则可以在正则中添加注释,让正则变得更容易阅读和维护。
思考题
最后,我们来做一个小练习吧。HTML标签是不区分大小写的,比如我们要提取网页中的head 标签中的内容,用正则如何实现呢?
你可以动手试一试,用文本编辑器或你熟悉的编程语言来实现,经过不断练习你才能更好地掌握学习的内容。
今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论。也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。
断言:如何用断言更好地实现替换重复出现的单词?
你好,我是伟忠。今天我来和你聊聊正则断言(Assertion)。
什么是断言呢?简单来说,断言是指对匹配到的文本位置有要求。这么说你可能还是没理解,我通过一些例子来给你讲解。你应该知道 \d{11} 能匹配上11位数字,但这11位数字可能是18位身份证号中的一部分。再比如,去查找一个单词,我们要查找 tom,但其它的单词,比如 tomorrow 中也包含了tom。
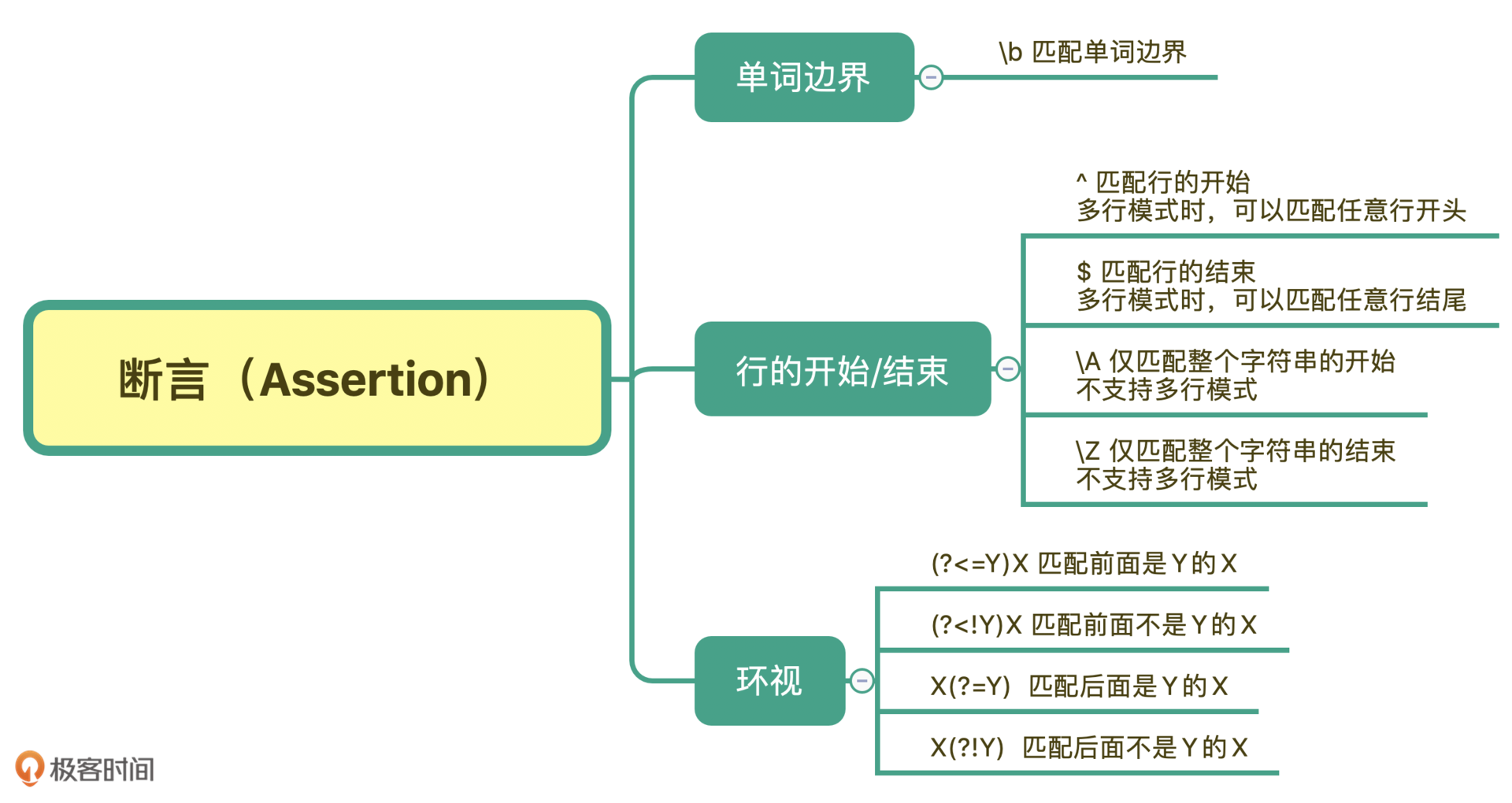
也就是说,在有些情况下,我们对要匹配的文本的位置也有一定的要求。为了解决这个问题,正则中提供了一些结构,只用于匹配位置,而不是文本内容本身,这种结构就是断言。常见的断言有三种:单词边界、行的开始或结束以及环视。
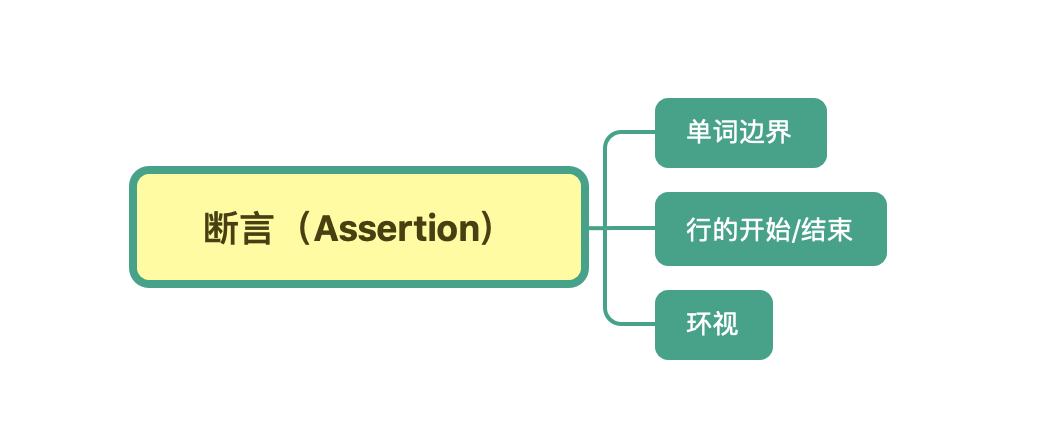
单词边界(Word Boundary)
在讲单词边界具体怎么使用前,我们先来看一下例子。我们想要把下面文本中的 tom 替换成 jerry。注意一下,在文本中出现了 tomorrow 这个单词,tomorrow也是以 tom 开头的。
tom asked me if I would go fishing with him tomorrow.
中文翻译:Tom问我明天能否和他一同去钓鱼。
利用前面学到的知识,我们如果直接替换,会出现下面这种结果。
替换前:tom asked me if I would go fishing with him tomorrow.
替换后:jerry asked me if I would go fishing with him jerryorrow.
这显然是错误的,因为明天这个英语单词里面的 tom 也被替换了。
那正则是如何解决这个问题的呢?单词的组成一般可以用元字符 \w+ 来表示, \w 包括了大小写字母、下划线和数字(即 [A-Za-z0-9_])。那如果我们能找出单词的边界,也就是当出现了 \w表示的范围以外 的字符,比如引号、空格、标点、换行等这些符号,我们就可以在正则中使用\b 来表示单词的边界。 \b中的b可以理解为是边界(Boundary)这个单词的首字母。

根据刚刚学到的内容,在准确匹配单词时,我们使用 \b\w+\b 就可以实现了。
下面我们以 Python3 语言为例子,为你实现上面提到的 “tom 替换成 jerry”:
>>> import re
>>> test_str = "tom asked me if I would go fishing with him tomorrow."
>>> re.sub(r'\btom\b', 'jerry', test_str)
'jerry asked me if I would go fishing with him tomorrow.'
建议你自己也动手尝试一下,利用我们前面说的方法,在sublime text 3编辑器中实现一下这个替换操作,这样你才可以记得更牢。
行的开始或结束
和单词的边界类似,在正则中还有文本每行的开始和结束,如果我们要求匹配的内容要出现在一行文本开头或结尾,就可以使用 ^ 和 $ 来进行位置界定。
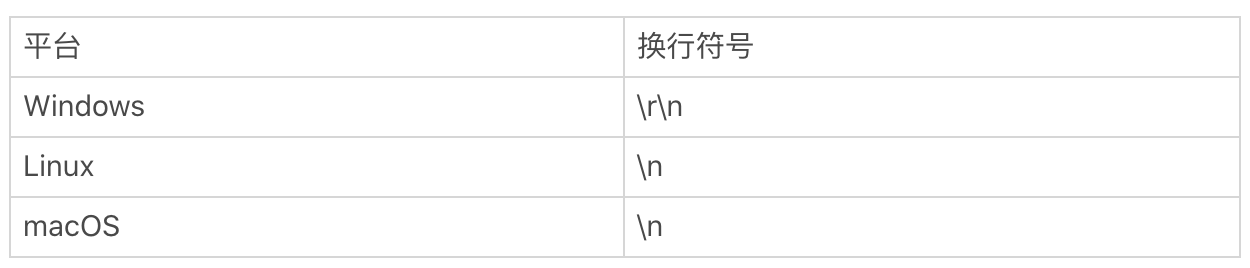
我们先说一下行的结尾是如何判断的。你应该知道换行符号。在计算机中,回车(\r)和换行(\n)其实是两个概念,并且在不同的平台上,换行的表示也是不一样的。我在这里列出了 Windows、Linux、macOS 平台上换行的表示方式。
那你可能就会问了,匹配行的开始或结束有什么用呢?
日志起始行判断
最常见的例子就是日志收集,我们在收集日志的时候,通常可以指定日志行的开始规则,比如以时间开头,那些不是以时间开头的可能就是打印的堆栈信息。我来给你一个以日期开头,下面每一行都属于同一篇日志的例子。
[2020-05-24 12:13:10] "/home/tu/demo.py"
Traceback (most recent call last):
File "demo.py", line 1, in <module>
1/0
ZeroDivisionError: integer division or modulo by zero
在这种情况下,我们就通过日期时间开头来判断哪一行是日志的第一行,在日期时间后面的日志都属于同一条日志。除非我们看见下一个日期时间的出现,才是下一条日志的开始。
输入数据校验
在Web服务中,我们常常需要对输入的内容进行校验,比如要求输入6位数字,我们可以使用 \d{6} 来校验。但你需要注意到,如果用户输入的是6位以上的数字呢?在这种情况下,如果不去要求用户录入的6位数字必须是行的开头或结尾,就算验证通过了,结果也可能不对。比如下面的示例,在不加行开始和结束符号时,用户输入了 7 位数字,也是能校验通过的:
>>> import re
>>> re.search('\d{6}', "1234567") is not None
True <-- 能匹配上 (包含6位数字)
>>> re.search('^\d{6}', "1234567") is not None
True <-- 能匹配上 (以6位数字开头)
>>> re.search('\d{6}$', "1234567") is not None
True <-- 能匹配上 (以6位数字结尾)
>>> re.search('^\d{6}$', "1234567") is not None
False <-- 不能匹配上 (只能是6位数字)
>>> re.search('^\d{6}$', "123456") is not None
True <-- 能匹配上 (只能是6位数字)
在前面的匹配模式章节中,我们学习过,在多行模式下,^和$符号可以匹配每一行的开头或结尾。大部分实现默认不是多行匹配模式,但也有例外,比如Ruby中默认是多行模式。所以对于校验输入数据来说,一种更严谨的做法是,使用 \A 和 \z (Python中使用 \Z) 来匹配整个文本的开头或结尾。
解决这个问题还有一种做法,我们可以在使用正则校验前,先判断一下字符串的长度,如果不满足长度要求,那就不需要再用正则去判断了。相当于你用正则解决主要的问题,而不是所有问题,这也是前面说的使用正则要克制。
环视( Look Around)
《孟子·梁惠王下》中有一个成语“王顾左右而言他”。其中“王顾左右”可以理解成“环视”,看看左边,再看看右边。在正则中我们有时候也需要瞻前顾后,找准定位。环视就是要求匹配部分的前面或后面要满足(或不满足)某种规则,有些地方也称环视为 零宽断言。
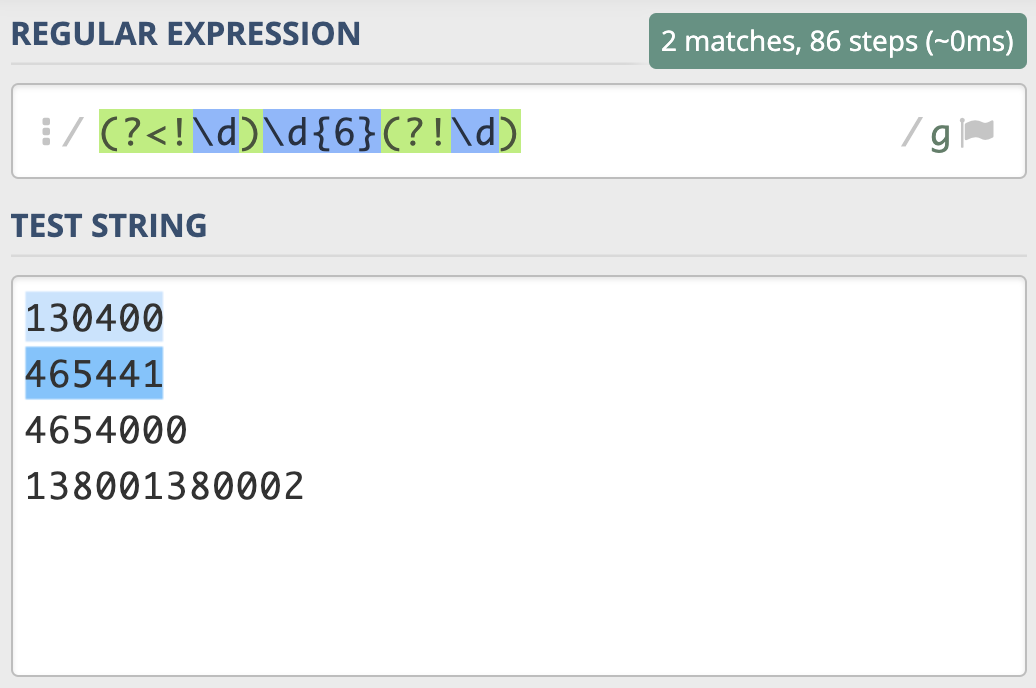
那具体什么时候我们会用到环视呢?我来举个例子。邮政编码的规则是由6位数字组成。现在要求你写出一个正则,提取文本中的邮政编码。根据规则,我们很容易就可以写出邮编的组成 \d{6}。我们可以使用下面的文本进行测试:
130400 满足要求
465441 满足要求
4654000 长度过长
138001380002 长度过长
我们发现,7位数的前6位也能匹配上,12位数匹配上了两次,这显然是不符合要求的。
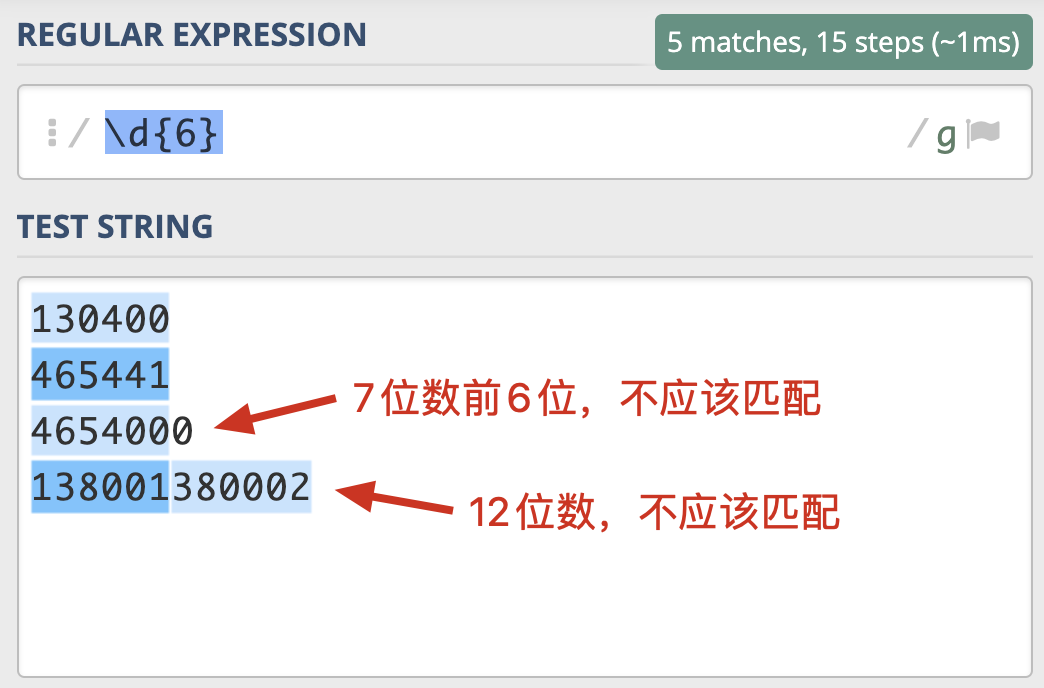
也就是说,除了文本本身组成符合这6位数的规则外,这6位数左边或右边都不能是数字。
正则是通过环视来解决这个问题的。解决这个问题的正则有四种。我给你总结了一个表。
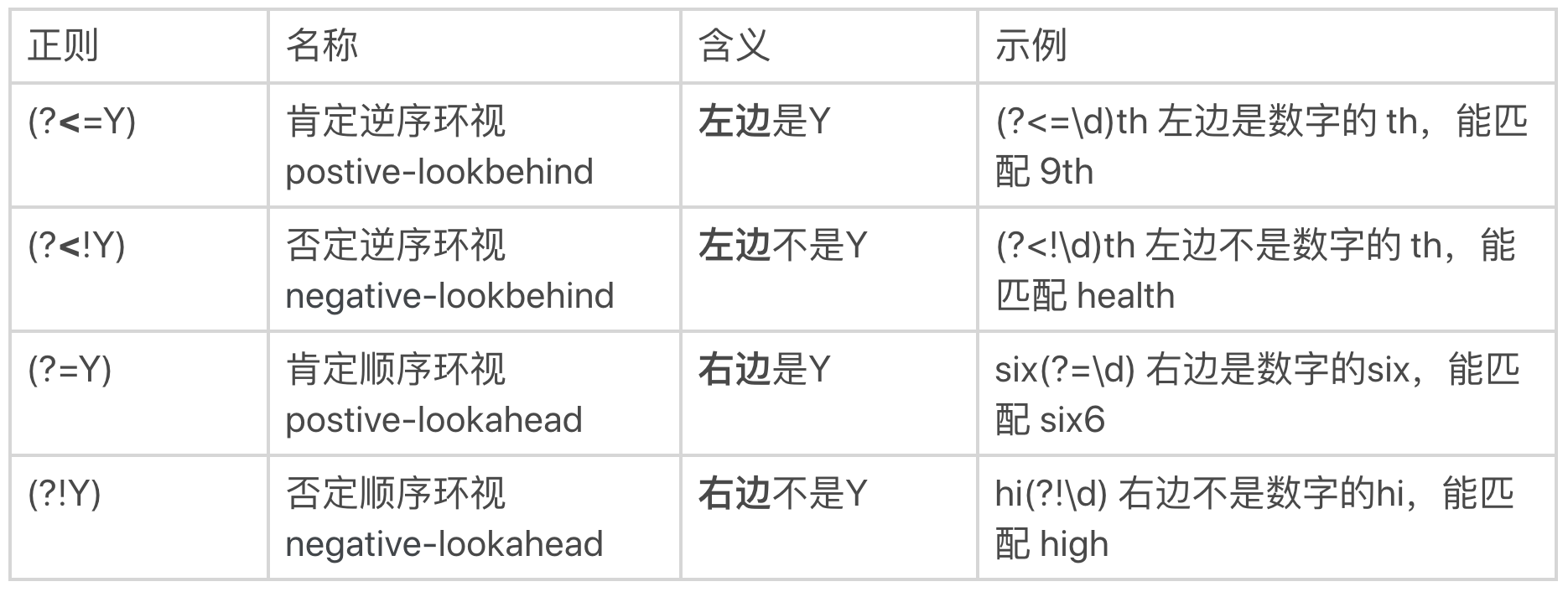
你可能觉得名称比较难记住,没关系,我给你一个小口诀,你只要记住了它的功能和写法就行。这个小口诀你可以在心里默念几遍: 左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思。
因此,针对刚刚邮编的问题,就可以写成左边不是数字,右边也不是数字的6位数的正则。即 (?<!\d)\d{6}(?!\d)。这样就能够符合要求了。
单词边界用环视表示
学习到这里,你可以思考一下,表示单词边界的 \b 如果用环视的方式来写,应该是怎么写呢?
这个问题其实比较简单,单词可以用 \w+ 来表示,单词的边界其实就是那些不能组成单词的字符,即左边和右边都不能是组成单词的字符。比如下面这句话:
the little cat is in the hat
the 左侧是行首,右侧是空格,hat 右侧是行尾,左侧是空格,其它单词左右都是空格。所有单词左右都不是 \w。
(?<!\w) 表示左边不能是单词组成字符,(?!\w) 右边不能是单词组成字符,即 \b\w+\b 也可以写成(?<!\w)\w+(?!\w)。
另外,根据前面学到的知识, 非\w 也可以用 \W 来表示。那单词的正则可以写成(?<=\W)\w+(?=\W)。
这个例子是为了让你有更多的思考,并不推荐在日常工作中这么来表示单词的边界,因为 \b 明显更简洁,也更容易阅读和书写。
环视与子组
友情提醒一下,前面我们在第三讲中讲过“分组与引用”相关的内容,如果忘记了可以回去复习复习。环视中虽然也有括号,但不会保存成子组。保存成子组的一般是匹配到的文本内容,后续用于替换等操作,而环视是表示对文本左右环境的要求,即环视只匹配位置,不匹配文本内容。你也可以总结一下,圆括号在正则中都有哪些用途,不断地去复习学过的内容,巩固自己的记忆。
总结
好了,今天的课就讲到这里。我来给你总结回顾一下。
今天我们学习了正则中断言相关的内容,最常见的断言有三种:单词的边界、行的开始或结束、环视。
单词的边界是使用 \b 来表示,这个比较简单。而多行模式下,每一行的开始和结束是使用 ^ 和 $ 符号。如果想匹配整个字符串的开始或结束,可以使用 \A 和 \z,它们不受匹配模式的影响。
最后就是环视,它又分为四种情况:肯定逆向环视、否定逆向环视、肯定顺序环视、否定顺序环视。在使用的时候记住一个方法: 有左尖括号代表看左边,没有尖括号是看右边,而感叹号是非的意思。
课后思考
最后,我们来做一个小练习吧。前面我们用正则分组引用来实现替换重复出现的单词,其实之前写的正则是不严谨的,在一些场景下,其实是不能正常工作的,你能使用今天学到的知识来完善一下它么?
the little cat cat2 is in the hat hat2, we like it.
需要注意一下,文本中 cat 和 cat2,还有 hat 和 hat2 其实是不同的单词。你应该能想到在 \w+ 左右加上单词边界 \b 来解决这个问题。你可以试一下,真的能像期望的那样工作么?也就是说,在分组引用时,前面的断言还有效么?
多动手练习,思考和总结,你才能更好地掌握学习的内容。
好,今天的课程就结束了,希望可以帮助到你。欢迎在评论区和我交流。也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。
转义:正则中转义需要注意哪些问题?
你好,我是伟忠。今天我来和你聊聊转义。转义对我们来说都不算陌生,编程的时候,使用到字符串时,双引号里面如果再出现双引号,我们就可以通过转义来解决。就像下面这样:
str = "How do you spell the word \"regex\"?"
虽然转义在日常工作中比较常见,但正则中什么时候需要转义,什么时候不用转义,在真正使用的时候可能会遇到这些麻烦。所以我们很有必要来系统了解一下正则中的转义。
转义字符
首先我们说一下什么是转义字符(Escape Character)。它在维基百科中是这么解释的:
在计算机科学与远程通信中,当转义字符放在字符序列中,它将对它后续的几个字符进行替代并解释。通常,判定某字符是否为转义字符由上下文确定。转义字符即标志着转义序列开始的那个字符。
这么说可能有点不好理解,我再来给你通俗地解释一下。转义序列通常有两种功能。第一种功能是编码无法用字母表直接表示的特殊数据。第二种功能是用于表示无法直接键盘录入的字符(如回车符)。
我们这节课说的就是第二种情况,转义字符自身和后面的字符看成一个整体,用来表示某种含义。最常见的例子是,C语言中用反斜线字符“\”作为转义字符,来表示那些不可打印的ASCII控制符。另外,在URI协议中,请求串中的一些符号有特殊含义,也需要转义,转义字符用的是百分号“%”。之所以把这个字符称为 转义字符,是因为它后面的字符,不是原来的意思了。
在日常工作中经常会遇到转义字符,比如我们在shell中删除文件,如果文件名中有*号,我们就需要转义,此时我们能看出,使用了转义字符后,*号就能放进文件名里了。
rm access_log* # 删除当前目录下 access_log 开头的文件
rm access_log\* # 删除当前目录下名字叫 access_log* 的文件
再比如我们在双引号中又出现了双引号,这时候就需要转义了,转义之后才能正常表示双引号,否则会报语法错误。比如下面的示例,引号中的 Hello World! 也是含有引号的。
print "tom said \"Hello World!\" to the crowd."
下面是一些常见的转义字符以及它们的含义。
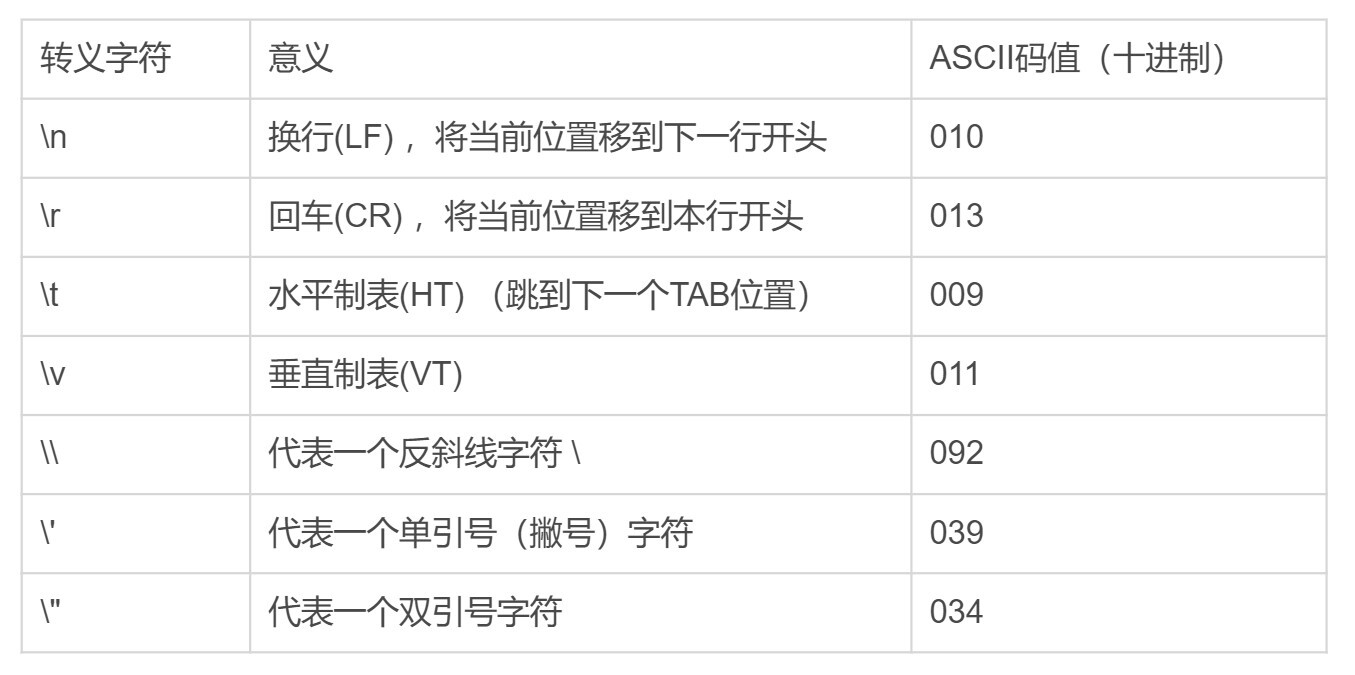
字符串转义和正则转义
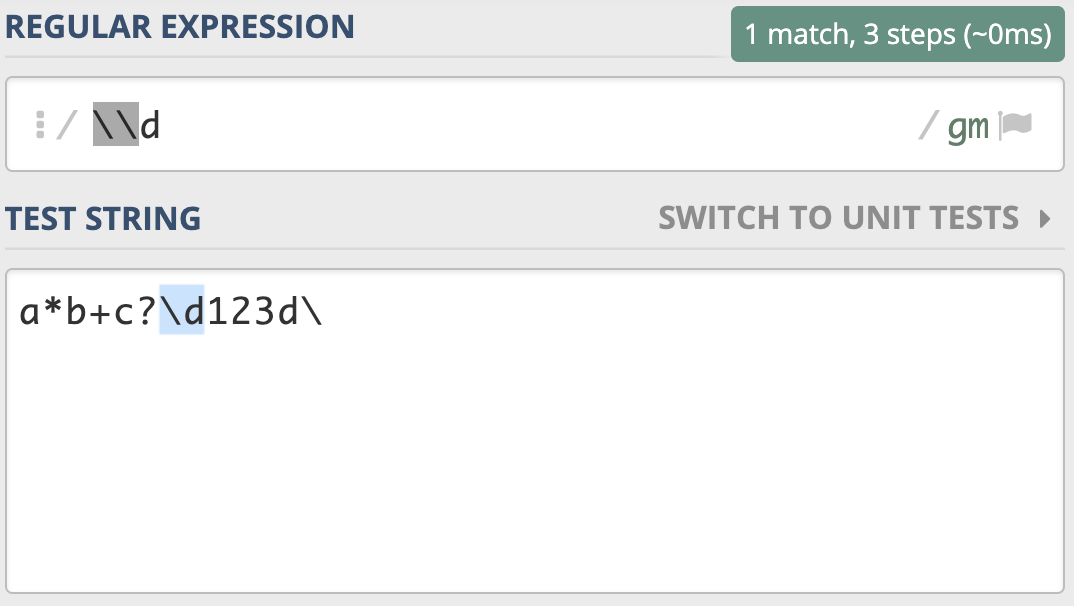
说完了转义字符,我们再来看一下正则中的转义。正则中也是使用反斜杠进行转义的。
一般来说,正则中 \d 代表的是单个数字,但如果我们想表示成 反斜杠和字母d,这时候就需要进行转义,写成 \\d,这个就表示反斜杠后面紧跟着一个字母d。
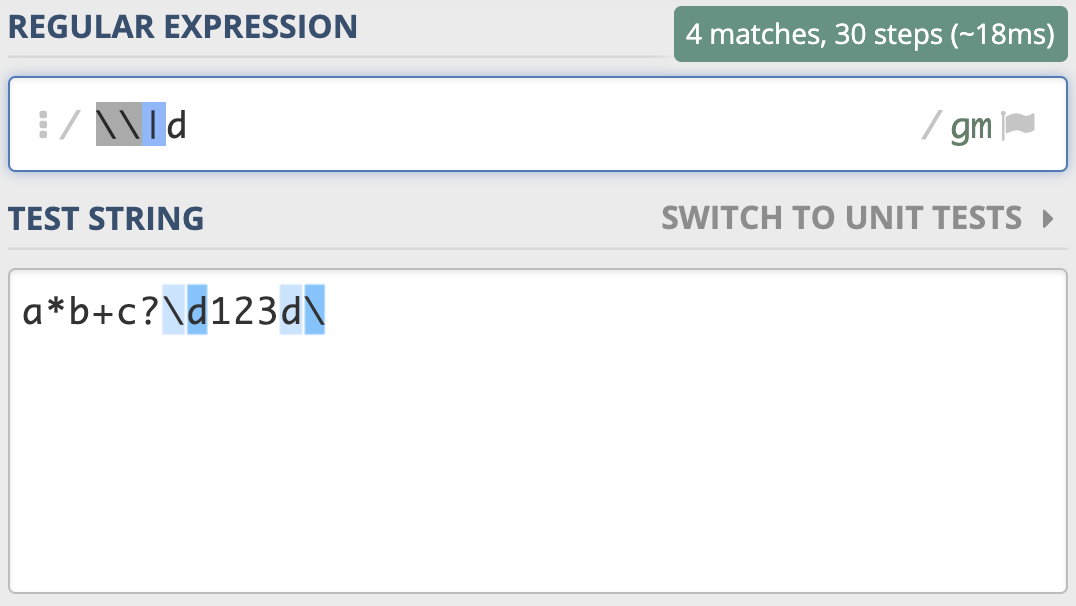
刚刚的反斜杠和d是连续出现的两个字符,如果你想表示成反斜杠或d,可以用管道符号或中括号来实现,比如 \|d 或 [\d]。
需要注意的是,如果你想用代码来测试这个,在程序中表示普通字符串的时候,我们如果要表示反斜杠,通常需要写成两个反斜杠,因为只写一个会被理解成“转义符号”,而不是反斜杠本身。
下面我给出使用 Python3 来测试的情况,你可以看一下。
>>> import re
>>> re.findall('\\|d', 'a*b+c?\d123d\') # 字符串没转义"反斜杠"
File "<input>", line 1
re.findall('\\|d', 'a*b+c?\d123d\')
^
SyntaxError: EOL while scanning string literal
>>> re.findall('\\|d', 'a*b+c?\\d123d\\')
[]
看到这里,你内心是不是有很多问号?为什么转义了还不行呢?我们来把正则表达式部分精简一下,看看两个反斜杠在正则中是什么意思。
>>> import re
>>> re.findall('\\', 'a*b+c?\\d123d\\')
Traceback (most recent call last):
省去部分信息
re.error: bad escape (end of pattern) at position 0
我们发现,正则部分写的两个反斜杠,Python3 处理的时候会报错,认为是转义字符,即认为是单个反斜杠,如果你再进一步测试在正则中写单个反斜杠,你会发现直接报语法错误,你可以自行尝试。
那如何在正则中正确表示“反斜杠”呢?答案是写四个反斜杠。
>>> import re
>>> re.findall('\\\\', 'a*b+c?\\d123d\\')
['\\', '\\']
你可以想一下,为什么不是三个呢?后面的文本部分,也得要用四个反斜杠表示才是正确的么?到这里,你是不是发现,转义其实没那么简单。
我来给你详细解释一下这里面的过程,在程序使用过程中,从输入的字符串到正则表达式,其实有两步转换过程,分别是字符串转义和正则转义。
在正则中正确表示“反斜杠”具体的过程是这样子:我们输入的字符串,四个反斜杠 \\,经过第一步字符串转义,它代表的含义是两个反斜杠 \;这两个反斜杠再经过第二步 正则转义,它就可以代表单个反斜杠 \了。
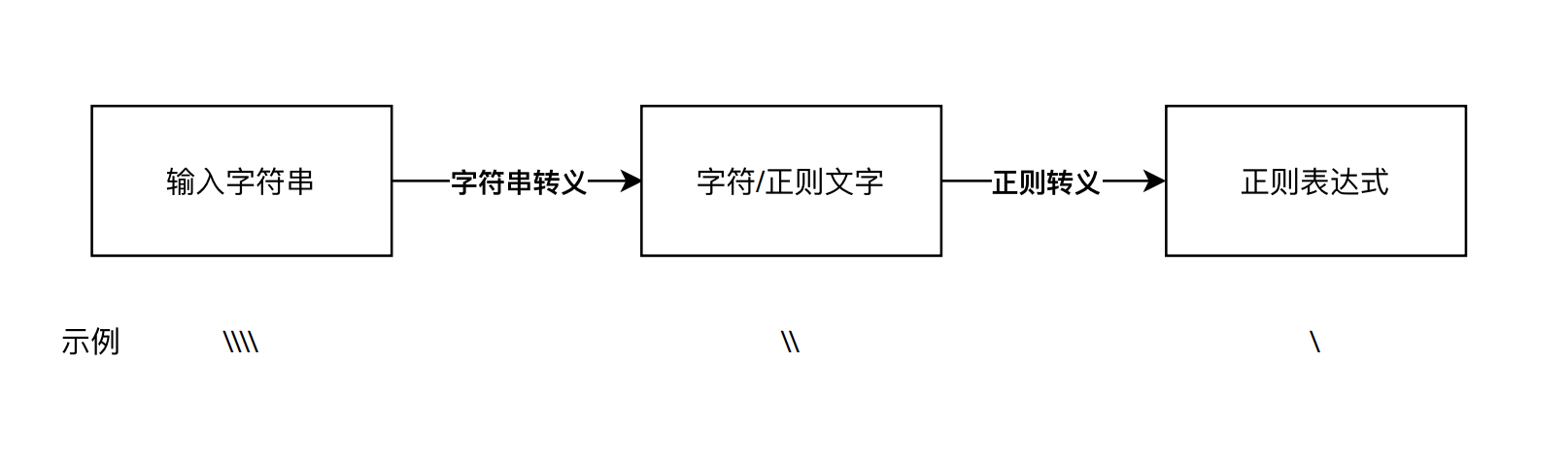
你可以用这个过程,推导一下两个和三个反斜杠的转换过程,这样你就会明白上面报错的原因了。
那在真正使用的时候,有没有更简单的方法呢?答案是有的,我们尽量使用原生字符串,在 Python 中,可以在正则前面加上小写字母 r 来表示。
>>> import re
>>> re.findall(r'\\', 'a*b+c?\\d123d\\')
['\\', '\\']
这样看起来就简单很多,因为少了上面说的第一次转换。
正则中元字符的转义
在前面的内容中,我们讲了很多元字符,相信你一定都还记得。如果现在我们要查找比如星号(*)、加号(+)、问号(?)本身,而不是元字符的功能,这时候就需要对其进行转义,直接在前面加上反斜杠就可以了。这个转义就比较简单了,下面是一个示例。
>>> import re
>>> re.findall('\+', '+')
['+']
括号的转义
在正则中方括号 [] 和 花括号 {} 只需转义开括号,但圆括号 () 两个都要转义。我在下面给了你一个比较详细的例子。
>>> import re
>>> re.findall('\(\)\[]\{}', '()[]{}')
['()[]{}']
>>> re.findall('\(\)\[\]\{\}', '()[]{}') # 方括号和花括号都转义也可以
['()[]{}']
在正则中,圆括号通常用于分组,或者将某个部分看成一个整体,如果只转义开括号或闭括号,正则会认为少了另外一半,所以会报错。
括号的转义示例,你可以参考这里: https://regex101.com/r/kJfvd6/1。
使用函数消除元字符特殊含义
我们也可以使用编程语言自带的转义函数来实现转义。下面我给出了一个在 Python里转义的例子,你可以看一下。
>>> import re
>>> re.escape('\d') # 反斜杠和字母d转义
'\\\\d'
>>> re.findall(re.escape('\d'), '\d')
['\\d']
>>> re.escape('[+]') # 中括号和加号
'\\[\\+\\]'
>>> re.findall(re.escape('[+]'), '[+]')
['[+]']
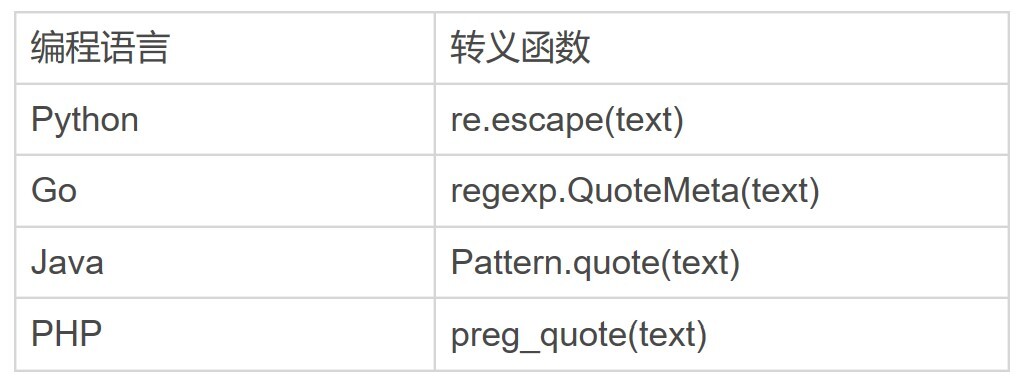
这个转义函数可以将整个文本转义,一般用于转义用户输入的内容,即把这些内容看成普通字符串去匹配,但你还是得好好注意一下,如果使用普通字符串查找能满足要求,就不要使用正则,因为它简单不容易出问题。下面是一些其他编程语言对应的转义函数,供你参考。
字符组中的转义
讲完了元字符的转义,我们现在来看看字符组中的转义。书写正则的时候,在字符组中,如果有过多的转义会导致代码可读性差。在字符组里只有三种情况需要转义,下面我来给你讲讲具体是哪三种情况。
字符组中需要转义的有三种情况
- 脱字符在中括号中,且在第一个位置需要转义:
>>> import re
>>> re.findall(r'[^ab]', '^ab') # 转义前代表"非"
['^']
>>> re.findall(r'[\^ab]', '^ab') # 转义后代表普通字符
['^', 'a', 'b']
- 中划线在中括号中,且不在首尾位置:
>>> import re
>>> re.findall(r'[a-c]', 'abc-') # 中划线在中间,代表"范围"
['a', 'b', 'c']
>>> re.findall(r'[a\-c]', 'abc-') # 中划线在中间,转义后的
['a', 'c', '-']
>>> re.findall(r'[-ac]', 'abc-') # 在开头,不需要转义
['a', 'c', '-']
>>> re.findall(r'[ac-]', 'abc-') # 在结尾,不需要转义
['a', 'c', '-']
- 右括号在中括号中,且不在首位:
>>> import re
>>> re.findall(r'[]ab]', ']ab') # 右括号不转义,在首位
[']', 'a', 'b']
>>> re.findall(r'[a]b]', ']ab') # 右括号不转义,不在首位
[] # 匹配不上,因为含义是 a后面跟上b]
>>> re.findall(r'[a\]b]', ']ab') # 转义后代表普通字符
[']', 'a', 'b']
字符组中其它的元字符
一般来说如果我们要想将元字符( .*+?()之类)表示成它字面上本来的意思,是需要对其进行转义的,但如果它们出现在字符组中括号里,可以不转义。这种情况,一般都是单个长度的元字符,比如点号( .)、星号( *)、加号( +)、问号( ?)、左右圆括号等。它们都不再具有特殊含义,而是代表字符本身。但如果在中括号中出现 \d 或 \w 等符号时,他们还是元字符本身的含义。
>>> import re
>>> re.findall(r'[.*+?()]', '[.*+?()]') # 单个长度的元字符
['.', '*', '+', '?', '(', ')']
>>> re.findall(r'[\d]', 'd12\\') # \w,\d等在中括号中还是元字符的功能
['1', '2'] # 匹配上了数字,而不是反斜杠\和字母d
下面我来给你简单总结一下字符组中的转义情况,我们提到了三种必须转义的情况,其它情况不转义也能正常工作,但在实际操作过程中,如果遇到在中括号中使用这三个字符原本的意思,你可以都进行转义,剩下其它的元字符都不需要转义。
总结
好了,今天的内容讲完了,我来带你总结回顾一下。
正则中转义有些情况下会比较复杂,从录入的字符串文本,到最终的正则表达式, 经过了字符串转义和正则转义两个步骤。 元字符的转义一般在前面加反斜杠就行,方括号和花括号的转义一般转义开括号就可以,但圆括号两个都需要转义,我们可以借助编程语言中的转义函数来实现转义。另外我们也讲了字符组中三种需要转义的情况,详细的可以参考下面的脑图。
思考题
通过今天的学习,不知道你对转义掌握的怎么样了呢?再来一个例子加深一下你的理解吧,文本部分是反斜杠,n,换行,反斜杠四个部分组成。正则部分分别是1到4个反斜杠和字母n,我用Python3写了对应的示例,相应的查找过程是这样子的。
>>> import re
>>> re.findall('\n', '\\n\n\\')
['\n'] # 找到了换行符
>>> re.findall('\\n', '\\n\n\\')
['\n'] # 找到了换行符
>>> re.findall('\\\n', '\\n\n\\')
['\n'] # 找到了换行符
>>> re.findall('\\\\n', '\\n\n\\')
['\\n'] # 找到了反斜杠和字母n
例子虽然看上去简单,不过你能不能解释出这四个示例中的转义过程呢?
好了,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,同时欢迎你把这节课分享给你的朋友或者同事,一起交流一下。
正则有哪些常见的流派及其特性?
你好,我是涂伟忠。今天我来给你讲讲正则常见的流派及其特性。
你可能要问了,讲正则流派有啥用呢?不如多来点实战啊。其实,我们去了解正则的演变过程是很有必要的。因为你一旦了解了正则的演变过程之后,就能够更加正确地去使用正则,尤其是在 Linux系统中。
那我们就先来看一个有关Linux系统的例子,你先来感受一下。
如果你在 Linux 系统的一些命令行中使用正则,比如使用 grep 过滤内容的时候,你可能会发现结果非常诡异,就像下图这样,在grep命令中,使用正则\d+取不到数据,甚至在 egrep 中输出了英文字母d那一行。
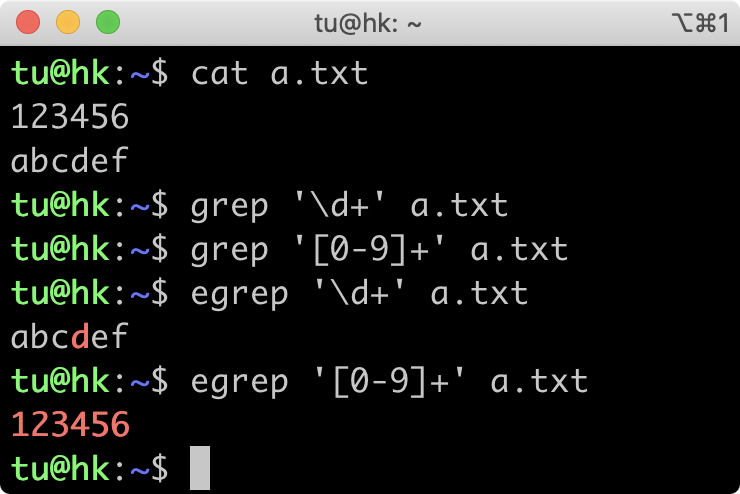
这个执行结果的原因就和正则的演变有着密不可分的关系。那到底有什么样的关系呢?我们接着往下看,我从正则的发展历史给你讲起。
正则表达式简史
正则表达式的起源,可以追溯到,早期神经系统如何工作的研究。在20世纪40年代,有两位神经生理学家(Warren McCulloch和Walter Pitts),研究出了一种用数学方式来描述神经网络的方法。
1956年,一位数学家(Stephen Kleene)发表了一篇标题为《 神经网络事件表示法和有穷自动机》的论文。这篇论文描述了一种叫做“正则集合(Regular Sets)”的符号。
随后,大名鼎鼎的Unix之父Ken Thompson于1968年发表了文章《 正则表达式搜索算法》,并且将正则引入了自己开发的编辑器qed,以及之后的编辑器ed中,然后又移植到了大名鼎鼎的文本搜索工具grep中。自此,正则表达式被广泛应用到Unix系统或类Unix系统(如macOS、Linux)的各种工具中。
随后,由于正则功能强大,非常实用,越来越多的语言和工具都开始支持正则。不过遗憾的是,由于没有尽早确立标准,导致各种语言和工具中的正则虽然功能大致类似,但仍然有不少细微差别。
于是,诞生于1986年的POSIX开始进行标准化的尝试。 POSIX 作为一系列规范,定义了Unix操作系统应当支持的功能,其中也包括正则表达式的规范。因此,Unix系统或类Unix系统上的大部分工具,如grep、sed、awk等,均遵循该标准。我们把这些遵循POSIX正则表达式规范的正则表达式,称为 POSIX流派 的正则表达式。
在1987年12月,Larry Wall发布了Perl语言第一版,因其功能强大一票走红,所引入的正则表达式功能大放异彩。之后Perl语言中的正则表达式不断改进,影响越来越大。于是在此基础上,1997年又诞生了 PCRE—— Perl兼容正则表达式(Perl Compatible Regular Expressions)。
PCRE是一个兼容Perl语言正则表达式的解析引擎,是由Philip Hazel开发的,为很多现代语言和工具所普遍使用。除了Unix上的工具遵循POSIX标准,PCRE现已成为其他大部分语言和工具隐然遵循的标准。
之后,正则表达式在各种计算机语言或各种应用领域得到了更为广泛的应用和发展。 POSIX流派 与 PCRE流派 是目前正则表达式流派中的两大最主要的流派。
正则表达式流派
就像前面说的一样,目前正则表达式主要有两大流派(Flavor):POSIX流派与PCRE流派。下面我们分别来看看。
1. POSIX流派
这里我们先简要介绍一下POSIX流派。POSIX 规范定义了正则表达式的两种标准:
- BRE标准(Basic Regular Expression 基本正则表达式);
- ERE标准(Extended Regular Expression 扩展正则表达式)。
接下来,我们一起来看一下这两种标准的异同点。
BRE标准 和 ERE标准
早期BRE与ERE标准的区别主要在于,BRE标准不支持量词问号和加号,也不支持多选分支结构管道符。BRE标准在使用花括号,圆括号时要转义才能表示特殊含义。BRE标准用起来这么不爽,于是有了 ERE标准,在使用花括号,圆括号时不需要转义了,还支持了问号、加号 和 多选分支。
我们现在使用的Linux发行版,大多都集成了GNU套件。GNU在实现POSIX标准时,做了一定的扩展,主要有以下三点扩展。
- GNU BRE支持了 +、?,但转义了才表示特殊含义,即需要用
\+、\?表示。 - GNU BRE支持管道符多选分支结构,同样需要转义,即用
\|表示。 - GNU ERE也支持使用反引用,和BRE一样,使用 \1、\2…\9 表示。
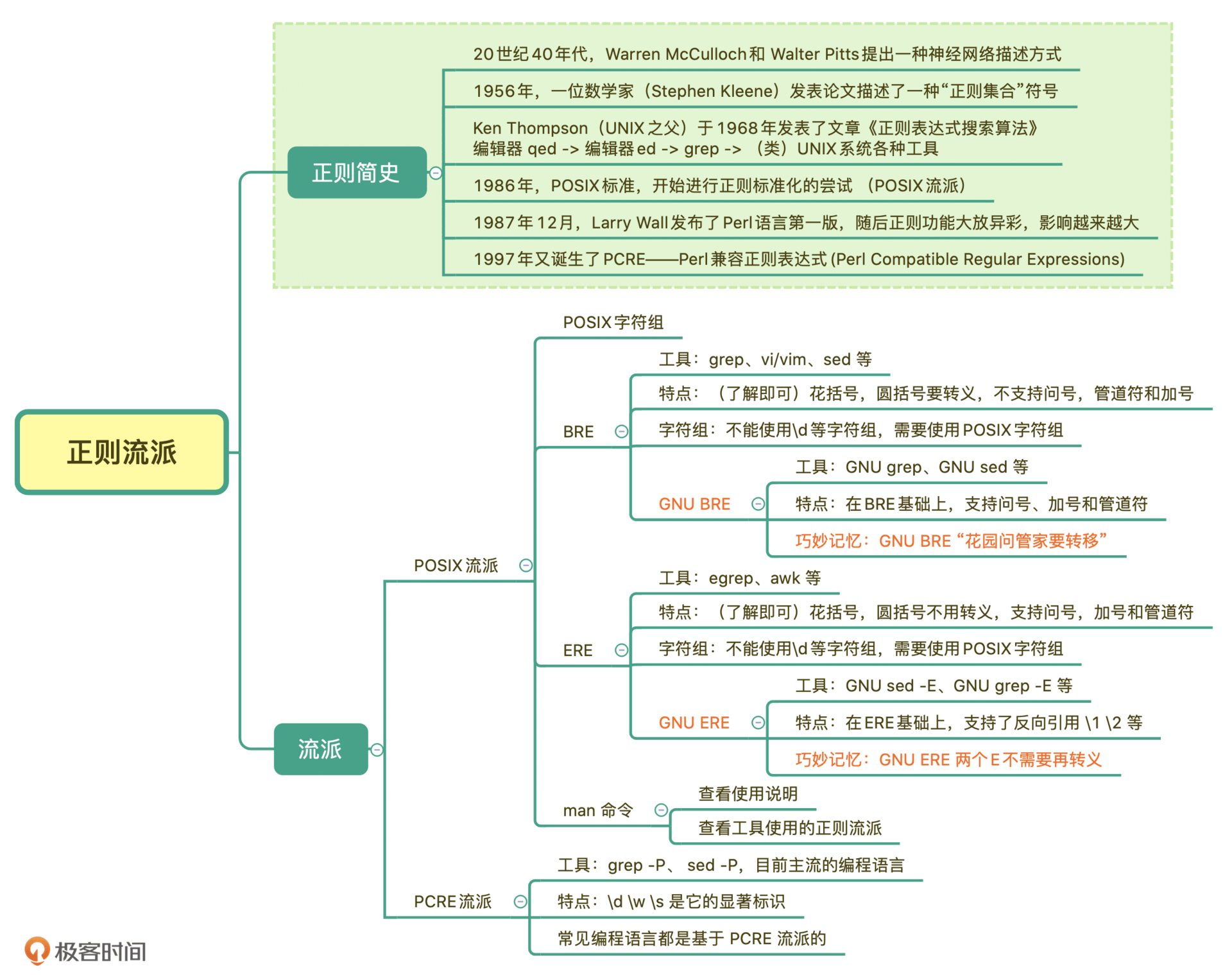
BRE标准和ERE标准的详细区别,我给了你一个参考图,你可以看一下,浅黄色背景是BRE和ERE不同的地方,三处天蓝色字体是GNU扩展。
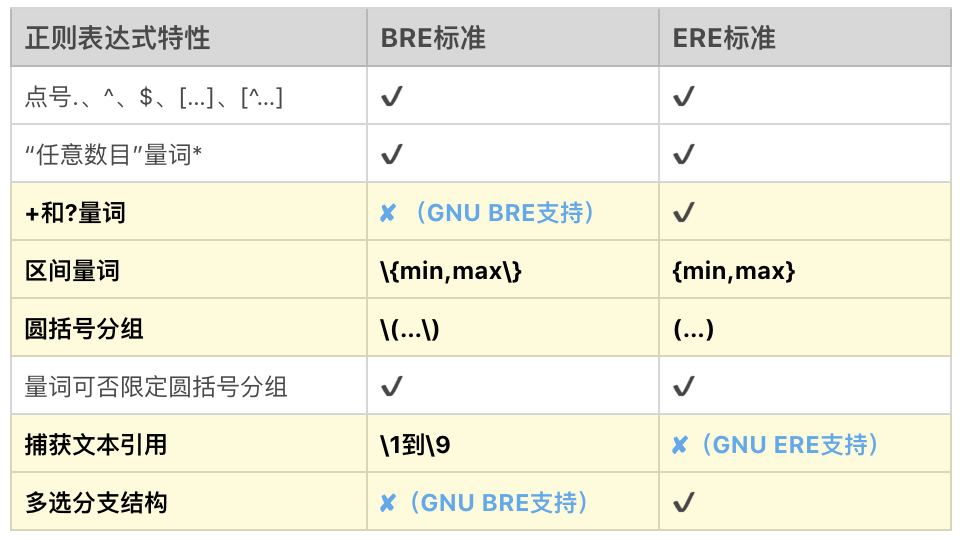
总之,GNU BRE 和 GNU ERE 它们的功能特性并没有太大区别,区别是在于部分语法层面上,主要是一些字符要不要转义。
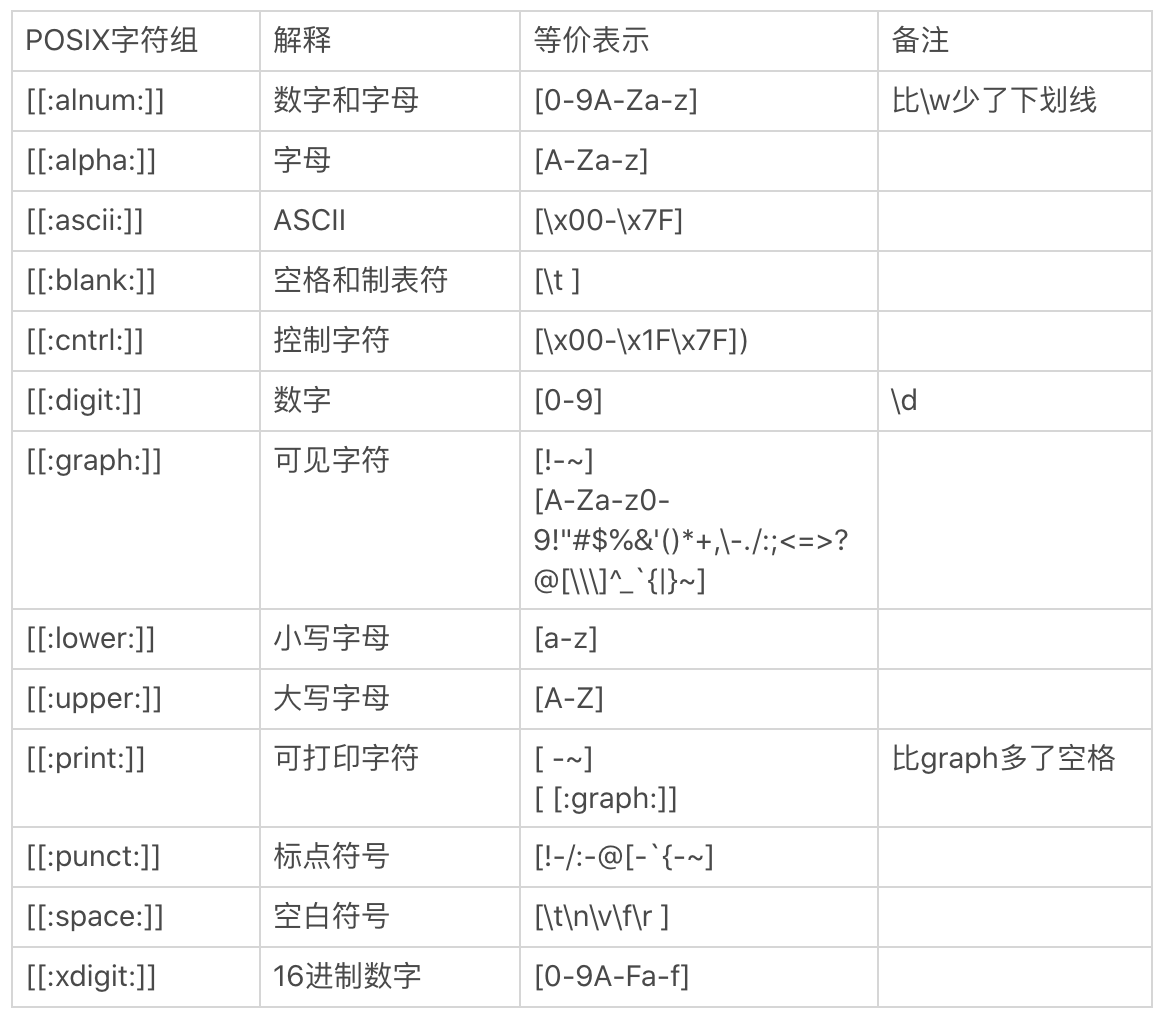
POSIX字符组
POSIX流派还有一个特殊的地方,就是有自己的字符组,叫POSIX字符组。这个类似于我们之前学习的 \d 表示数字,\s表示空白符等,POSIX中也定义了一系列的字符组。具体的清单和解释如下所示:
2. PCRE流派
除了POSIX标准外,还有一个Perl分支,也就是我们现在熟知的PCRE。随着Perl语言的发展,Perl语言中的正则表达式功能越来越强悍,为了把Perl语言中正则的功能移植到其他语言中,PCRE就诞生了。
目前大部分常用编程语言都是源于PCRE标准,这个流派显著特征是有\d、\w、\s这类字符组简记方式。
不过,虽然PCRE流派是从Perl语言中衍生出来的,但与Perl语言中的正则表达式在语法上还是有一些细微差异,比如PHP的preg正则表达式(Perl Regular Expression)与Perl正则表达式的差异可看 这里。
考虑到目前绝大部分常用编程语言所采用的正则引擎,基本都属于PCRE流派的现实情况,我们的课程也是主要讲解PCRE流派。前面,对于正则表达式语法元素的解释都是以PCRE流派为准。
PCRE流派的兼容问题
虽然PCRE流派是与Perl正则表达式相兼容的流派,但这种兼容在各种语言和工具中还存在程度上的差别,这包括了直接兼容与间接兼容两种情况。
而且,即便是直接兼容,也并非完全兼容,还是存在部分不兼容的情况。原因也很简单,Perl语言中的正则表达式在不断改进和升级之中,其他语言和工具不可能完全做到实时跟进与更新。
- 直接兼容,PCRE流派中与Perl正则表达式直接兼容的语言或工具。比如Perl、PHP preg、PCRE库等,一般称之为Perl系。
- 间接兼容,比如Java系(包括Java、Groovy、Scala等)、Python系(包括Python2和Python3)、JavaScript系(包括原生JavaScript和扩展库XRegExp)、.Net系(包括C#、VB.Net等)等。
在Linux中使用正则
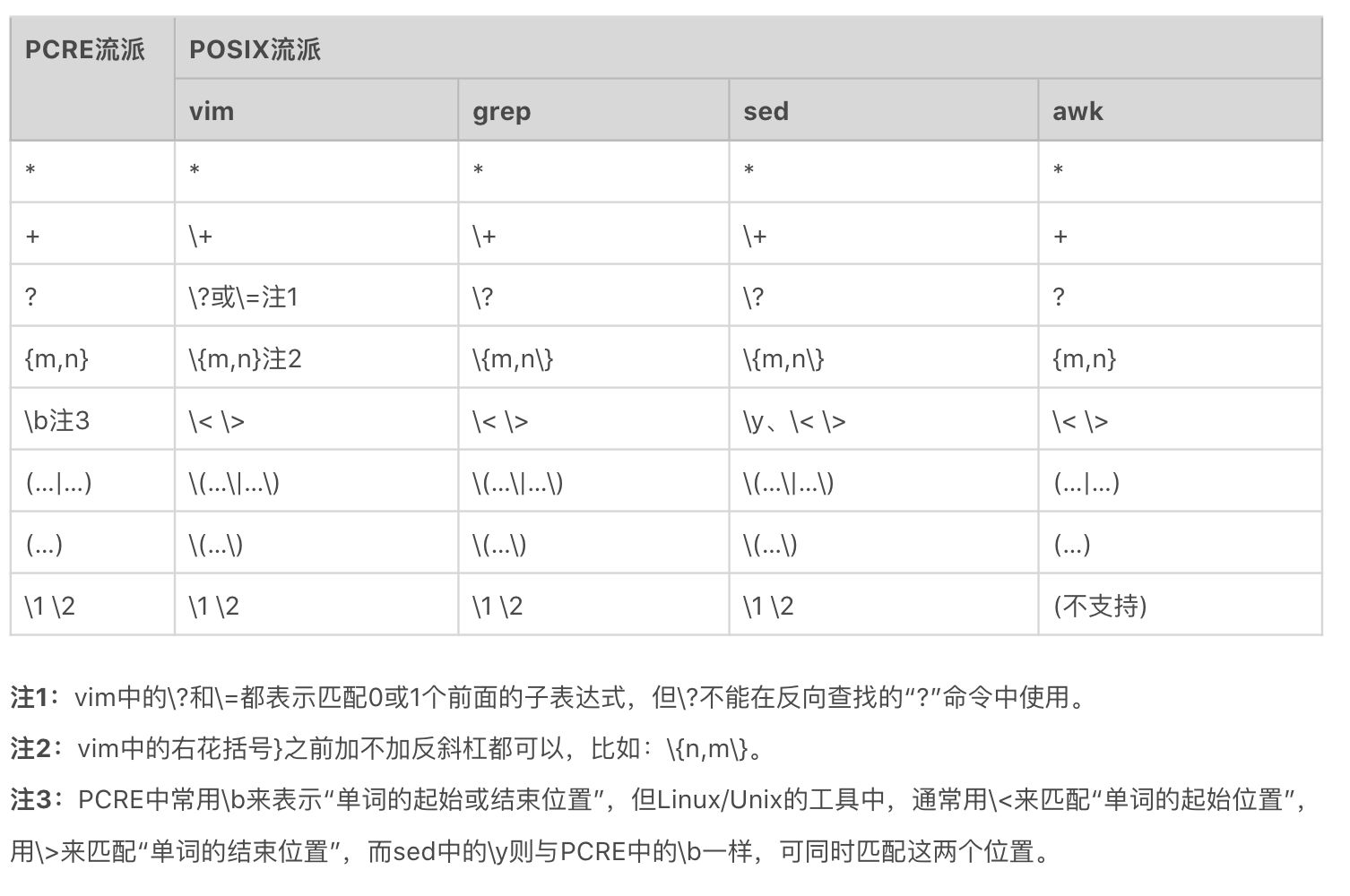
在遵循POSIX规范的UNIX/LINUX系统上,按照 BRE标准 实现的有 grep、sed 和 vi/vim 等,而按照 ERE标准 实现的有 egrep、awk 等。
在UNIX/LINUX系统里PCRE流派与POSIX流派的对比,我为你整理了一个表,你可以看一下。
刚刚我们提到了工具对应的实现标准,其实有一些工具实现同时兼容多种正则标准,比如前面我们讲到的 grep 和 sed。如果在使用时加上-E选项,就是使用ERE标准;如果加上-P选项,就是使用PCRE标准。
使用 ERE 标准
grep -E '[[:digit:]]+' access.log
使用 PCRE 标准
grep -P '\d+' access.log
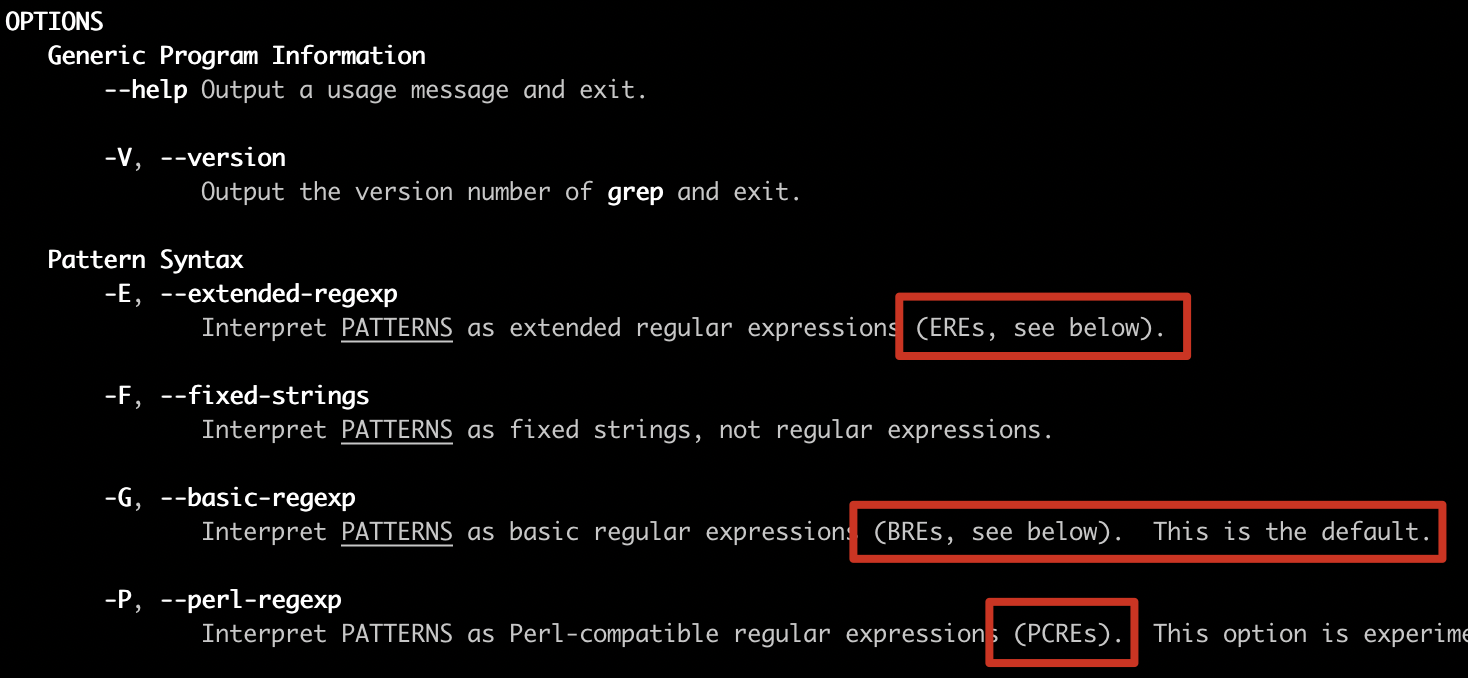
在使用具体命令时,如何知道属于哪个流派呢?你不用担心太多了记不住。在Linux系统中有个 man 命令可以帮助我们。比如,我在 macOS 上执行 man grep ,可以看到选项 -G 是指定使用 BRE标准(默认),-E是ERE标准,-P是PCRE标准。所以,在使用具体工具时,你通过这个方法查一下命令的说明就好了。
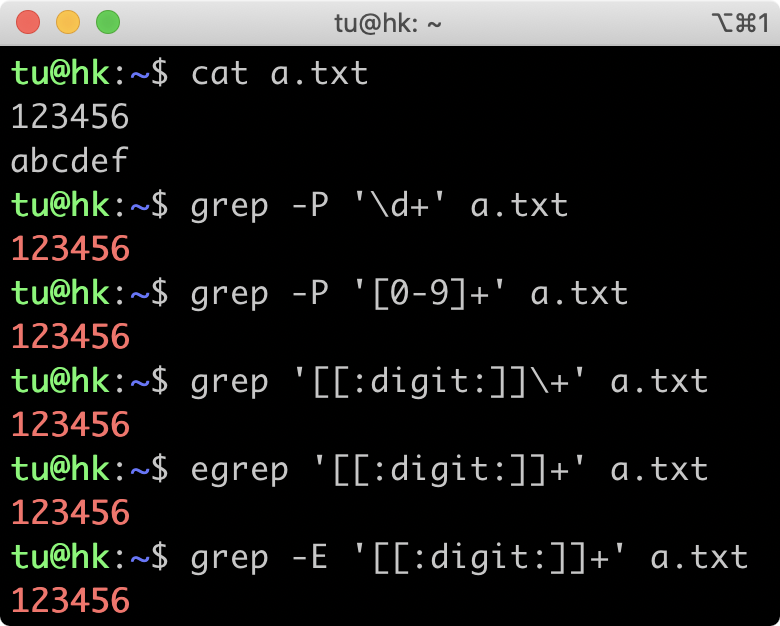
我们再看开篇提出的问题。
通过今天的学习,我们搞懂了各流派的差异,以及命令实现的是哪个正则标准。在 grep 中使用 \d+ 查找不到结果,是因为 grep 属于 BRE 流派,不支持 \d 来表示数字,加号也要转义才能表示量词的一到多次,所以无法找出数字那一行。如果你一定要用BRE流派,可以通过 使用POSIX字符组 和 转义加号 来实现。而egrep属于ERE流派,也不支持 \d,\d 相当于字母 d,所以找到了字母那一行。
在grep命令中,你可以指定参数-P来使用PCRE流派,这样就和我们之前学习到的是一致的了。知道了原因之后,你应该能写出相应的解决方法。下图是一些能工作的方法。
为了方便加深你的理解,我给你提供了一个例子来帮你巩固。你可以使用下面的文本,在Linux中使用grep命令练习查找包含一到多个数字的行。
123456
abcdef
\d
\d+
d+
总结
好了,今天的内容讲完了,我来带你总结回顾一下。
今天我带你简单回顾了下正则表达式的历史。正则主要有两大流派,分别是POSIX流派和PCRE流派。其中POSIX流派有两个标准,分别是BRE标准和ERE标准, 一般情况下,我们面对的都是GNU BRE和GNU ERE。它们的主要区别在于,前者要转义。 另外, POSIX流派一个特点就是有自己的字符组POSIX 字符组,这不同于常见的 \d 等字符组。
PCRE流派是如今大多数编程语言实现的流派,最大的特点就是支持\d\s\w等,我们前面讲的内容也是基于这个流派进行的。
如果你需要在类Unix平台命令等上使用正则,使用前需要搞清楚工具属于哪个标准,比如grep、sed、vi/vim 等属于BRE标准,egrep、awk 属于ERE标准。而sed -P、grep -P等属于PCRE流派。这些也不需要死记硬背,使用时用man命令看一下就好了。
我在这里给你放了一张今天所讲内容的总结脑图,你可以看一下。另外我还给你提供了一个记忆小窍门,你可以着重记忆一下这句话: GNU ERE名称中有两个E,不需要再转义。而GNU BRE 只有一个E,使用时“花圆问管加”时都要转义。
此外,我还给了你一个Linux/Unix工具与正则表达式的POSIX规范(余晟)的 参考链接,你可以看一下。
课后思考
最后,我们来做一个小练习吧。在Linux上使用grep命令,分别实现使用不同的标准(即 BRE、ERE、PCRE ),来查找含有 ftp、http 或 https 的行。你可以动手体验一下不同标准的区别。
https://time.geekbang.org
ftp://ftp.ncbi.nlm.nih.gov
www.baidu.com
www.ncbi.nlm.nih.gov
好,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,并把文章分享给你的朋友或者同事,一起交流一下。
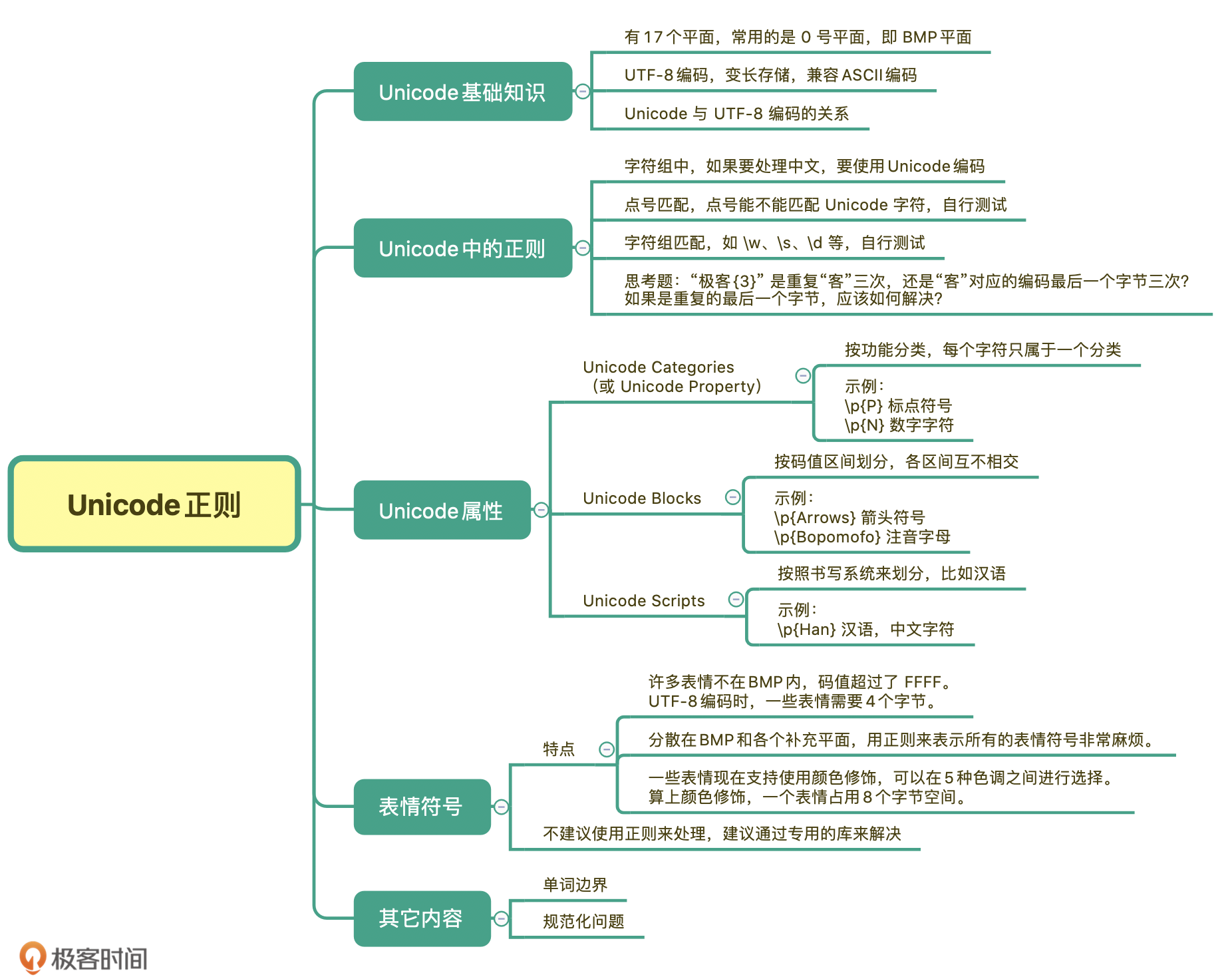
应用1:正则如何处理 Unicode 编码的文本?
你好,我是伟忠。这一节我们来学习,如何使用正则来处理Unicode编码的文本。如果你需要使用正则处理中文,可以好好了解一下这些内容。
不过,在讲解正则之前,我会先给你讲解一些基础知识。只有搞懂了基础知识,我们才能更好地理解今天的内容。一起来看看吧!
Unicode基础知识
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字进行了整理、编码。Unicode使计算机呈现和处理文字变得简单。
Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前Unicode最新的版本为 2020 年3月10日公布的13.0.0,已经收录超过 14 万个字符。
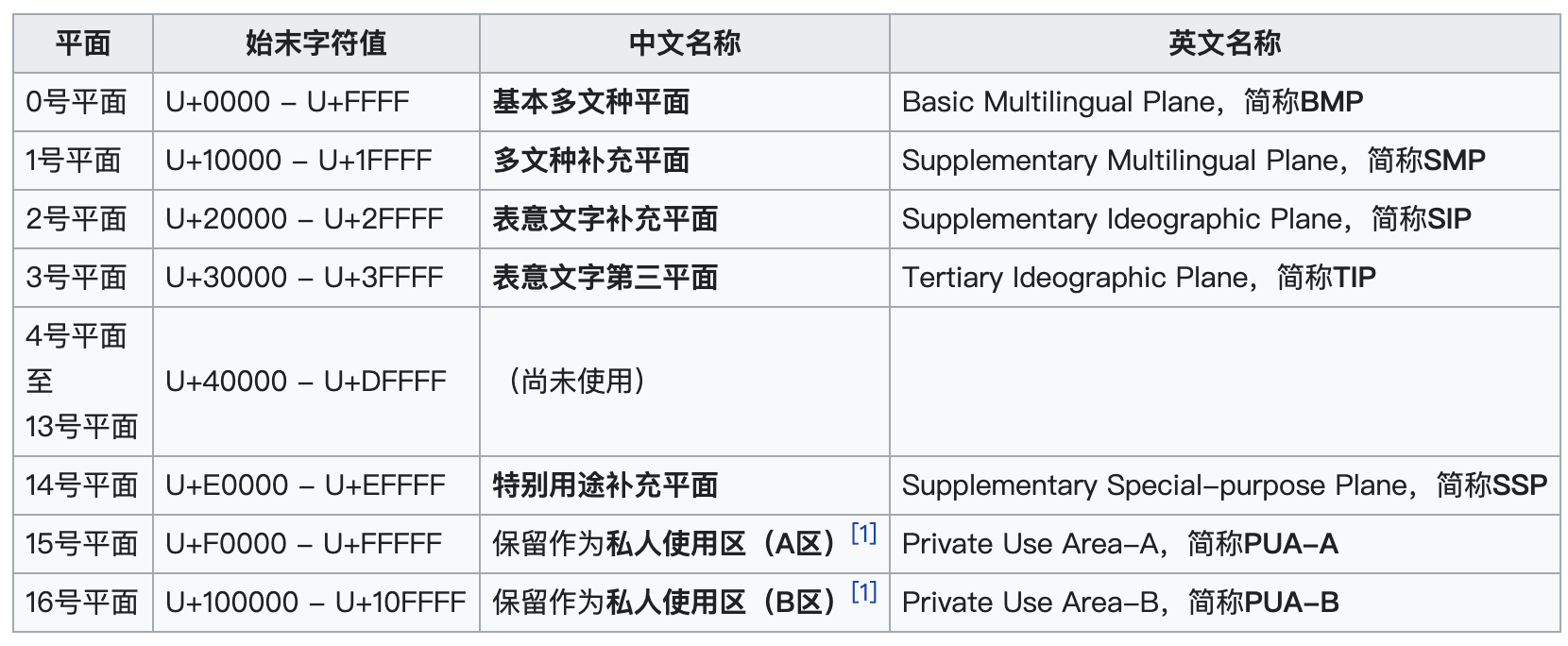
现在的Unicode字符分为17组编排,每组为一个平面(Plane),而每个平面拥有 65536(即2的16次方)个码值(Code Point)。然而,目前Unicode只用了少数平面,我们用到的绝大多数字符都属于第0号平面,即 BMP平面。除了BMP 平面之外,其它的平面都被称为 补充平面。
关于各个平面的介绍我在下面给你列了一个表,你可以看一下。
Unicode标准也在不断发展和完善。目前,使用4个字节的编码表示一个字符,就可以表示出全世界所有的字符。那么Unicode在计算机中如何存储和传输的呢?这就涉及编码的知识了。
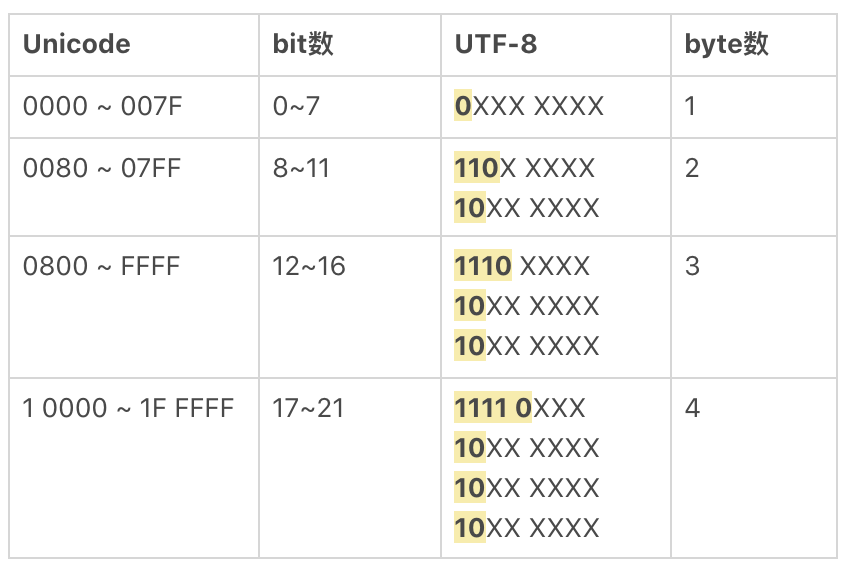
Unicode相当于规定了字符对应的码值,这个码值得编码成字节的形式去传输和存储。最常见的编码方式是UTF-8,另外还有UTF-16,UTF-32 等。UTF-8 之所以能够流行起来,是因为其编码比较巧妙,采用的是变长的方法。也就是一个Unicode字符,在使用UTF-8编码表示时占用1到4个字节不等。最重要的是Unicode兼容ASCII编码,在表示纯英文时,并不会占用更多存储空间。而汉字呢,在UTF-8中,通常是用三个字节来表示。
>>> u'正'.encode('utf-8')
b'\xe6\xad\xa3'
>>> u'则'.encode('utf-8')
b'\xe5\x88\x99'
下面是 Unicode 和 UTF-8 的转换规则,你可以参考一下。
Unicode中的正则
在你大概了解了Unicode的基础知识后,接下来我来给你讲讲,在用Unicode中可能会遇到的坑,以及其中的点号匹配和字符组匹配的问题。
编码问题的坑
如果你在编程语言中使用正则,编码问题可能会让正则的匹配行为很奇怪。先说结论,在使用时一定尽可能地使用Unicode编码。
如果你需要在Python语言中使用正则,我建议你使用Python3。如果你不得不使用Python2,一定要记得使用 Unicode 编码。在Python2中,一般是以u开头来表示Unicode。如果不加u,会导致匹配出现问题。比如我们在“极客”这个文本中查找“时间”。你可能会很惊讶,竟然能匹配到内容。
下面是Python语言示例:
# 测试环境 macOS/Linux/Windows, Python2.7
>>> import re
>>> re.search(r'[时间]', '极客') is not None
True
>>> re.findall(r'[时间]', '极客')
['\xe6']
# Windows下输出是 ['\xbc']
通过分析原因,我们可以发现,不使用Unicode编码时,正则会被编译成其它编码表示形式。比如,在macOS或Linux下,一般会编码成UTF-8,而在Windows下一般会编码成GBK。
下面是我在macOS上做的测试,“时间”这两个汉字表示成了UTF-8编码,正则不知道要每三个字节看成一组,而是把它们当成了6个单字符。
# 测试环境 macOS/Linux,Python 2.7
>>> import re
>>> re.compile(r'[时间]', re.DEBUG)
in
literal 230
literal 151
literal 182
literal 233
literal 151
literal 180
<_sre.SRE_Pattern object at 0x1053e09f0>
>>> re.compile(ur'[时间]', re.DEBUG)
in
literal 26102
literal 38388
<_sre.SRE_Pattern object at 0x1053f8710>
我们再看一下 “极客” 和 “时间” 这两个词语对应的UTF-8编码。你可以发现,这两个词语都含有 16进制表示的e6,而GBK编码时都含有16进制的bc,所以才会出现前面的表现。
下面是查看文本编码成UTF-8或GBK方式,以及编码的结果:
# UTF-8
>>> u'极客'.encode('utf-8')
'\xe6\x9e\x81\xe5\xae\xa2' # 含有 e6
>>> u'时间'.encode('utf-8')
'\xe6\x97\xb6\xe9\x97\xb4' # 含有 e6
# GBK
>>> u'极客'.encode('gbk')
'\xbc\xab\xbf\xcd' # 含有 bc
>>> u'时间'.encode('gbk')
'\xca\xb1\xbc\xe4' # 含有 bc
这也是前面我们花时间讲编码基础知识的原因,只有理解了编码的知识,你才能明白这些。在学习其它知识的时候也是一样的思路,不要去死记硬背,搞懂了底层原理,你自然就掌握了。因此在使用时,一定要指定 Unicode 编码,这样就可以正常工作了。
# Python2 或 Python3 都可以
>>> import re
>>> re.search(ur'[时间]', u'极客') is not None
False
>>> re.findall(ur'[时间]', u'极客')
[]
点号匹配
之前我们学过, 点号 可以匹配除了换行符以外的任何字符,但之前我们接触的大多是单字节字符。在Unicode中,点号可以匹配上Unicode字符么?这个其实情况比较复杂,不同语言支持的也不太一样,具体的可以通过测试来得到答案。
下面我给出了在Python和JavaScript测试的结果:
# Python 2.7
>>> import re
>>> re.findall(r'^.$', '学')
[]
>>> re.findall(r'^.$', u'学')
[u'\u5b66']
>>> re.findall(ur'^.$', u'学')
[u'\u5b66']
# Python 3.7
>>> import re
>>> re.findall(r'^.$', '学')
['学']
>>> re.findall(r'(?a)^.$', '学')
['学']
/* JavaScript(ES6) 环境 */
> /^.$/.test("学")
true
至于其它的语言里面能不能用,你可以自己测试一下。在这个课程里,我更多地是希望你掌握这些学习的方法和思路,而不是单纯地记住某个知识点,一旦掌握了方法,之后就会简单多了。
字符组匹配
之前我们学习了很多字符组,比如\d表示数字,\w表示大小写字母、下划线、数字,\s表示空白符号等,那 Unicode 下的数字,比如全角的1、2、3等,算不算数字呢?全角的空格算不算空白呢?同样,你可以用我刚刚说的方法,来测试一下你所用的语言对这些字符组的支持程度。
Unicode 属性
在正则中使用Unicode,还可能会用到Unicode的一些属性。这些属性把Unicode字符集划分成不同的字符小集合。
在正则中常用的有三种,分别是 按功能划分 的Unicode Categories(有的也叫 Unicode Property),比如标点符号,数字符号;按 连续区间划分 的Unicode Blocks,比如只是中日韩字符;按 书写系统划分 的Unicode Scripts,比如汉语中文字符。

在正则中如何使用这些Unicode属性呢?在正则中,这三种属性在正则中的表示方式都是\p{属性}。比如,我们可以使用 Unicode Script 来实现查找连续出现的中文。
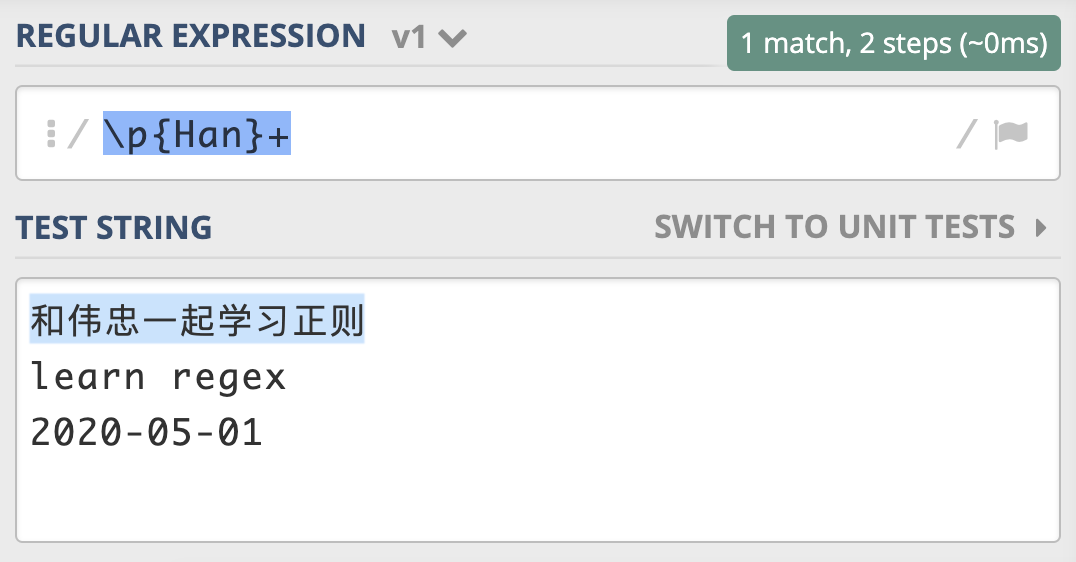
你可以在 这里 进行测试。
其中,Unicode Blocks在不同的语言中记法有差异,比如Java需要加上In前缀,类似于 \p{ In Bopomofo} 表示注音字符。
知道Unicode属性这些知识,基本上就够用了,在用到相关属性的时候,可以再查阅一下参考手册。如果你想知道Unicode属性更全面的介绍,可以看一下维基百科的对应链接。
表情符号
表情符号其实是“图片字符”,最初与日本的手机使用有关,在日文中叫“绘文字”,在英文中叫emoji,但现在从日本流行到了世界各地。不少同学在聊天的时候喜欢使用表情。下面是办公软件钉钉中一些表情的截图。

在2020 年 3 月 10 日公布的Unicode标准 13.0.0 中,新增了55个新的emoji表情,完整的表情列表你可以在这里查看 这个链接。
这些表情符号有如下特点。
- 许多表情不在BMP内,码值超过了 FFFF。使用 UTF-8编码时,普通的 ASCII 是1个字节,中文是3个字节,而有一些表情需要4个字节来编码。
- 这些表情分散在BMP和各个补充平面中,要想用一个正则来表示所有的表情符号非常麻烦,即便使用编程语言处理也同样很麻烦。
- 一些表情现在支持使用颜色修饰(Fitzpatrick modifiers),可以在5种色调之间进行选择。这样一个表情其实就是8个字节了。
在这里我给出了你有关于表情颜色修饰的5种色调,你可以看一看。
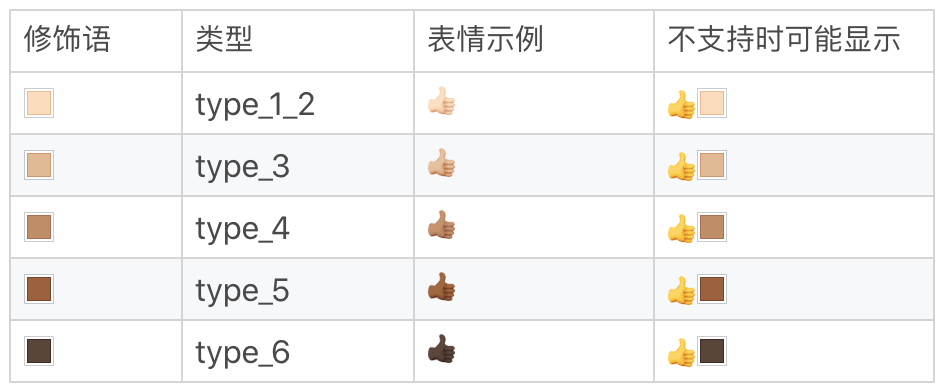
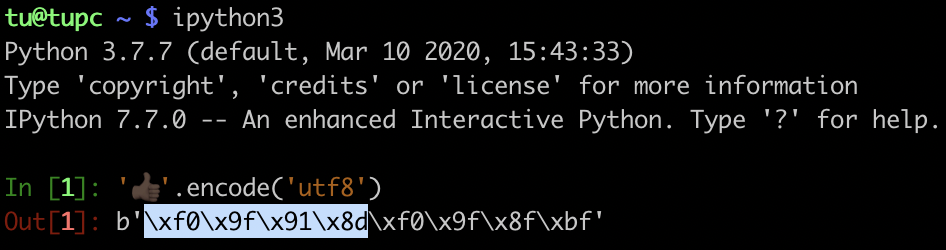
下面是使用IPython测试颜色最深的点赞表情,在macOS上的测试结果。你可以发现,它是由8个字节组成,这样用正则处理起来就很不方便了。因此,在处理表情符号时,我不建议你使用正则来处理。你可以使用专门的库,这样做一方面代码可读性更好,另一方面是表情在不断增加,使用正则的话不好维护,会给其它同学留坑。而使用专门的库可以通过升级版本来解决这个问题。
总结
好了,讲到这,今天的内容也就基本结束了。最后我来给你总结一下。
今天我们学习了Unicode编码的基础知识、了解了UTF-8编码、变长存储、以及它和Unicode的关系。Unicode字符按照功能,码值区间和书写系统等方式进行分类,比如按书写系统划分 \p{Han} 可以表示中文汉字。
在正则中使用Unicode有一些坑主要是因为编码问题,使用的时候你要弄明白是拿Unicode去匹配,还是编码后的某部分字节去进行匹配的,这可以让你避开这些坑。
而在处理表情时,由于表情比较复杂,我不建议使用正则来处理,更建议使用专用的表情库来处理。
课后思考
最后,我们来做一个小练习吧。在正则 xy{3} 中,你应该知道, y是重复3次,那如果正则是“极客{3}”的时候,代表是“客”这个汉字重复3次,还是“客”这个汉字对应的编码最后一个字节重复3次呢?如果是重复的最后一个字节,应该如何解决?
'极客{3}'
你可以自己来动动手,用自己熟悉的编程语言来试一试,经过不断练习你才能更好地掌握学习的内容。
今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,同时欢迎你把这节课分享给你的朋友或者同事,一起交流一下。
应用2:如何在编辑器中使用正则完成工作?
你好,我是伟忠。今天我来和你分享一下,在常见的编辑器中如何使用正则来完成工作。
你可能要问了,这是正则专栏,为啥不直接开始讲正则?其实我给你讲的编辑器使用技巧,能够帮助我们更好地完成工作。因为我们学习正则的目的,就是想高效地完成文本处理。
但在实际工作中,我们一般不会只用正则,而是通常将编辑器的特性和正则结合起来,这样可以让文本处理工作更加高效。正所谓“工欲善其事,必先利其器”,你花点时间来了解一下编辑器的各种特性,可以少写很多代码。
编辑器功能
接下来,我以Sublime Text 3 为例,给你讲讲一些在编辑器里的强大功能,这些功能在Sublime Text、Atom、VS Code、JetBrains 系列(IntelliJ IDEA/PyCharm/Goland等) 中都是支持的。
光标移动和文本选择
在常见的编辑器、IDE、甚至Chrome等浏览器中,我们编辑文本时,使用键盘的左右箭头移动光标,可以 按住Shift键 来选中文本。在左右移动时,如果你按住 Alt(macOS的option),你会发现光标可以“按块移动”,快速移动到下一个单词。两种方式组合起来,你可以快速选择引号里面的内容。

你可以动手练习一下,熟悉一下这些操作。你可能会说,有必要么,我用鼠标拖一下不就可以了?你说得没错,但这个功能和后面我要讲的多焦点编辑、竖向编辑等结合起来,就可以快速多行操作,这是鼠标做不到的。
多焦点编辑
在IDE中,我们如果想对某个变量或函数重命名,通常可以使用重构(refactor)功能。但如果处理的不是代码,而是普通文本,比如JSON字符串的时候,就没法这么用了。不过现在很多编辑器都提供了多焦点编辑的功能。
比如选择单词 route 之后,点击菜单 Find -> Quick Find All 就可以选中所有的 route 了。你可以进行多焦点编辑,非常方便。我给了你一个测试文本,你可以点击 这里 获取。
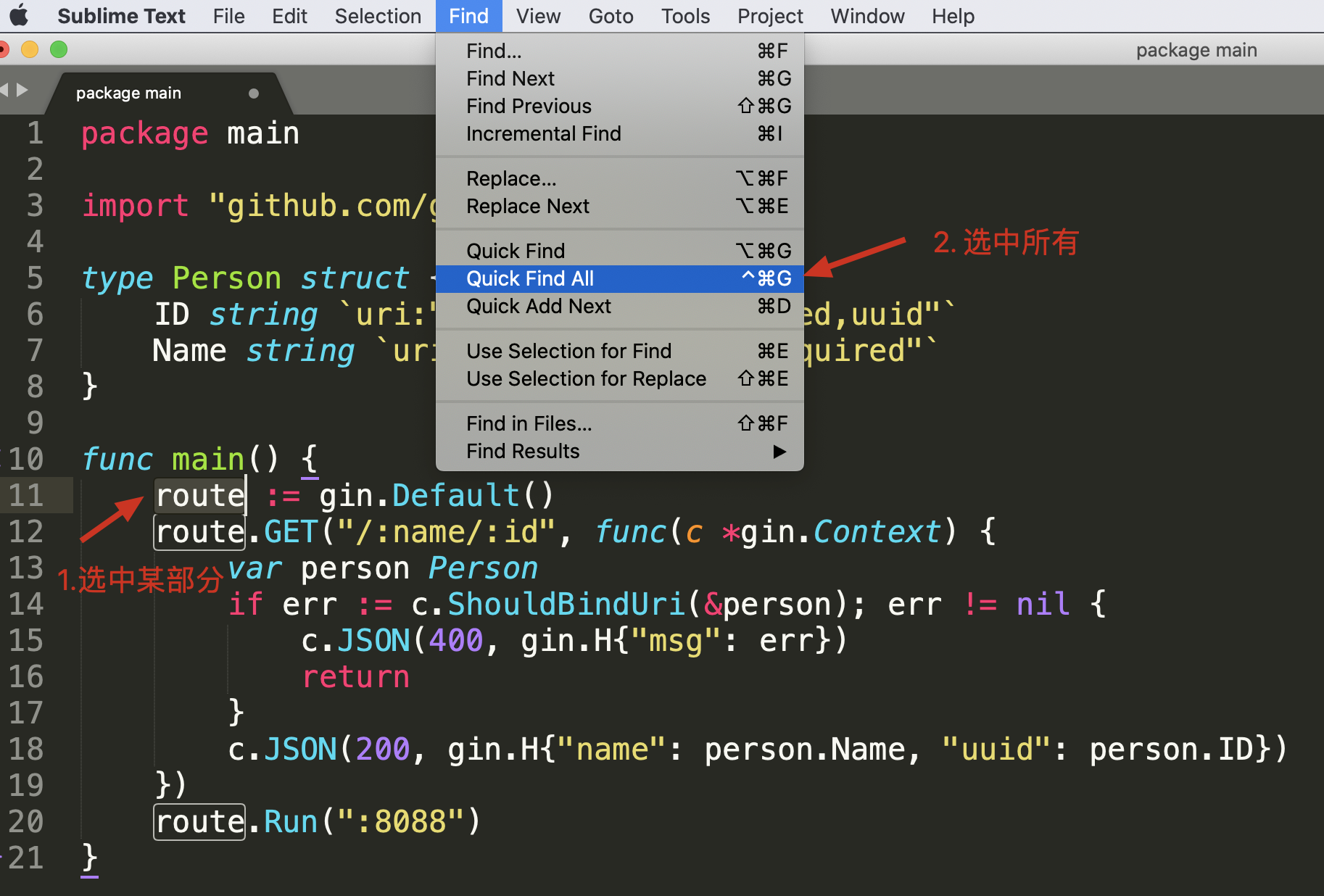
这个特性结合光标移动,可以快速提取某些内容,比如提取 JSON中的姓名和手机号。选中所有的字段和值之间的字符(": ") 之后,按住 Shift+Alt(macOS上是Shift + Option),用箭头移动光标,可以快速选择到另外一个引号前,然后剪切,再找个空白地方粘贴就可以了。
{
"error_code": 0,
"result": {
"data": [
{
"name": "朱小明",
"tel": "138xx138000"
},
{
"name": "王五",
"tel": "139xx139000"
}
]
}
}
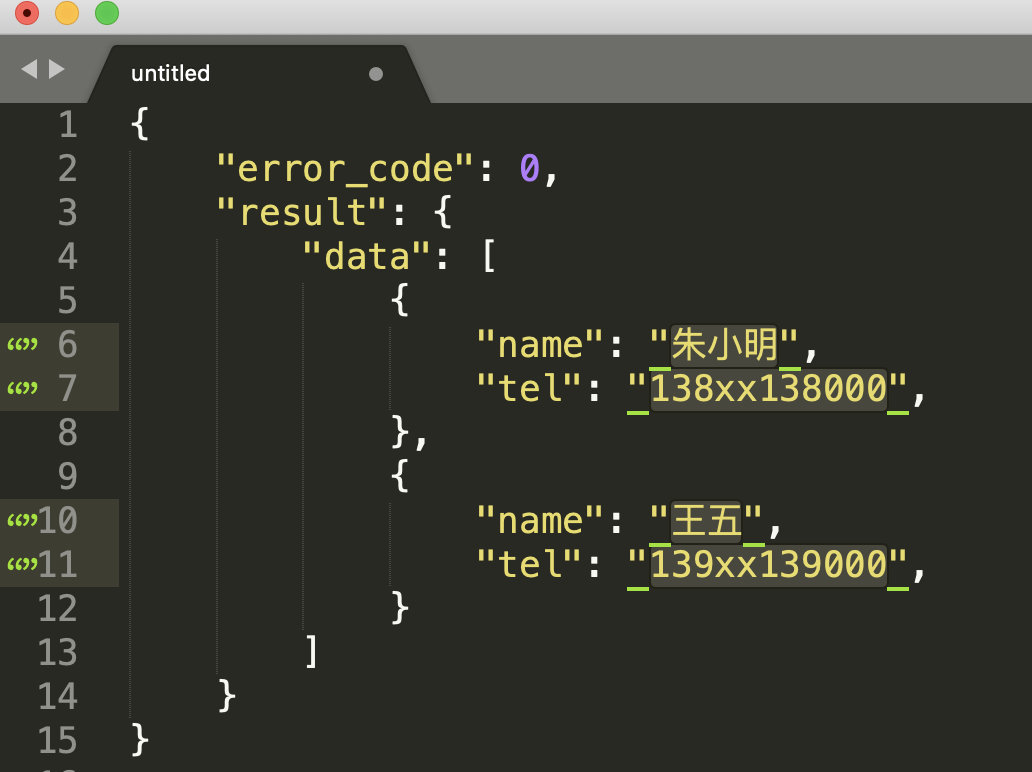
详细操作你可以看一下这个小视频。
竖向编辑
在编辑多行时,如果我们需要编辑的内容都是纵向上同一个位置,就可以使用 Alt (macOS上是 Option)加上鼠标拖拽的方式来选择(或者尝试按下鼠标中键拖拽)。比如下图,当你选择了左侧的两个空格之后,可以批量编辑,比如修改成四个空格。将竖向编辑和刚刚上面说到的光标移动结合起来,会非常方便。
在编辑器中使用正则
正则是一种文本处理工具,常见的功能有文本验证、文本提取、文本替换、文本切割等。有一些地方说的正则匹配,其实是包括了校验和提取两个功能。
校验常用于验证整个文本的组成是不是符合规则,比如密码规则校验。提取则是从大段的文本中抽取出需要的内容,比如提取网页上所有的链接。在使用正则进行内容提取时,要做到不能提取到错误的内容(准确性),不能漏掉正确的内容(完备性)。这就要求我们写正则的时候尽量考虑周全。但是考虑周全并不容易,需要我们不断地练习、思考和总结。
内容提取
我以编辑器 Sublime Text 3 为例来进行讲解,下图是编辑器 Sublime Text 查找界面的介绍。
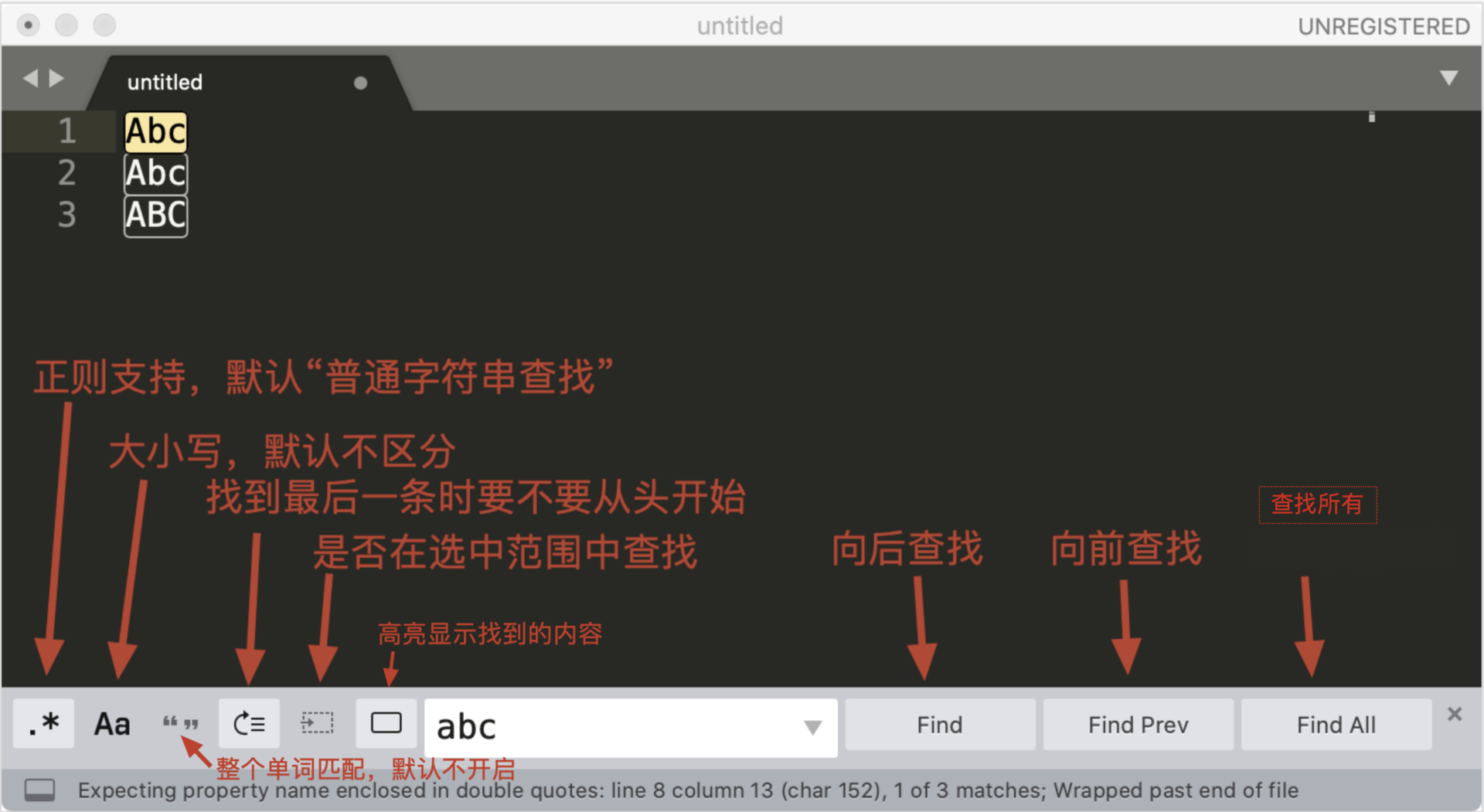
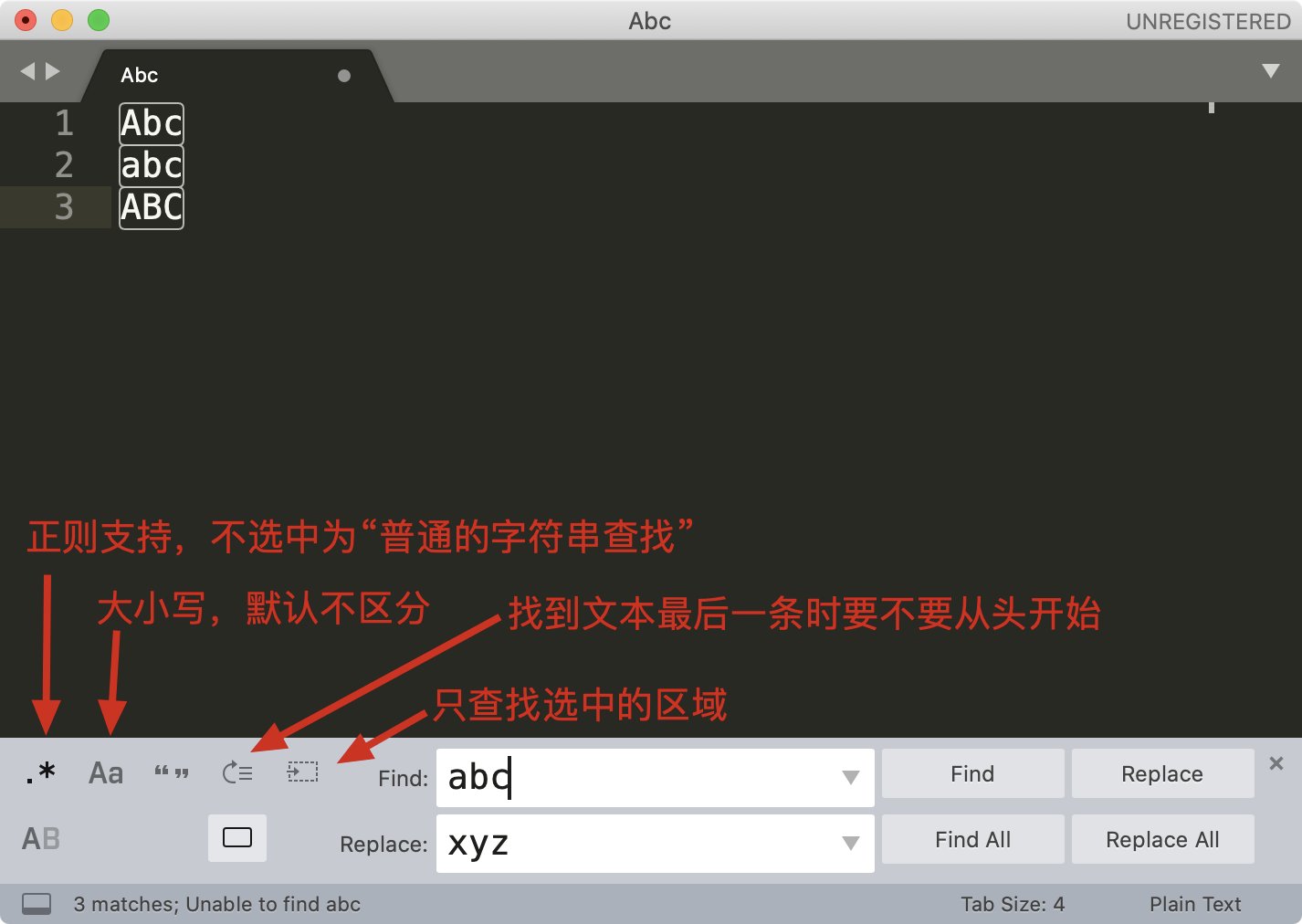
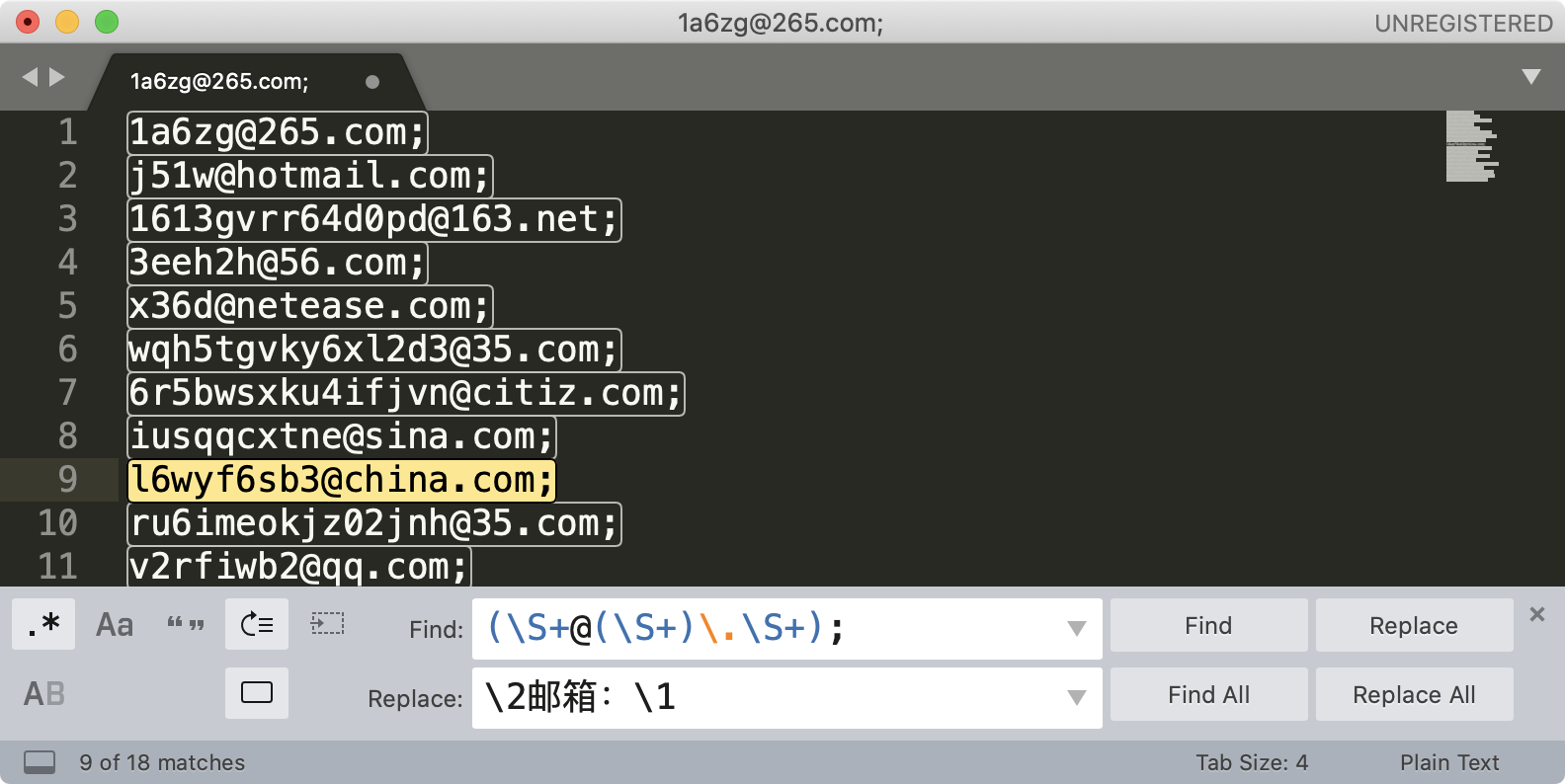
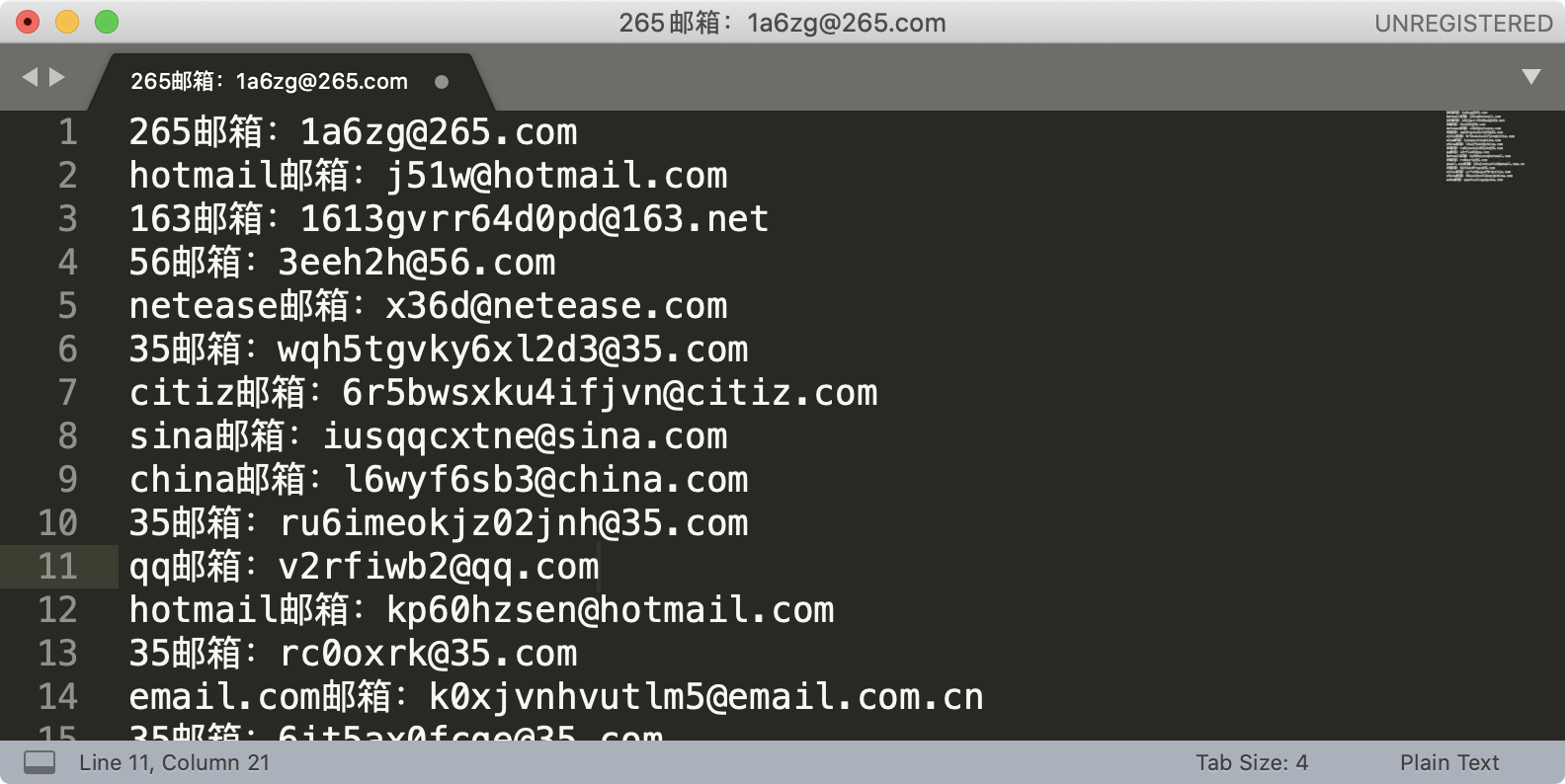
我们来尝试使用 sublime 提取文本中所有的邮箱地址,这里并不要求你写出一个完美的正则,因此演示时,使用 \S+@\S+\.\S+ 这个正则。另外我们可以加上环视,去掉尾部的分号。你可以 在这里 随机生成一些邮箱用于测试。
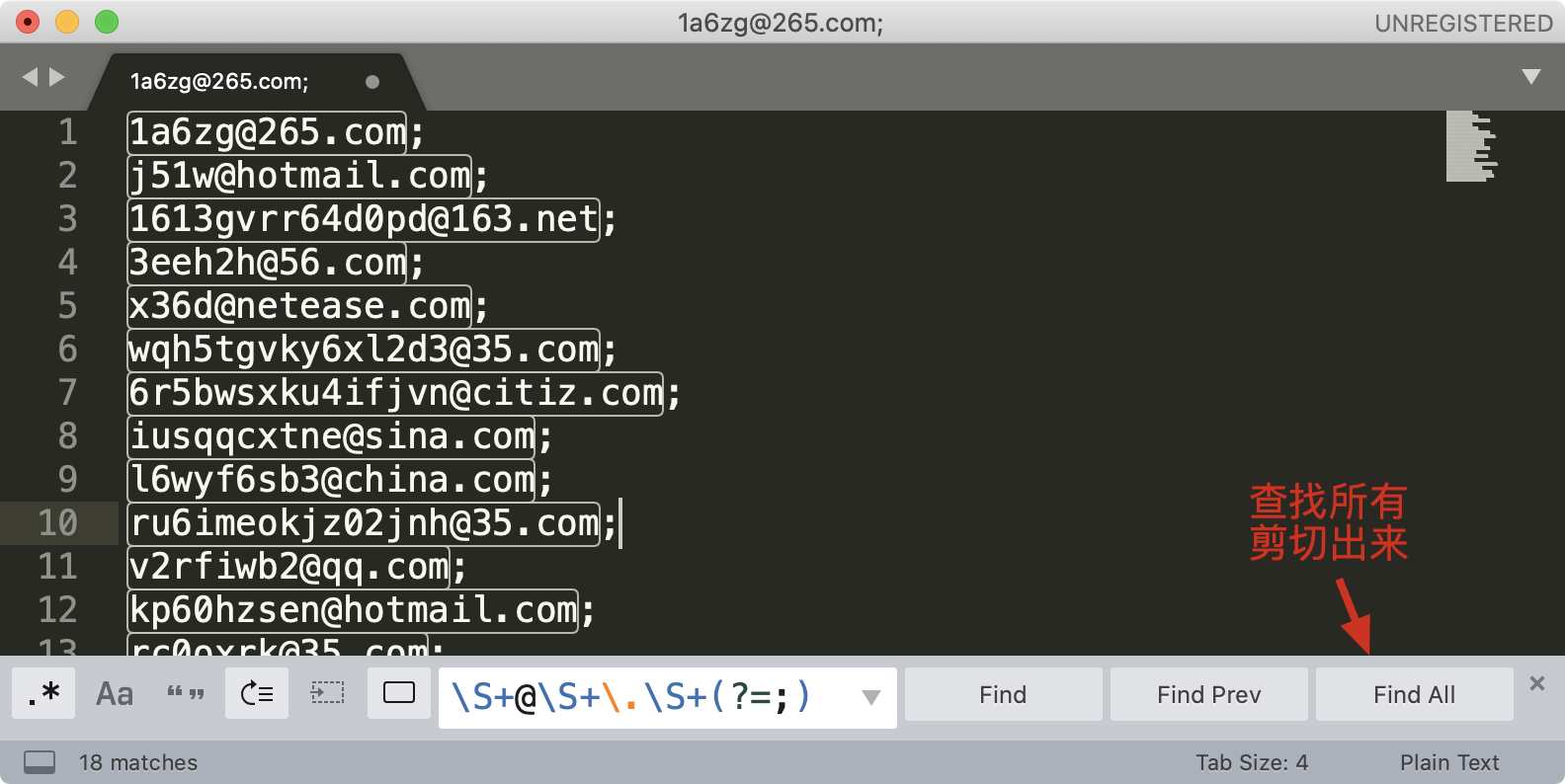
你可能会有疑问,我直接找到最后的分号,然后删除掉不就可以了么?这个例子是没问题的,但如果文本中除了邮箱之外,还有其它的内容这样就不行了,这也是正则比普通文本强大的地方。

内容替换
说完了查找,我们再来看一下替换。之前课程里我们也有讲过,这里再来回顾一下。下图是编辑器 Sublime Text 替换界面的介绍。
同样是上面邮箱的例子,我们可以使用子组和引用,直接替换得到移除了分号之后的邮箱,我们还可以在邮箱前把邮箱类型加上。操作前和操作后的示意图如下:
替换和提取的不同在于,替换可以对内容进行拼接和改造,而提取是从原来的内容中抽取出一个子集,不会改变原来的内容。当然在实际应用中,可以两个结合起来一起使用。
内容验证
在编辑器中进行内容验证,本质上和内容提取一样,只不过要求编辑器中全部内容都匹配上,并且匹配次数是一次。
内容切割
在编辑器中进行内容切割,本质上也和内容提取一样,用什么切割,我们就提取什么,选中全部之后,把选中的内容删除掉或者编辑成其它的字符。
刚刚我们讲解了在 Sublime Text 中使用正则处理文本的方法,其它的编辑器或IDE,如 Atom、VS Code、JetBrains系列(IntelliJ IDEA/PyCharm/Goland等)等,也都是类似的,你可以在自己喜欢的编辑器中练习一下今天讲到的内容。
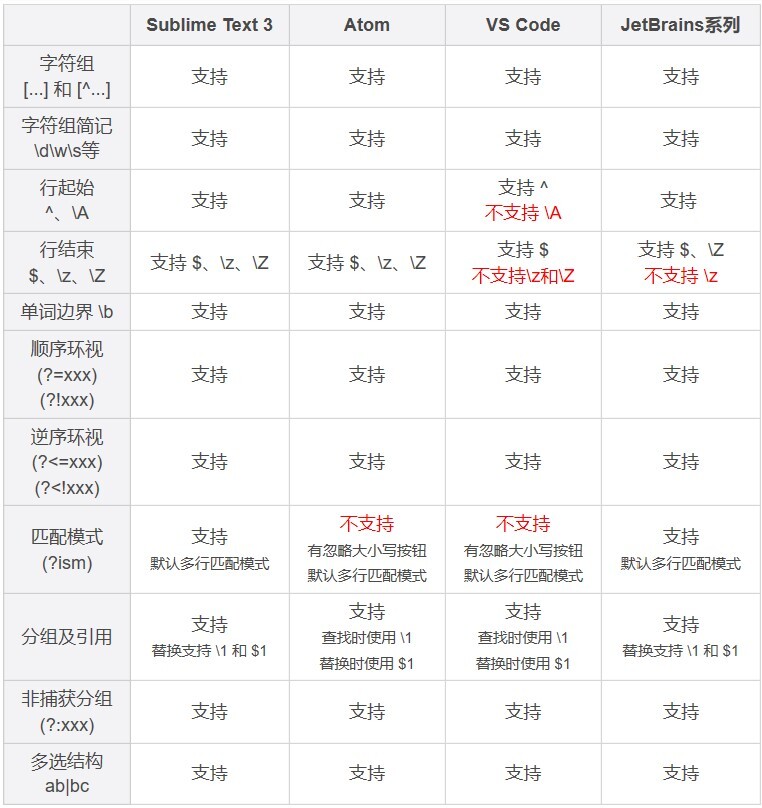
这里给出一些主流跨平台编辑器/IDE对正则的支持情况,你可以参考一下。
总结
好了,今天的内容讲完了,我来带你总结回顾一下。
今天我们学习了编辑器中一些提高文本处理效率的操作方式:光标移动和选择、多焦点编辑以及竖向编辑。学会了这些,即使不使用正则,我们在编辑器中处理文本效率也会大大提高。接着通过一些示例,我们学习了在编辑器中使用正则来进行文本内容提取,内容替换等操作。正则的使用一般会和其它的方法结合起来,最终帮助我们高效地完成文本的处理工作。
今天所讲的内容总结脑图如下,你可以回顾一下:
课后思考
最后,我们来做一个小练习吧:统计一篇英文文章中每个单词出现的次数,使用Sublime Text 等编辑器提取文章里所有的单词,处理成一行一个单词,保存到文件中,然后再使用sort、uniq 等命令统计单词出现的次数。
为了帮你更好地完成这个任务,你可以参考一下下面的提示:
- windows上的同学可以使用 git for windows 工具。
- 使用 uniq 前需要先用 sort 命令排序,uniq -c 可以统计次数。
sort words.txt | uniq -c
如果想取前10名,可以继续对结果排序
sort words.txt | uniq -c | sort -nrk1 | head -n10
至于为什么要加 n、r 和 k1 你可以通过 man sort 看一下说明
好,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,并把文章分享给你的朋友或者同事,一起交流一下。
应用3:如何在语言中用正则让文本处理能力上一个台阶?
你好,我是伟忠。今天要和你分享的内容是如何在编程语言中使用正则,让文本处理能力上一个台阶。
现代主流的编程语言几乎都内置了正则模块,很少能见到不支持正则的编程语言。学会在编程语言中使用正则,可以极大地提高文本的处理能力。
在进行文本处理时,正则解决的问题大概可以分成四类,分别是校验文本内容、提取文本内容、替换文本内容、切割文本内容。在这一节里,我会从功能分类出发,给你讲解在一些常见的编程语言中,如何正确地实现这些功能。
1.校验文本内容
我们先来看一下数据验证,通常我们在网页上输入的手机号、邮箱、日期等,都需要校验。校验的特点在于,整个文本的内容要符合正则,比如要求输入6位数字的时候,输入123456abc 就是不符合要求的。
下面我们以验证日期格式年月日为例子来讲解,比如2020-01-01,我们使用正则\d{4}-\d{2}-\d{2} 来验证。
Python
在 Python 中,正则的包名是 re,验证文本可以使用 re.match 或 re.search 的方法,这两个方法的区别在于,re.match 是从开头匹配的,re.search是从文本中找子串。下面是详细的解释:
# 测试环境 Python3
>>> import re
>>> re.match(r'\d{4}-\d{2}-\d{2}', '2020-06-01')
<re.Match object; span=(0, 10), match='2020-06-01'>
# 这个输出是匹配到了,范围是从下标0到下标10,匹配结果是2020-06-01
# re.search 输出结果也是类似的
在Python中,校验文本是否匹配的正确方式如下所示:
# 测试环境 Python3
>>> import re
>>> reg = re.compile(r'\A\d{4}-\d{2}-\d{2}\Z') # 建议先编译,提高效率
>>> reg.search('2020-06-01') is not None
True
>>> reg.match('2020-06-01') is not None # 使用match时\A可省略
True
如果不添加 \A 和 \Z 的话,我们就可能得到错误的结果。而造成这个错误的主要原因就是,没有完全匹配,而是部分匹配。至于为什么不推荐用 ^ 和 $,因为在多行模式下,它们的匹配行为会发现变化,相关内容在前面匹配模式中讲解过,要是忘记了你可以返回去回顾一下。
# 错误示范
>>> re.match(r'\d{4}-\d{2}-\d{2}', '2020-06-01abc') is not None
True
>>> re.search(r'\d{4}-\d{2}-\d{2}', 'abc2020-06-01') is not None
True
Go
Go语言(又称Golang)是Google开发的一种静态强类型、编译型、并发型,并具有垃圾回收功能的编程语言。在Go语言中,正则相关的包是 regexp,下面是一个完整可运行的示例。
package main
import (
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile(`\A\d{4}-\d{2}-\d{2}\z`)
// 输出 true
fmt.Println(re.MatchString("2020-06-01"))
}
保存成 main.go ,在配置好go环境的前提下,直接使用命令 go run main.go 运行。不方便本地搭建Go环境的同学,可以点击 这里 或 这里 进行在线运行测试。
另外,需要注意的是,和 Python 语言不同,在 Go 语言中,正则尾部断言使用的是 \z,而不是 \Z。
JavaScript
在JavaScript中没有 \A 和 \z,我们可以使用 ^ 和 $ 来表示每行的开头和结尾,默认情况下它们是匹配整个文本的开头或结尾(默认不是多行匹配模式)。在 JavaScript 中校验文本的时候,不要使用多行匹配模式,因为使用多行模式会改变 ^ 和 $ 的匹配行为。
JavaScript代码可以直接在浏览器的Console中很方便地测试。(进入方式:任意网页上点击鼠标右键,检查,Console)
// 方法1
/^\d{4}-\d{2}-\d{2}$/.test("2020-06-01") // true
// 方法2
var regex = /^\d{4}-\d{2}-\d{2}$/
"2020-06-01".search(regex) == 0 // true
// 方法3
var regex = new RegExp(/^\d{4}-\d{2}-\d{2}$/)
regex.test("2020-01-01") // tru
方法3本质上和方法1是一样的,方法1写起来更简洁。需要注意的是,在使用 RegExp 对象时,如果使用 g 模式,可能会有意想不到的结果,连续调用会出现第二次返回 false 的情况,就像下面这样:
var r = new RegExp(/^\d{4}-\d{2}-\d{2}$/, "g")
r.test("2020-01-01") // true
r.test("2020-01-01") // false
这是因为 RegExp 在全局模式下,正则会找出文本中的所有可能的匹配,找到一个匹配时会记下 lastIndex,在下次再查找时找不到,lastIndex变为0,所以才有上面现象。
var regex = new RegExp(/^\d{4}-\d{2}-\d{2}$/, "g")
regex.test("2020-01-01") // true
regex.lastIndex // 10
regex.test("2020-01-01") // false
regex.lastIndex // 0
// 为了加深理解,你可以看下面这个例子
var regex = new RegExp(/\d{4}-\d{2}-\d{2}/, "g")
regex.test("2020-01-01 2020-02-02") // true
regex.lastIndex // 10
regex.test("2020-01-01 2020-02-02") // true
regex.lastIndex // 21
regex.test("2020-01-01 2020-02-02") // false
由于我们这里是文本校验,并不需要找出所有的。所以要记住,JavaScript中文本校验在使用 RegExp 时不要设置 g 模式。
另外在ES6中添加了匹配模式 u,如果要在 JavaScript 中匹配中文等多字节的 Unicode 字符,可以指定匹配模式 u,比如测试是否为一个字符,可以是任意Unicode字符,详情可以参考下面的示例:
/^\u{1D306}$/u.test("𝌆") // true
/^\u{1D306}$/.test("𝌆") // false
/^.$/u.test("好") // true
/^.$/u.test("好人") // false
/^.$/u.test("a") // true
/^.$/u.test("ab") // false
Java
在 Java 中,正则相关的类在 java.util.regex 中,其中最常用的是 Pattern 和 Matcher, Pattern 是正则表达式对象,Matcher是匹配到的结果对象,Pattern 和 字符串对象关联,可以得到一个 Matcher。下面是 Java 中匹配的示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class Main {
public static void main(String[] args) {
//方法1,可以不加 \A 和 \z
System.out.println(Pattern.matches("\\d{4}-\\d{2}-\\d{2}", "2020-06-01")); // true
//方法2,可以不加 \A 和 \z
System.out.println("2020-06-01".matches("\\d{4}-\\d{2}-\\d{2}")); // true
//方法3,必须加上 \A 和 \z
Pattern pattern = Pattern.compile("\\A\\d{4}-\\d{2}-\\d{2}\\z");
System.out.println(pattern.matcher("2020-06-01").find()); // true
}
}
Java 中目前还没有原生字符串,在之前转义一节讲过,正则需要经过字符串转义和正则转义两个步骤,因此在用到反斜扛的地方,比如表示数字的 \d,就得在字符串中表示成 \\d,转义会让书写正则变得稍微麻烦一些,在使用的时候需要留意一下。
部分常见编程语言校验文本方式,你可以参考下面的表。

2.提取文本内容
我们再来看一下文本内容提取,所谓内容提取,就是从大段的文本中抽取出我们关心的内容。比较常见的例子是网页爬虫,或者说从页面上提取邮箱、抓取需要的内容等。如果要抓取的是某一个网站,页面样式是一样的,要提取的内容都在同一个位置,可以使用 xpath 或 jquery选择器 等方式,否则就只能使用正则来做了。
下面我们来讲解一下具体的例子,让你了解一下正则提取文本在一些常见的编程语言中的使用。
Python
在 Python 中提取内容最简单的就是使用 re.findall 方法了,当有子组的时候,会返回子组的内容,没有子组时,返回整个正则匹配到的内容。下面我以查找日志的年月为例进行讲解,年月可以用正则 \d{4}-\d{2} 来表示:
# 没有子组时
>>> import re
>>> reg = re.compile(r'\d{4}-\d{2}')
>>> reg.findall('2020-05 2020-06')
['2020-05', '2020-06']
# 有子组时
>>> reg = re.compile(r'(\d{4})-(\d{2})')
>>> reg.findall('2020-05 2020-06')
[('2020', '05'), ('2020', '06')]
通过上面的示例你可以看到,直接使用 findall 方法时,它会把结果存储到一个列表(数组)中,一下返回所有匹配到的结果。如果想节约内存,可以采用迭代器的方式来处理,就像下面这样:
>>> import re
>>> reg = re.compile(r'(\d{4})-(\d{2})')
>>> for match in reg.finditer('2020-05 2020-06'):
... print('date: ', match[0]) # 整个正则匹配到的内容
... print('year: ', match[1]) # 第一个子组
... print('month:', match[2]) # 第二个子组
...
date: 2020-05
year: 2020
month: 05
date: 2020-06
year: 2020
month: 06
这样我们就可以实现正则找到一个,在程序中处理一个,不需要将找到的所有结果构造成一个数组(Python中的列表)。
Go
在 Go语言里面,查找也非常简洁,可以直接使用 FindAllString 方法。如果我们想捕获子组,可以使用 FindAllStringSubmatch 方法。
package main
import (
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile(`\d{4}-\d{2}`)
// 返回一个切片(可动态扩容的数组) [2020-06 2020-07]
fmt.Println(re.FindAllString("2020-06 2020-07", -1))
// 捕获子组的查找示例
re2 := regexp.MustCompile(`(\d{4})-(\d{2})`)
// 返回结果和上面 Python 类似
for _, match := range re2.FindAllStringSubmatch("2020-06 2020-07", -1) {
fmt.Println("date: ", match[0])
fmt.Println("year: ", match[1])
fmt.Println("month:", match[2])
}
}
JavaScript
在 JavaScript 中,想要提取文本中所有符合要求的内容,正则必须使用 g 模式,否则找到第一个结果后,正则就不会继续向后查找了。
// 使用g模式,查找所有符合要求的内容
"2020-06 2020-07".match(/\d{4}-\d{2}/g)
// 输出:["2020-06", "2020-07"]
// 不使用g模式,找到第一个就会停下来
"2020-06 2020-07".match(/\d{4}-\d{2}/)
// 输出:["2020-06", index: 0, input: "2020-06 2020-07", groups: undefined]
如果要查找中文等Unicode字符,可以使用 u 匹配模式,下面是具体的示例。
'𝌆'.match(/\u{1D306}/ug) // 使用匹配模式u
["𝌆"]
'𝌆'.match(/\u{1D306}/g) // 不使用匹配模式u
null
// 如果你对这个符号感兴趣,可以参考 https://unicode-table.com/cn/1D306
Java
在 Java 中,可以使用 Matcher 的 find 方法来获取查找到的内容,就像下面这样:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class Main {
public static void main(String[] args) {
Pattern pattern = Pattern.compile("\\d{4}-\\d{2}");
Matcher match = pattern.matcher("2020-06 2020-07");
while (match.find()) {
System.out.println(match.group());
}
}
}
部分常见编程语言提取文本方式,你可以参考下面的表。

3.替换文本内容
我们接着来看一下文本内容替换,替换通常用于对原来的文本内容进行一些调整。之前我们也讲解过一些使用正则进行替换的例子,今天我们再来了解一下在部分常见的编程语言中,使用正则进行文本替换的方法。
Python
在 Python 中替换相关的方法有 re.sub 和 re.subn,后者会返回替换的次数。下面我以替换年月的格式为例进行讲解,假设原始的日期格式是月日年,我们要将其处理成 xxxx年xx月xx日的格式。你可以看到,在Python中正则替换操作相关的方法,使用起来非常地简单。
>>> import re
>>> reg = re.compile(r'(\d{2})-(\d{2})-(\d{4})')
>>> reg.sub(r'\3年\1月\2日', '02-20-2020 05-21-2020')
'2020年02月20日 2020年05月21日'
# 可以在替换中使用 \g<数字>,如果分组多于10个时避免歧义
>>> reg.sub(r'\g<3>年\g<1>月\g<2>日', '02-20-2020 05-21-2020')
'2020年02月20日 2020年05月21日'
# 返回替换次数
>>> reg.subn(r'\3年\1月\2日', '02-20-2020 05-21-2020')
('2020年02月20日 2020年05月21日', 2)
Go
在 Go语言里面,替换和Python也非常类似,只不过子组是使用 ${num} 的方式来表示的。
package main
import (
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile(`(\d{2})-(\d{2})-(\d{4})`)
// 示例一,返回 2020年02月20日 2020年05月21日
fmt.Println(re.ReplaceAllString("02-20-2020 05-21-2020", "${3}年${1}月${2}日"))
// 示例二,返回空字符串,因为"3年","1月","2日" 这样的子组不存在
fmt.Println(re.ReplaceAllString("02-20-2020 05-21-2020", "$3年$1月$2日"))
// 示例三,返回 2020-02-20 2020-05-21
fmt.Println(re.ReplaceAllString("02-20-2020 05-21-2020", "$3-$1-$2"))
}
需要你注意的是,不建议把 ${num} 写成不带花括号的 $ num,比如示例二中的错误,会让人很困惑,Go认为子组是 “3年”,“1月”,“2日”。 由于这样的子组不存在,最终替换成了空字符串,所以使用的时候要注意这一点。
JavaScript
在 JavaScript 中替换和查找类似,需要指定 g 模式,否则只会替换第一个,就像下面这样。
// 使用g模式,替换所有的
"02-20-2020 05-21-2020".replace(/(\d{2})-(\d{2})-(\d{4})/g, "$3年$1月$2日")
// 输出 "2020年02月20日 2020年05月21日"
// 不使用 g 模式时,只替换一次
"02-20-2020 05-21-2020".replace(/(\d{2})-(\d{2})-(\d{4})/, "$3年$1月$2日")
// 输出 "2020年02月20日 05-21-2020"
Java
在 Java 中,一般是使用 replaceAll 方法进行替换,一次性替换所有的匹配到的文本。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class Main {
public static void main(String[] args) {
//方法1,输出 2020年02月20日 2020年05月21日
System.out.println("02-20-2020 05-21-2020".replaceAll("(\\d{2})-(\\d{2})-(\\d{4})", "$3年$1月$2日"));
//方法2,输出 2020年02月20日 2020年05月21日
final Pattern pattern = Pattern.compile("(\\d{2})-(\\d{2})-(\\d{4})");
Matcher match = pattern.matcher("02-20-2020 05-21-2020");
System.out.println(match.replaceAll("$3年$1月$2日"));
}
}
部分常见编程语言替换文本方式,你可以参考下面的表。

4.切割文本内容
我们最后再来看一下文本内容切割,通常切割用于变长的空白符号,多变的标点符号等。
下面我们来讲解一下具体的例子,让你了解一下正则切割文本在部分常见编程语言中的使用。
Python
在 Python 中切割相关的方法是 re.split。如果我们有按照任意空白符切割的需求,可以直接使用字符串的 split 方法,不传任何参数时就是按任意连续一到多个空白符切割。
# 使用字符串的切割方法
>>> "a b c\n\nd\t\n \te".split()
['a', 'b', 'c', 'd', 'e']
使用正则进行切割,比如我们要通过标点符号切割,得到所有的单词(这里简单使用非单词组成字符来表示)。
>>> import re
>>> reg = re.compile(r'\W+')
>>> reg.split("apple, pear! orange; tea")
['apple', 'pear', 'orange', 'tea']
# 限制切割次数,比如切一刀,变成两部分
>>> reg.split("apple, pear! orange; tea", 1)
['apple', 'pear! orange; tea']
Go
在 Go语言里面,切割是 Split 方法,和 Python 非常地类似,只不过Go语言中这个方法的第二个参数是必传的,如果不限制次数,我们传入 -1 即可。
package main
import (
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile(`\W+`)
// 返回 []string{"apple", "pear", "orange", "tea"}
fmt.Printf("%#v", re.Split("apple, pear! orange; tea", -1)
}
但在Go语言中,有个地方和 Python 不太一样,就是传入的第二个参数代表切割成几个部分,而不是切割几刀。
// 返回 []string{"apple", "pear! orange; tea"}
fmt.Printf("%#v\n", re.Split("apple, pear! orange; tea", 2))
// 返回 []string{"apple"}
fmt.Printf("%#v\n", re.Split("apple", 2))
这里有一个 在线测试链接,你可以尝试一下。
JavaScript
在 JavaScript 中,正则的切割和刚刚讲过的 Python 和 Go 有些类似,但又有区别。当第二个参数是2的时候,表示切割成2个部分,而不是切2刀(Go和Java也是类似的),但数组的内容不是 apple 后面的剩余部分,而是全部切割之后的 pear,你可以注意比较一下。
"apple, pear! orange; tea".split(/\W+/)
// 输出:["apple", "pear", "orange", "tea"]
// 传入第二个参数的情况
"apple, pear! orange; tea".split(/\W+/, 1)
// 输出 ["apple"]
"apple, pear! orange; tea".split(/\W+/, 2)
// 输出 ["apple", "pear"]
"apple, pear! orange; tea".split(/\W+/, 10)
// 输出 ["apple", "pear", "orange", "tea"]
Java
Java中切割也是类似的,由于没有原生字符串,转义稍微麻烦点。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class Main {
public static void main(String[] args) {
Pattern pattern = Pattern.compile("\\W+");
for(String s : pattern.split("apple, pear! orange; tea")) {
System.out.println(s);
}
}
}
在 Java 中,也可以传入第二个参数,类似于 Go 的结果。
pattern.split("apple, pear! orange; tea", 2)
// 返回 "apple" 和 "pear! orange; tea"
部分常见编程语言切割文本方式,你可以参考下面的表。

总结
好了,今天的内容讲完了,我来带你总结回顾一下。
今天我们学习了正则解决的问题大概可以分成四类,分别是校验文本内容、提取文本内容、替换文本内容、切割文本内容。从这四个功能出发,我们学习了在一些常见的编程语言中,如何正确地使用相应的方法来实现这些功能。这些方法都比较详细,希望你能够认真练习,掌握好这些方法。
我给你总结了一个今天所讲内容的详细脑图,你可以长按保存下来,经常回顾一下:
课后思考
最后,我们来做一个小练习吧。很多网页为了防止爬虫,喜欢把邮箱里面的 @ 符号替换成 # 符号,你可以写一个正则,兼容一下这种情况么?
例如网页的底部可能是这样的:
联系邮箱:xxx#163.com (请把#换成@)
你可以试试自己动手,使用你熟悉的编程语言,测试一下你写的正则能不能提取出这种“防爬”的邮箱。
好,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,并把文章分享给你的朋友或者同事,一起交流一下。
如何理解正则的匹配原理以及优化原则?
你好,我是伟忠,这一节课我们一起来学习正则匹配原理相关的内容,以及在书写正则时的一些优化方法。
这节课我主要给你讲解一下正则匹配过程,回顾一下之前讲的回溯,以及 DFA 和 NFA 引擎的工作方式,方便你明白正则是如何进行匹配的。这些原理性的知识,能够帮助我们快速理解为什么有些正则表达式不符合预期,也可以避免一些常见的错误。只有了解正则引擎的工作原理,我们才可以更轻松地写出正确的,性能更好的正则表达式。
有穷状态自动机
正则之所以能够处理复杂文本,就是因为采用了 有穷状态自动机( finite automaton)。 那什么是有穷自动机呢?有穷状态是指一个系统具有有穷个状态,不同的状态代表不同的意义。自动机是指系统可以根据相应的条件,在不同的状态下进行转移。从一个初始状态,根据对应的操作(比如录入的字符集)执行状态转移,最终达到终止状态(可能有一到多个终止状态)。
有穷自动机的具体实现称为正则引擎,主要有 DFA 和 NFA 两种,其中 NFA 又分为传统的NFA 和POSIX NFA。
DFA:确定性有穷自动机(Deterministic finite automaton)
NFA:非确定性有穷自动机(Non-deterministic finite automaton)
接下来我们来通过一些示例,来详细看下正则表达式的匹配过程。
正则的匹配过程
在使用到编程语言时,我们经常会“编译”一下正则表达式,来提升效率,比如在 Python3 中它是下面这样的:
>>> import re
>>> reg = re.compile(r'a(?:bb)+a')
>>> reg.findall('abbbba')
['abbbba']
这个编译的过程,其实就是生成自动机的过程,正则引擎会拿着这个自动机去和字符串进行匹配。生成的自动机可能是这样的(下图是使用 Regexper工具 生成,再次加工得到的)。
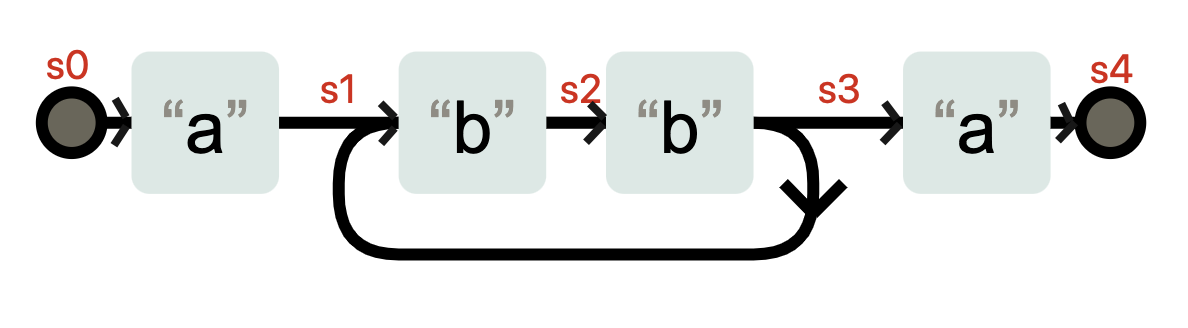
在状态 s3 时,不需要输入任何字符,状态也有可能转换成 s1。你可以理解成 a(bb)+a 在匹配了字符 abb 之后,到底在 s3 状态,还是在 s1 状态,这是不确定的。这种状态机就是非确定性有穷状态自动机(Non-deterministic finite automaton 简称NFA)。
NFA和DFA是可以相互转化的, 当我们把上面的状态表示成下面这样,就是一台DFA状态机了,因为在 s0-s4 这几个状态,每个状态都需要特定的输入,才能发生状态变化。
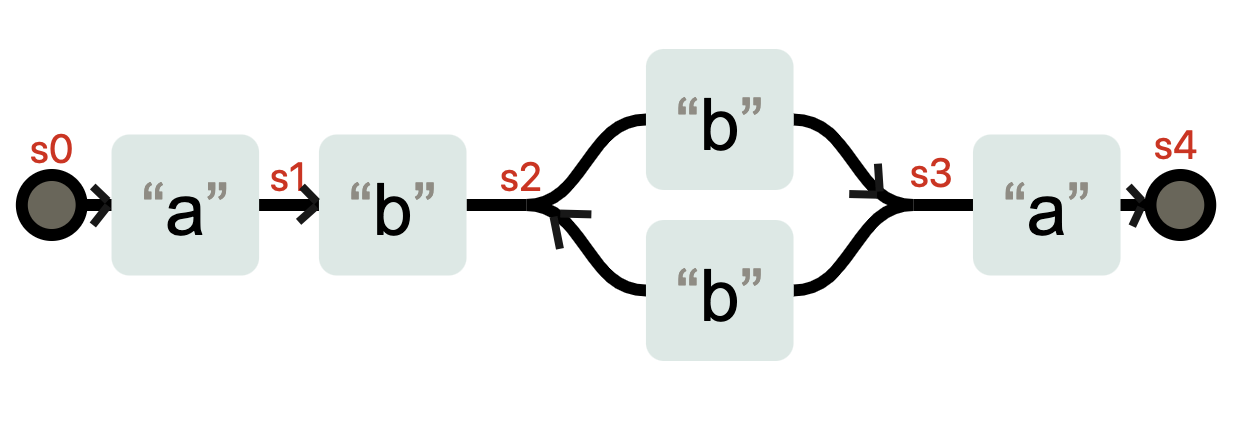
那这两种状态机的工作方式到底有什么不同呢?我们接着往下看。
DFA& NFA 工作机制
下面我通过一个示例,来简单说明 NFA 与 DFA 引擎工作方式的区别:
字符串:we study on jikeshijian app
正则:jike(zhushou|shijian|shixi)
NFA引擎的工作方式是,先看正则,再看文本,而且以正则为主导。正则中的第一个字符是j,NFA引擎在字符串中查找 j,接着匹配其后是否为 i ,如果是 i 则继续,这样一直找到 jike。
regex: jike(zhushou|shijian|shixi)
^
text: we study on jikeshijian app
^
我们再根据正则看文本后面是不是 z,发现不是,此时 zhushou 分支淘汰。
regex: jike(zhushou|shijian|shixi)
^
淘汰此分支(zhushou)
text: we study on jikeshijian app
^
我们接着看其它的分支,看文本部分是不是 s,直到 shijian 整个匹配上。shijian 在匹配过程中如果不失败,就不会看后面的 shixi 分支。当匹配上了 shijian 后,整个文本匹配完毕,也不会再看 shixi 分支。
假设这里文本改一下,把 jikeshijian 变成 jikeshixi,正则 shi j ian 的 j 匹配不上时shixi 的 x,会接着使用正则 shixi 来进行匹配,重新从 s 开始(NFA引擎会记住这里)。
第二个分支匹配失败
regex: jike(zhushou|shijian|shixi)
^
淘汰此分支(正则j匹配不上文本x)
text: we study on jikeshixi app
^
再次尝试第三个分支
regex: jike(zhushou|shijian|shixi)
^
text: we study on jikeshixi app
^
也就是说, NFA 是以正则为主导,反复测试字符串,这样字符串中同一部分,有可能被反复测试很多次。
而 DFA 不是这样的,DFA 会先看文本,再看正则表达式,是以文本为主导的。在具体匹配过程中,DFA 会从 we 中的 w 开始依次查找 j,定位到 j ,这个字符后面是 i。所以我们接着看正则部分是否有 i ,如果正则后面是个 i ,那就以同样的方式,匹配到后面的 ke。
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^
继续进行匹配,文本 e 后面是字符 s ,DFA 接着看正则表达式部分,此时 zhushou 分支被淘汰,开头是s的分支 shijian 和 shixi 符合要求。
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^ ^ ^
淘汰 符合 符合
然后 DFA 依次检查字符串,检测到 shijian 中的 j 时,只有 shijian 分支符合,淘汰 shixi,接着看分别文本后面的 ian,和正则比较,匹配成功。
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^ ^
符合 淘汰
从这个示例你可以看到,DFA 和 NFA 两种引擎的工作方式完全不同。NFA 是以表达式为主导的,先看正则表达式,再看文本。而 DFA 则是以文本为主导,先看文本,再看正则表达式。
一般来说,DFA 引擎会更快一些,因为整个匹配过程中,字符串只看一遍,不会发生回溯,相同的字符不会被测试两次。也就是说DFA 引擎执行的时间一般是线性的。DFA 引擎可以确保匹配到可能的最长字符串。但由于 DFA 引擎只包含有限的状态,所以它没有反向引用功能;并且因为它不构造显示扩展,它也不支持捕获子组。
NFA 以表达式为主导,它的引擎是使用贪心匹配回溯算法实现。NFA 通过构造特定扩展,支持子组和反向引用。但由于 NFA 引擎会发生回溯,即它会对字符串中的同一部分,进行很多次对比。因此,在最坏情况下,它的执行速度可能非常慢。
POSIX NFA 与 传统 NFA 区别
因为传统的 NFA 引擎“急于”报告匹配结果,找到第一个匹配上的就返回了,所以可能会导致还有更长的匹配未被发现。比如使用正则 pos|posix 在文本 posix 中进行匹配,传统的 NFA 从文本中找到的是 pos,而不是 posix,而 POSIX NFA 找到的是 posix。
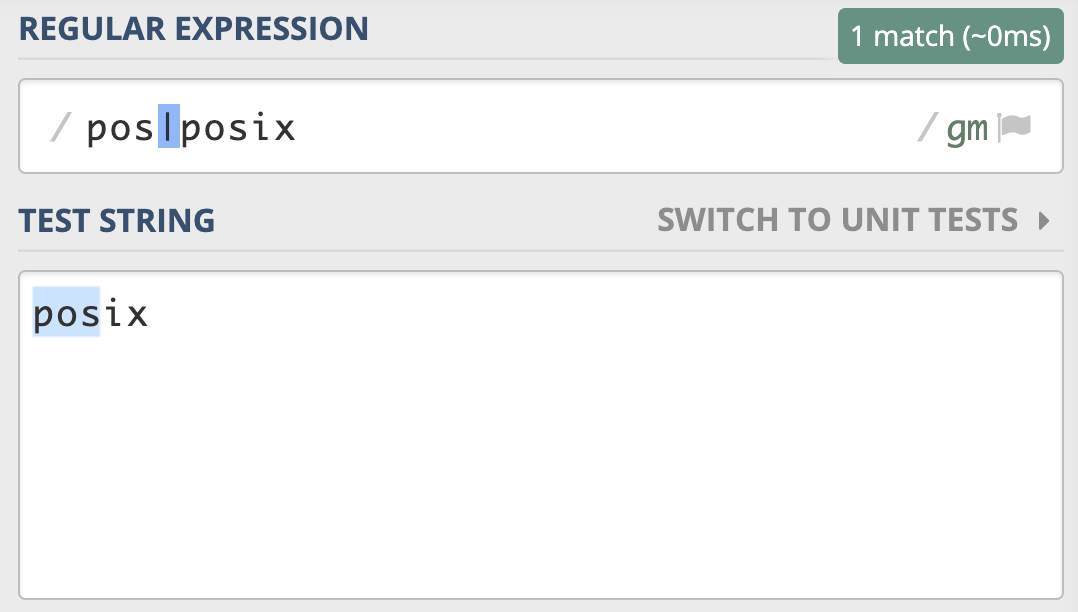
POSIX NFA的应用很少,主要是 Unix/Linux 中的某些工具。POSIX NFA 引擎与传统的 NFA 引擎类似,但不同之处在于,POSIX NFA 在找到可能的最长匹配之前会继续回溯,也就是说它会尽可能找最长的,如果分支一样长,以最左边的为准(“The Longest-Leftmost”)。因此,POSIX NFA 引擎的速度要慢于传统的 NFA 引擎。
我们日常面对的,一般都是传统的NFA,所以通常都是最左侧的分支优先,在书写正则的时候务必要注意这一点。
下面是 DFA、传统NFA 以及 POSIX NFA 引擎的特点总结:

回溯
回溯是 NFA引擎才有的,并且只有在正则中出现 量词 或 多选分支结构 时,才可能会发生回溯。
比如我们使用正则 a+ab 来匹配 文本 aab 的时候,过程是这样的,a+是贪婪匹配,会占用掉文本中的两个 a,但正则接着又是 a,文本部分只剩下 b,只能通过回溯,让 a+ 吐出一个 a,再次尝试。
如果正则是使用 .*ab 去匹配一个比较长的字符串就更糟糕了,因为 .* 会吃掉整个字符串(不考虑换行,假设文本中没有换行),然后,你会发现正则中还有 ab 没匹配到内容,只能将 .* 匹配上的字符串吐出一个字符,再尝试,还不行,再吐出一个,不断尝试。

所以在工作中,我们要尽量不用 .\* ,除非真的有必要,因为点能匹配的范围太广了,我们要尽可能精确。常见的解决方式有两种,比如要提取引号中的内容时,使用 “ [^"]+”,或者使用非贪婪的方式 “ .+?”,来减少“匹配上的内容不断吐出,再次尝试”的过程。
我们再回头看一下之前讲解的店铺名匹配示例:
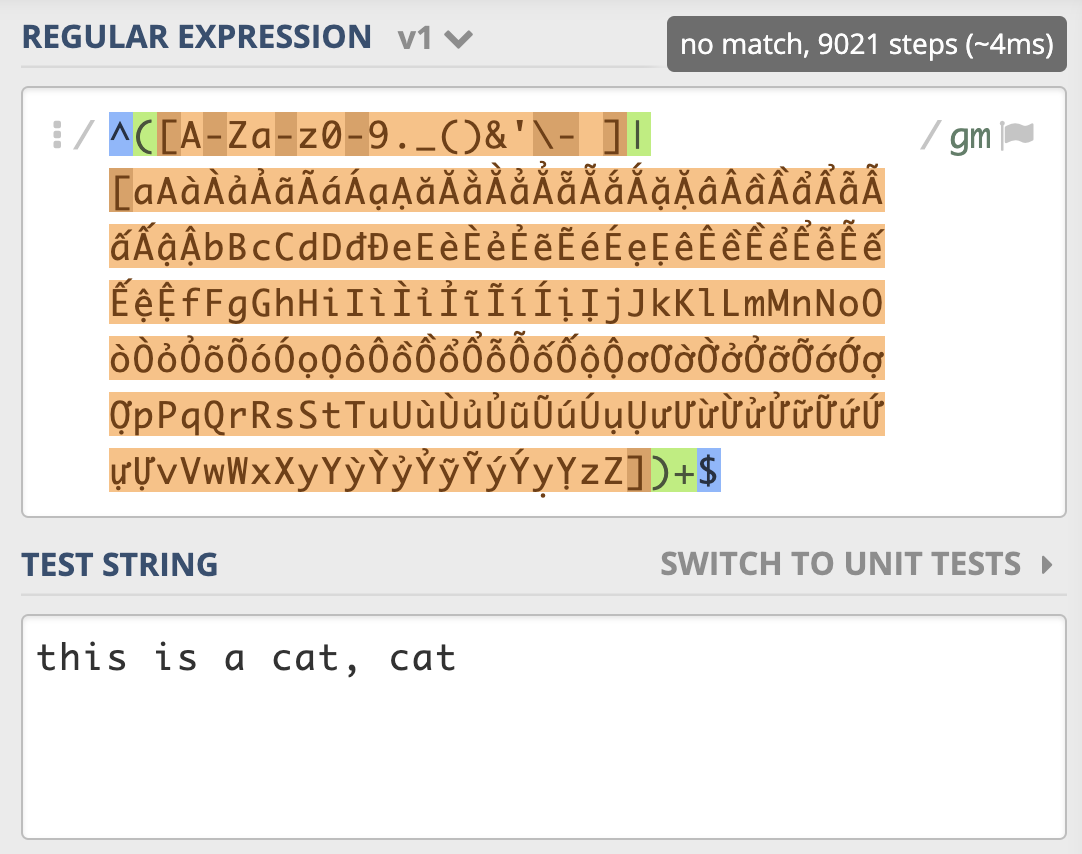
从 示例 我们可以看到,一个很短的字符串,NFA引擎尝试步骤达到了 9021 次,由于是贪婪匹配,第一个分支能匹配上 this is a cat 部分,接着后面的逗号匹配失败,使用第二个分支匹配,再次失败,此时贪婪匹配部分结束。NFA引擎接着用正则后面的 $ 来进行匹配,但此处不是文本结尾,匹配不上,发生回溯,吐出第一个分支匹配上的 t,使用第二个分支匹配 t 再试,还是匹配不上。
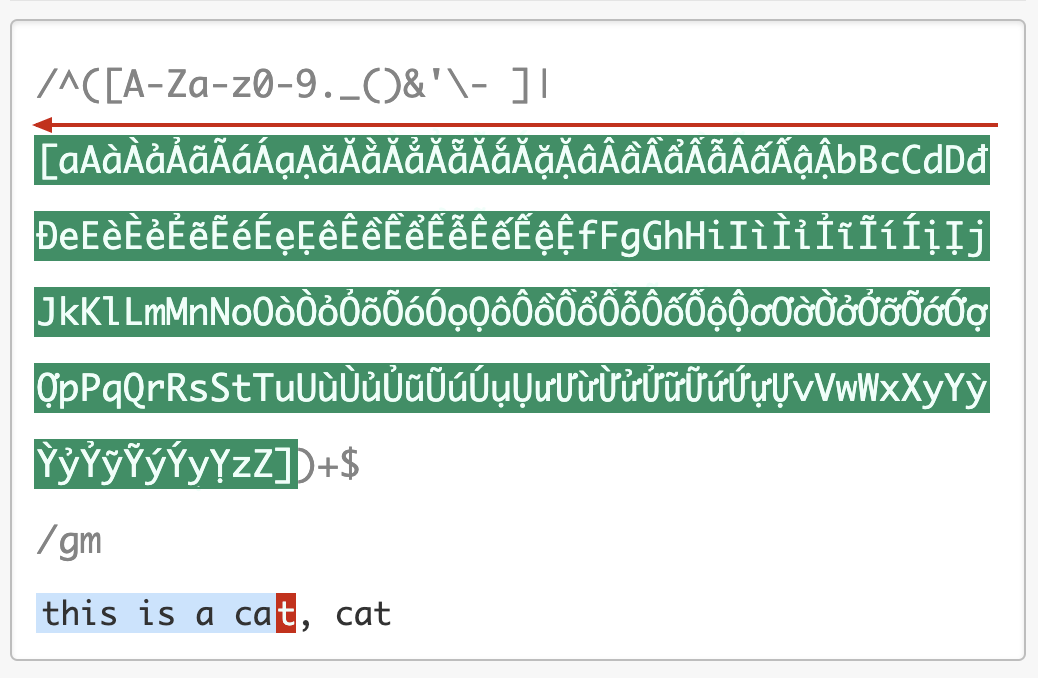
我们继续回溯,第二个分支匹配上的 t 吐出,第一个分支匹配上的 a 也吐出,再用第二个分支匹配 a 再试,如此发生了大量的回溯。你可以使用 regex101.com 中的 Regex Debugger 来调试一下这个过程,加深你的理解。
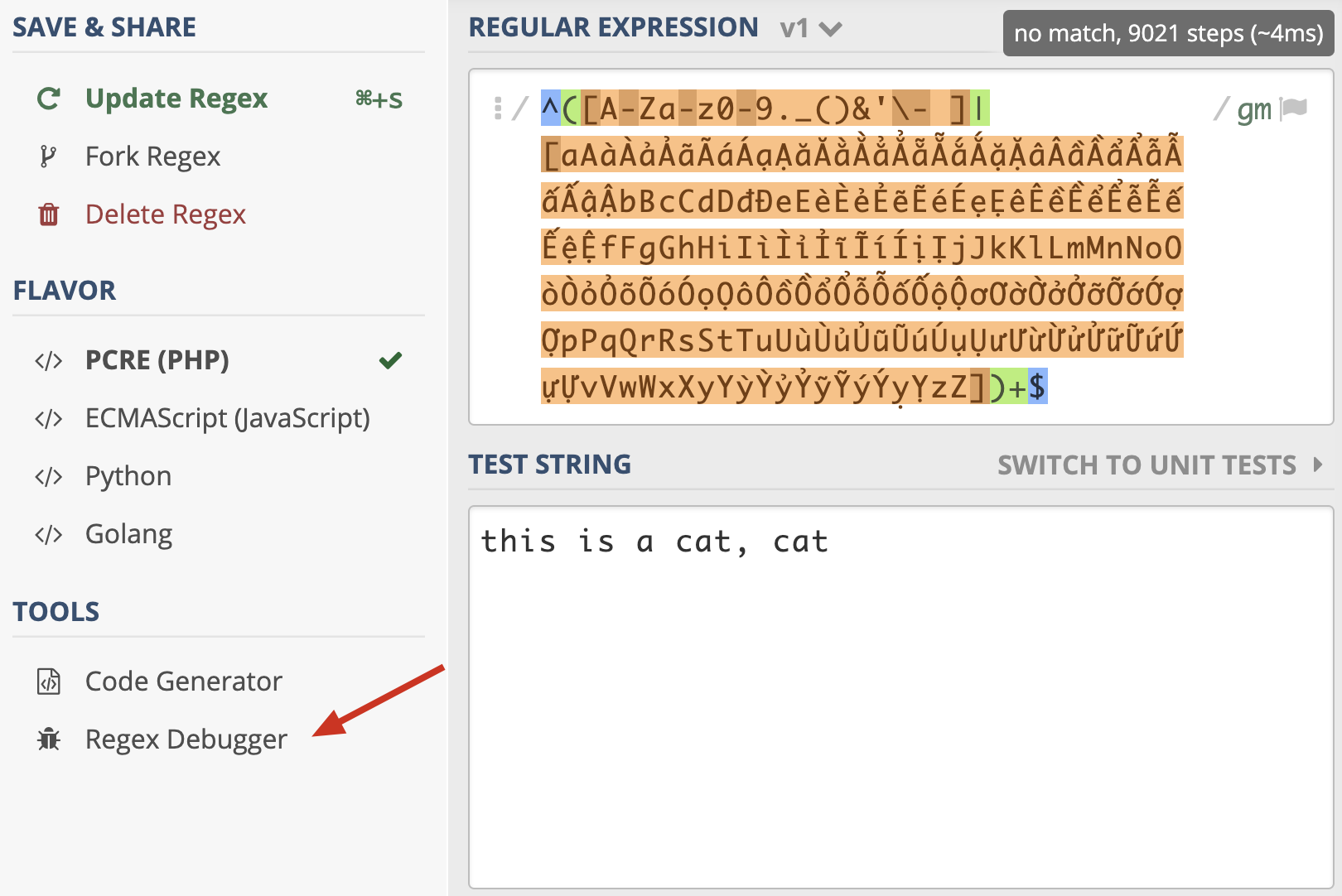

我们来尝试优化一下,把第一个分支中的 A-Za-z 去掉,因为后面多选分支结构中重复了,我们再看一下正则尝试匹配的次数( 示例),可以看到只尝试匹配了 57 次就结束了。
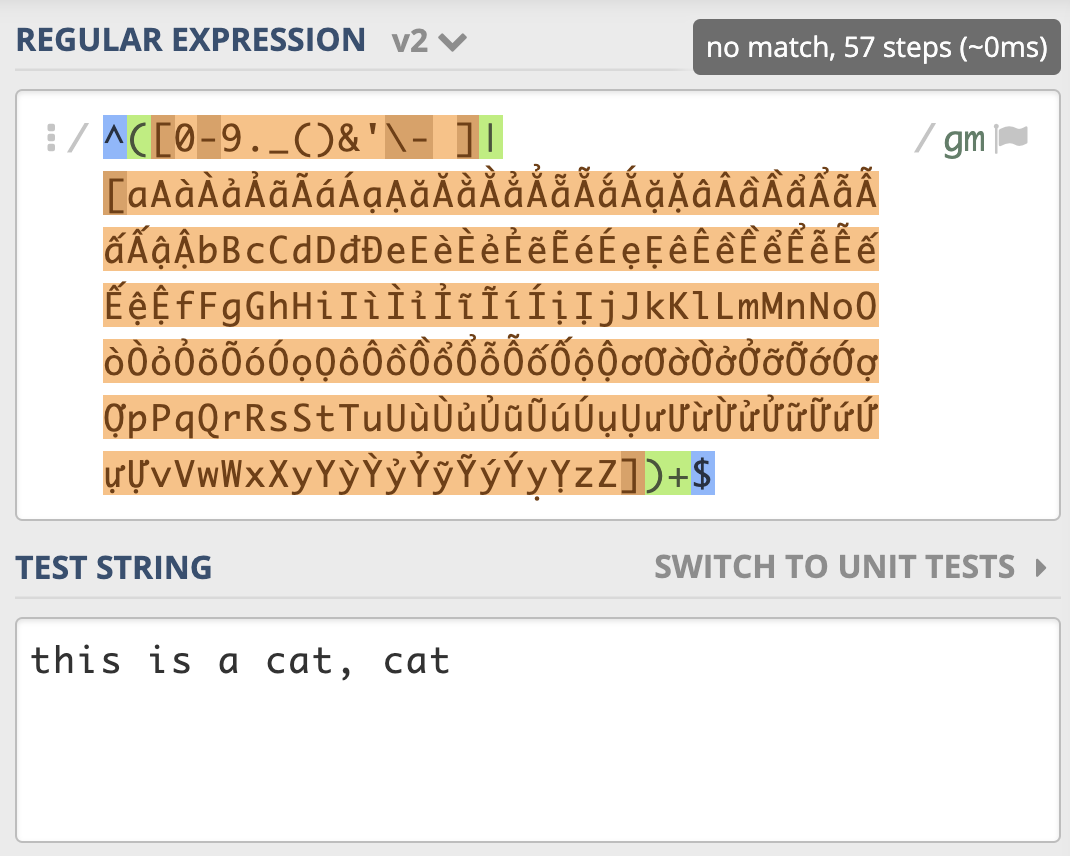
所以一定要记住,不要在多选择分支中,出现重复的元素。到这里,你对之前文章提到的“回溯不可怕,我们要尽量减少回溯后的判断” 是不是有了进一步的理解呢?
另外,之前我们说的独占模式,你可以把它可以理解为贪婪模式的一种优化,它也会发生广义的回溯,但它不会吐出已经匹配上的字符。独占模式匹配到英文逗号那儿,不会吐出已经匹配上的字符,匹配就失败了,所以采用独占模式也能解决性能问题( 示例)。
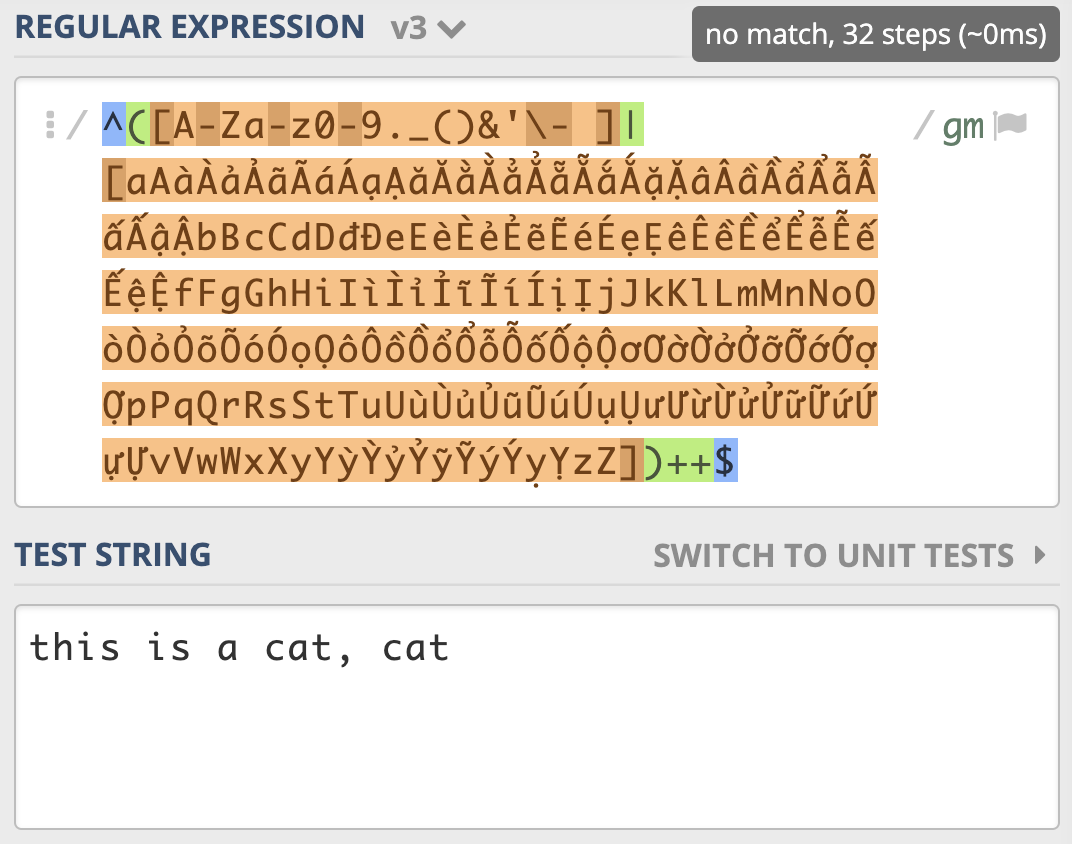
但要提醒你的是,独占模式“不吐出已匹配字符”的特性,会使得一些场景不能使用它。另外,只有少数编程语言支持独占模式。
解决这个问题还有其它的方式,比如我们可以尝试移除多选分支选择结构,直接用中括号表示多选一( 示例)。
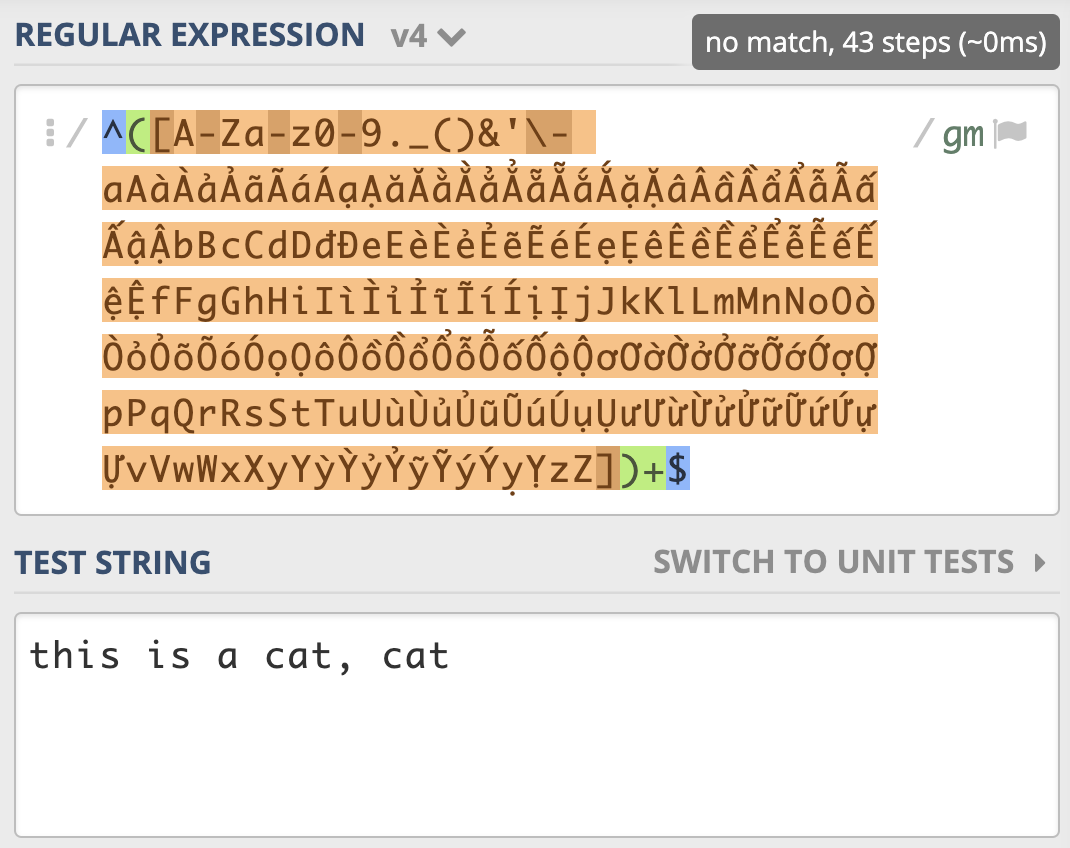
我们会发现性能也是有显著提升(这里只是测试,真正使用的时候,重复的元素都应该去掉,另外这里也不需要保存子组)。
优化建议
学习了原理之后,有助于我们写出更好的正则。我们必须先保证正则的功能是正确的,然后再进行优化性能,下面我给了你一些优化的方法供你参考。
1.测试性能的方法
我们可以使用 ipython 来测试正则的性能,ipython 是一个 Python shell 增强交互工具,在 macOS/Windows/Linux 上都可以安装使用。在测试正则表达式时,它非常有用,比如下面通过一个示例,来测试在字符串中查找 abc 时的时间消耗。
In [1]: import re
In [2]: x = '-' * 1000000 + 'abc'
In [3]: timeit re.search('abc', x)
480 µs ± 8.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
另外,你也可以通过前面 regex101.com 查看正则和文本匹配的次数,来得知正则的性能信息。
2.提前编译好正则
编程语言中一般都有“编译”方法,我们可以使用这个方法提前将正则处理好,这样不用在每次使用的时候去反复构造自动机,从而可以提高正则匹配的性能。
>>> import re
>>> reg = re.compile(r'ab?c') # 先编译好,再使用
>>> reg.findall('abc')
['abc']
>>> re.findall(r'ab?c', 'abc') # 正式使用不建议,但测试功能时较方便
['abc']
3.尽量准确表示匹配范围
比如我们要匹配引号里面的内容,除了写成 “.+?” 之外,我们可以写成 “ [^"]+”。使用 [^"] 要比使用点号好很多,虽然使用的是贪婪模式,但它不会出现点号将引号匹配上,再吐出的问题。
4.提取出公共部分
通过上面对 NFA引擎的学习,相信你应该明白 (abcd|abxy) 这样的表达式,可以优化成 ab(cd|xy),因为 NFA 以正则为主导,会导致字符串中的某些部分重复匹配多次,影响效率。
因此我们会知道 th(?:is|at) 要比 this|that 要快一些,但从可读性上看,后者要好一些,这个就需要用的时候去权衡,也可以添加代码注释让代码更容易理解。
类似地,如果是锚点,比如 (^this|^that) is 这样的,锚点部分也应该独立出来,可以写成比如 ^th(is|at) is 的形式,因为锚点部分也是需要尝试去匹配的,匹配次数要尽可能少。
5.出现可能性大的放左边
由于正则是从左到右看的,把出现概率大的放左边,域名中 .com 的使用是比 .net 多的,所以我们可以写成 \.(?:com|net)\b,而不是 \.(?:net|com)\b。
6.只在必要时才使用子组
在正则中,括号可以用于归组,但如果某部分后续不会再用到,就不需要保存成子组。通常的做法是,在写好正则后,把不需要保存子组的括号中加上 ?: 来表示只用于归组。如果保存成子组,正则引擎必须做一些额外工作来保存匹配到的内容,因为后面可能会用到,这会降低正则的匹配性能。
7.警惕嵌套的子组重复
如果一个组里面包含重复,接着这个组整体也可以重复,比如 (.*)* 这个正则,匹配的次数会呈指数级增长,所以尽量不要写这样的正则。
8.避免不同分支重复匹配
在多选分支选择中,要避免不同分支出现相同范围的情况,上面回溯的例子中,我们已经进行了比较详细的讲解。
总结
好了,今天的内容讲完了,我来带你总结回顾一下。
今天带你简单学习了有穷自动机的概念,自动机的具体实现称之为正则引擎。
我们学习了正则引擎的匹配原理,NFA 和 DFA 两种引擎的工作方式完全不同,NFA 是以表达式为主导的,先看正则表达式,再看文本。而 DFA 则是以文本为主导的,先看文本,再看正则表达式。POSIX NFA是指符合POSIX标准的NFA引擎,它会不断回溯,以确保找到最左侧最长匹配。
接着我们学习了测试正则表达式性能的方法,以及优化的一些方法,比如提前编译好正则,提取出公共部分,尽量准确地表示范围,必要时才使用子组等。
今天所讲的内容总结脑图如下,你可以回顾一下:

课后思考
最后,我们来做一个小练习吧。通过今天学习的内容,这里有一个示例,要求匹配“由字母或数字组成的字符串,但第一个字符要是小写英文字母”,你能说一下针对这个示例,NFA引擎的匹配过程么?
文本:a12
正则:^(?=[a-z])[a-z0-9]+$
好,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,并把文章分享给你的朋友或者同事,一起交流一下。
问题集锦:详解正则常见问题及解决方案
你好,我是伟忠。今天我来给你讲一讲,使用正则处理一些常见问题的方法。
问题处理思路
在讲解具体的问题前,我先来说一下使用正则处理问题的基本思路。有一些方法比较固定,比如将问题分解成多个小问题,每个小问题见招拆招:某个位置上可能有多个字符的话,就⽤字符组。某个位置上有多个字符串的话,就⽤多选结构。出现的次数不确定的话,就⽤量词。对出现的位置有要求的话,就⽤锚点锁定位置。
在正则中比较难的是某些字符不能出现,这个情况又可以进一步分为组成中不能出现,和要查找的内容前后不能出现。后一种用环视来解决就可以了。我们主要说一下第一种。
如果是要查找的内容中不能出现某些字符,这种情况比较简单,可以通过使用中括号来排除字符组,比如非元音字母可以使用 [^aeiou] 来表示。
如果是内容中不能出现某个子串,比如要求密码是6位,且不能有连续两个数字出现。假设密码允许的范围是 \w,你应该可以想到使用 \w{6} 来表示 6 位密码,但如果里面不能有连续两个数字的话,该如何限制呢?这个可以环视来解决,就是每个字符的后面都不能是两个数字(要注意开头也不能是 \d\d),下面是使用 Python3语言测试的示例。
>>> import re
>>> re.match(r'^((?!\d\d)\w){6}$', '11abcd') # 不能匹配上
# 提示 (?!\d\d) 代表右边不能是两个数字,但它左边没有正则,即为空字符串
>>> re.match(r'^((?!\d\d)\w){6}$', '1a2b3c') # 能匹配上
<re.Match object; span=(0, 6), match='1a2b3c'>
>>> re.match(r'^(\w(?!\d\d)){6}$', '11abcd') # 错误正则示范
<re.Match object; span=(0, 6), match='11abcd'>
在写完正则后,我们可以通过一些工具去调试,先要确保正则满足功能需求,再看一下有没有性能问题, 如果功能不正确,性能考虑再多其实也没用。
常见问题及解决方案
数字的匹配比较简单,通过我们学习的字符组,量词等就可以轻松解决。
- 数字在正则中可以使用 \d 或 [0-9] 来表示。
- 如果是连续的多个数字,可以使用 \d+ 或 [0-9]+。
- 如果 n 位数据,可以使用 \d{n}。
- 如果是至少 n 位数据,可以使用 \d{n,}。
- 如果是 m-n 位数字,可以使用 \d{m,n}。
如果希望正则能匹配到比如 3,3.14,-3.3,+2.7 等数字,需要注意的是,开头的正负符号可能有,也可能没有,所以可以使用 [-+]? 来表示,小数点和后面的内容也不一定会有,所以可以使用 (?:\.\d+)? 来表示,因此匹配正数、负数和小数的正则可以写成 [-+]?\d+(?:\.\d+)?。
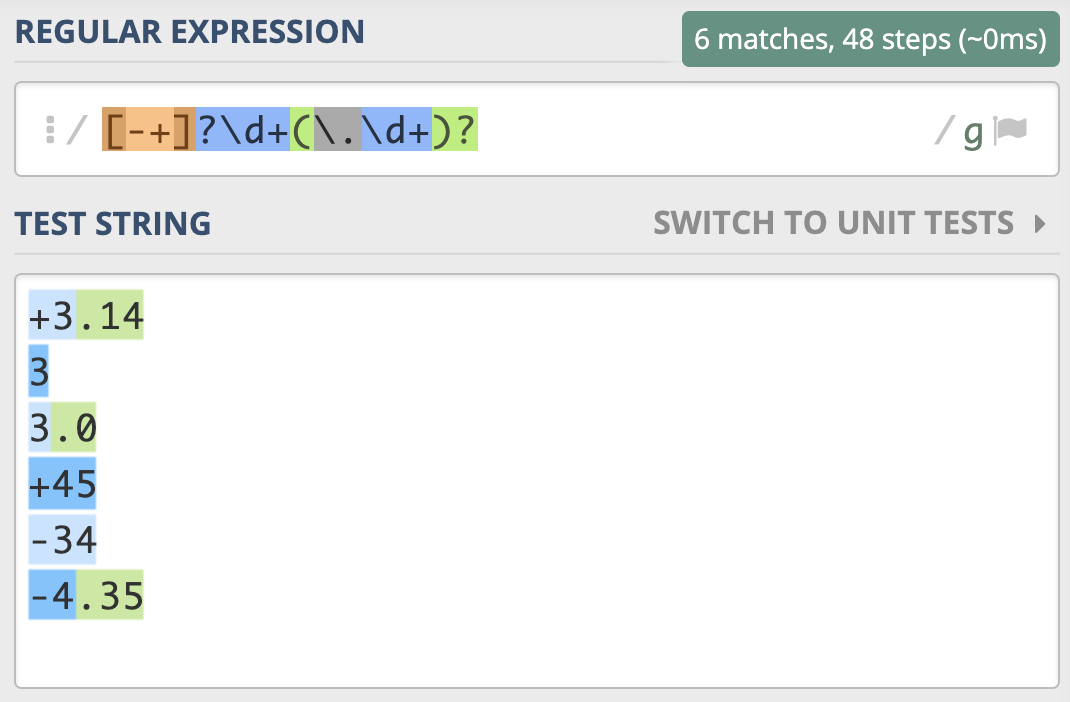
非负整数,包含 0 和 正整数,可以表示成 [1-9]\d*|0。
非正整数,包含 0 和 负整数,可以表示成 -[1-9]\d*|0。
这个问题你可能觉得比较简单,其中表示正负的符号和小数点可能有,也可能没有,直接用 [-+]?\d+(?:\.\d+)? 来表示。
如果我们考虑 .5 和 +.5 这样的写法,但一般不会有 -.5 这样的写法。正则又如何写呢?
我们可以把问题拆解,浮点数分为符号位、整数部分、小数点和小数部分,这些部分都有可能不存在,如果我们每个部分都加个问号,这样整个表达式可以匹配上空。
根据上面的提示,负号的时候整数部分不能没有,而正数的时候,整数部分可以没有,所以正则你可以将正负两种情况拆开,使用多选结构写成 -?\d+(?:\.\d+)?|\+?(?:\d+(?:\.\d+)?|\.\d+)( 示例)。
这个可以拆分成两个问题:
负数浮点数表示: -\d+(?:\.\d+)?。
正数浮点数表示: \+?(?:\d+(?:\.\d+)?|\.\d+)。
十六进制的数字除了有0-9之外,还会有 a-f(或A-F) 代表 10 到 15 这6个数字,所以正则可以写成 [0-9A-Fa-f]+。
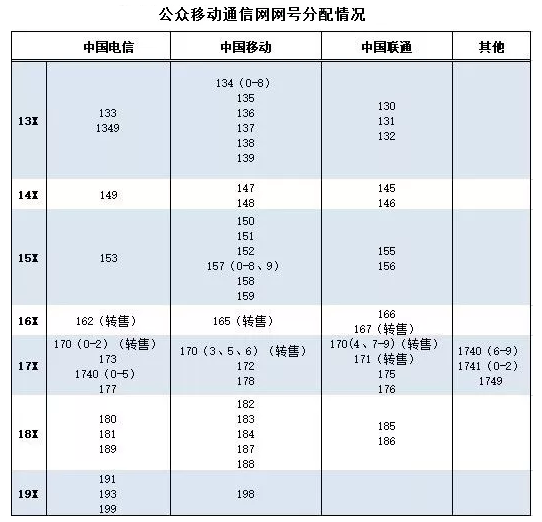
手机号应该是比较常见的,手机号段比较复杂,如果要兼容所有的号段并不容易。目前来看,前四位是有一些限制,甚至1740 和 1741 限制了前5位号段。
我们可以简单地使用字符组和多选分支,来准确地匹配手机号段。如果只限制前2位,可以表示成 1[3-9]\d{9},如果想再精确些,限制到前三位,比如使用 1(?:3\d|4[5-9]|5[0-35-9]|6[2567]|7[0-8]|8\d|9[1389])\d{8} 来表示。如果想精确到4位,甚至5位,可以根据公开的号段信息自己来写一下,但要注意的是,越是精确,只要有新的号段,你就得改这个正则,维护起来会比较麻烦。另外,在实际运用的时候,你可能还要考虑一下有一些号码了+86或0086之类的前缀的情况。
手机号段的正则写起来其实写起来并不难,但麻烦的是后期的维护成本比较高,我之前就遇到过这种情况,买了一个188的移动号码,有不少系统在这个号段开放了挺长时间之后,还认为这个号段不合法。
目前公开的手机号段( 图片来源)。
我国的身份证号码是分两代的,第一代是15位,第二代是18位。如果是18位,最后一位可以是X(或x),两代开头都不能是 0,根据规则,你应该能很容易写出相应的正则,第一代可以用 [1-9]\d{14} 来表示,第二代比第一代多3位数据,可以使用量词0到1次,即写成
[1-9]\d{14}(\d\d[0-9Xx])?。
邮编一般为6位数字,比较简单,可以写成 \d{6},之前我们也提到过,6位数字在其它情况下出现可能性也非常大,比如手机号的一部分,身份证号的一部分,所以如果是数据提取,一般需要添加断言,即写成 (?<!\d)\d{6}(?!\d)。
目前QQ号不能以0开头,最长的有10位,最短的从 10000(5位)开始。从规则上我们可以得知,首位是1-9,后面跟着是4到9位的数字,即可以使用 [1-9][0-9]{4,9} 来表示。
中文属于多字节Unicode字符,之前我们讲过比如通过 Unicode 属性,但有一些语言是不支持这种属性的,可以通过另外一个办法,就是码值的范围,中文的范围是 4E00 - 9FFF 之间,这样可以覆盖日常使用大多数情况。
不同的语言是表示方式有一些差异,比如在 Python,Java,JavaScript 中,Unicode 可以写成 \u码值 来表示,即匹配中文的正则可以写成 [\u4E00-\u9FFF],如果在 PHP 中使用,Unicode 就需要写成 \u{码值} 的样式。下面是在 Python3 语言中测试的示例,你可以参考一下。
# 测试环境,Python3
>>> import re
>>> reg = re.compile(r'[\u4E00-\u9FFF]')
>>> reg.findall("和伟忠一起学正则regex")
['和', '伟', '忠', '一', '起', '学', '正', '则']
IPv4 地址通常表示成 27.86.1.226 的样式,4个数字用点隔开,每一位范围是 0-255,比如从日志中提取出IP,如果不要求那么精确,一般使用 \d{1,3}(\.\d{1,3}){3} 就够了,需要注意点号需要转义。
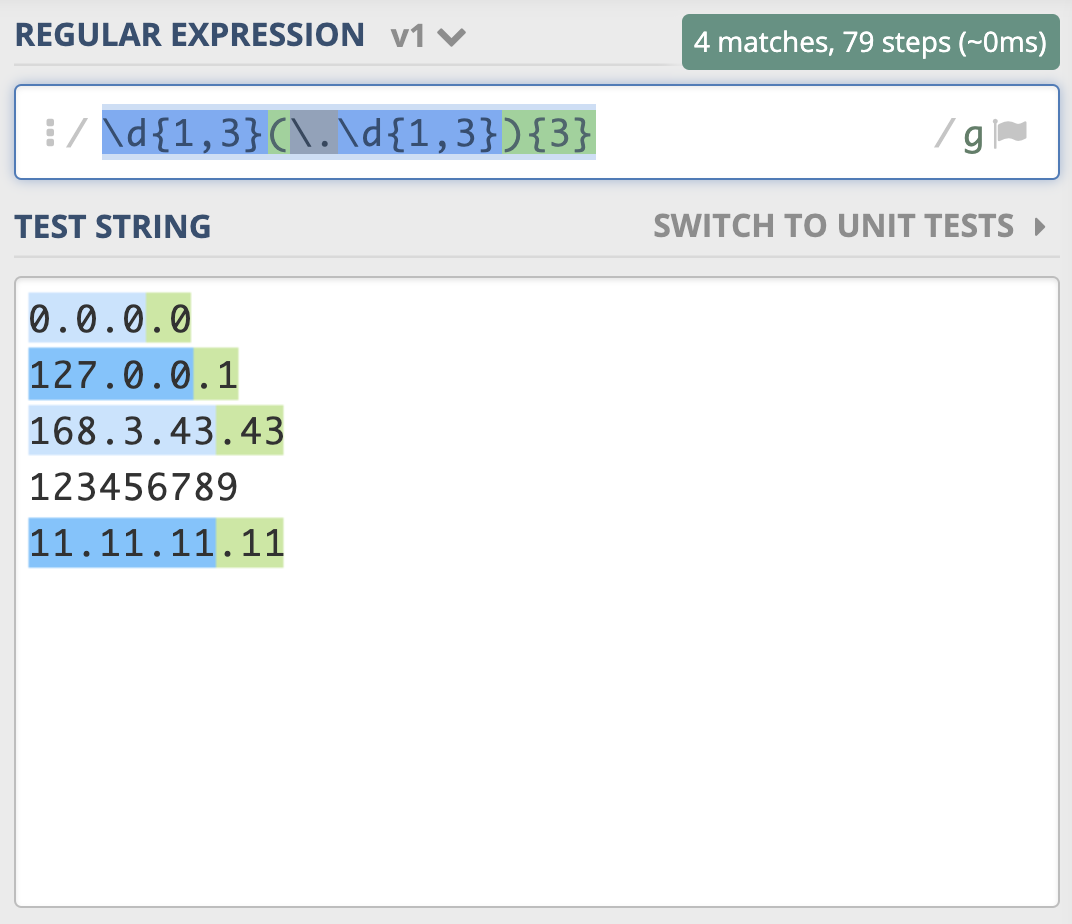
如果我们想更精确地匹配,可以针对一到三位数分别考虑,一位数时可以表示成 0{0,2}\d,两位数时可以表示成 0?[1-9]\d,三位数时可以表示成 1\d\d|2[0-4]\d|25[0-5],使用多选分支结构把他们写到一起,就是 0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5] 这样。
这是表示出了 IPv4 地址中的一位(正则假设是 X),我们可以把 IPv4 表示成X.X.X.X,可以使用量词,写成 (?:X.){3}X 或 X(?:.X){3},由于 X 本身比较复杂,里面有多选分支结构,所以需要把它加上括号,所以 IPv4 的正则应该可以写成
(?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(?:\.0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5]){3}。
你以为这么写就对了么,如果你测试一下就发现,匹配行为很奇怪。( 示例)
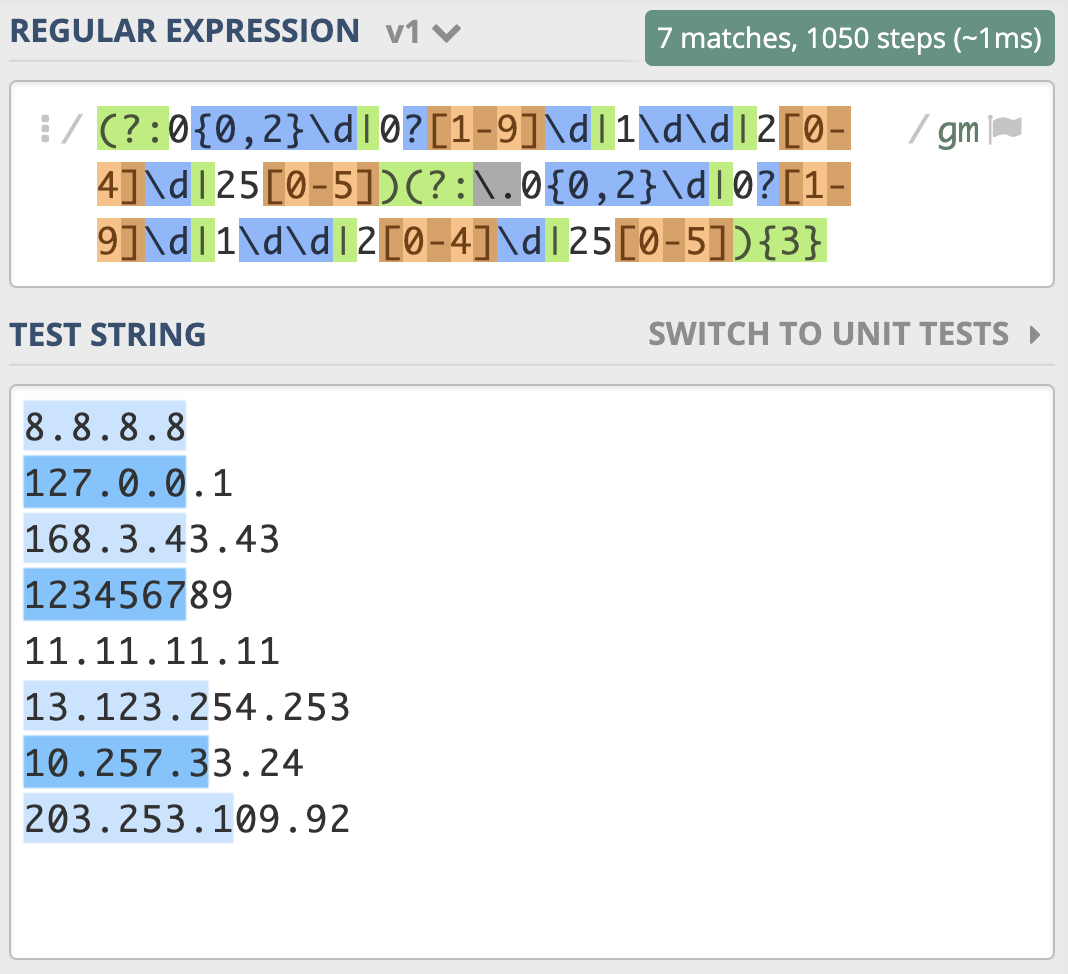
看到这个结果,你可能觉得太难了,不要担心,更不要放弃。其实我一开始也觉得这么写就可以了,我也需要测试,如果不符合预期,那就找到原因不断完善。
我们根据输出结果的表现,分析一下原因。原因主要有两点,都和多选分支结构有关系。我们想的是所有的一到三位数字前面都有一个点,重复三次,但点号和 0{0,2}\d 写到一起,意思是一位数字前面有点,两位和三位数前面没有点,所以需要使用括号把点挪出去,最终写成 (?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(?:\.(?:0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5])){3}。
但经过测试,你会发现还是有问题,最后一个数字只匹配上了一位。( 示例)
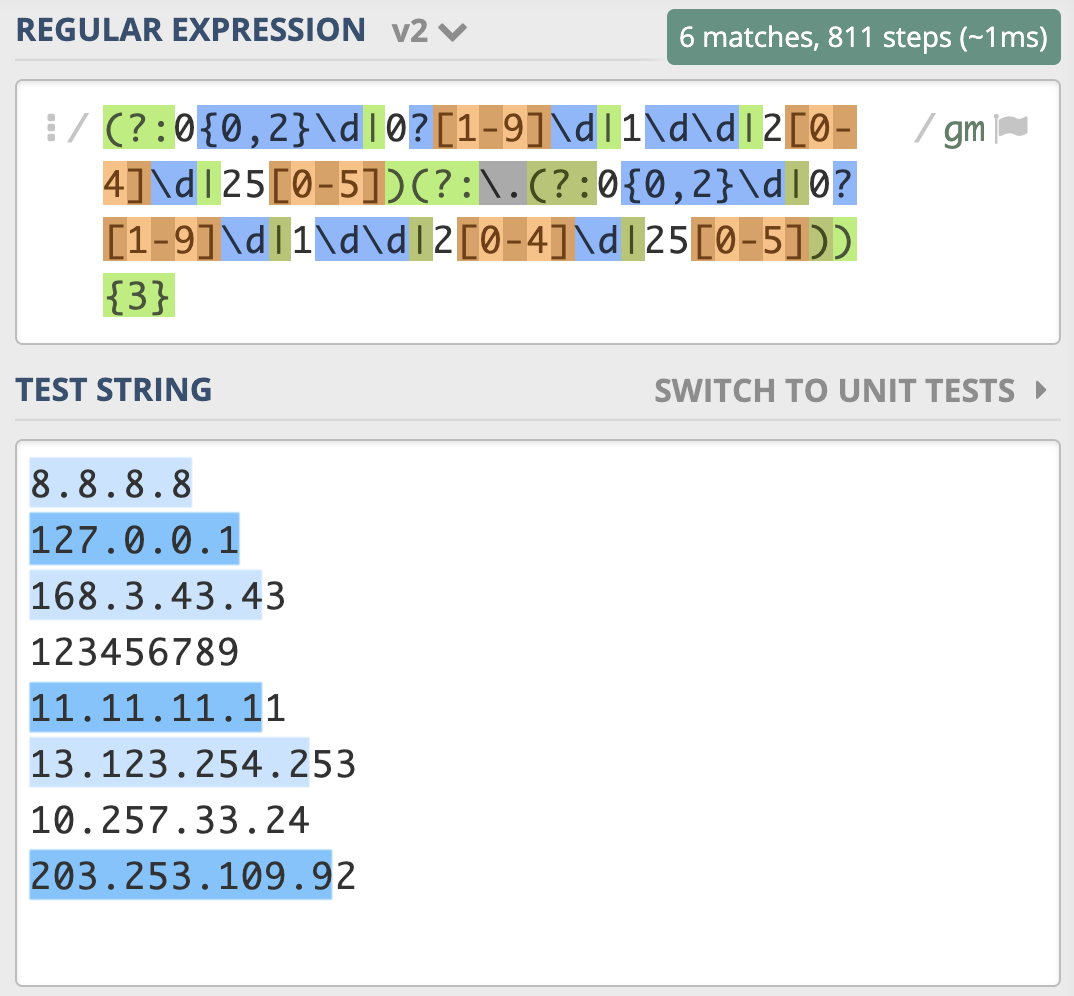
上一讲正则匹配原理中,我们讲解了NFA引擎在匹配多分支选择结构的时候,优先匹配最左边的,所以找到了一位数符合要求时,它就”急于“报告,并没有找出最长且符合要求的结果,这就要求我们在写多分支选择结构的时候,要把长的分支放左边,这样就可以解决问题了,即正则写成 (?:1\d\d|2[0-4]\d|25[0-5]|0?[1-9]\d|0{0,2}\d)(?:\.(?:1\d\d|2[0-4]\d|25[0-5]|0?[1-9]\d|0{0,2}\d)){3}。
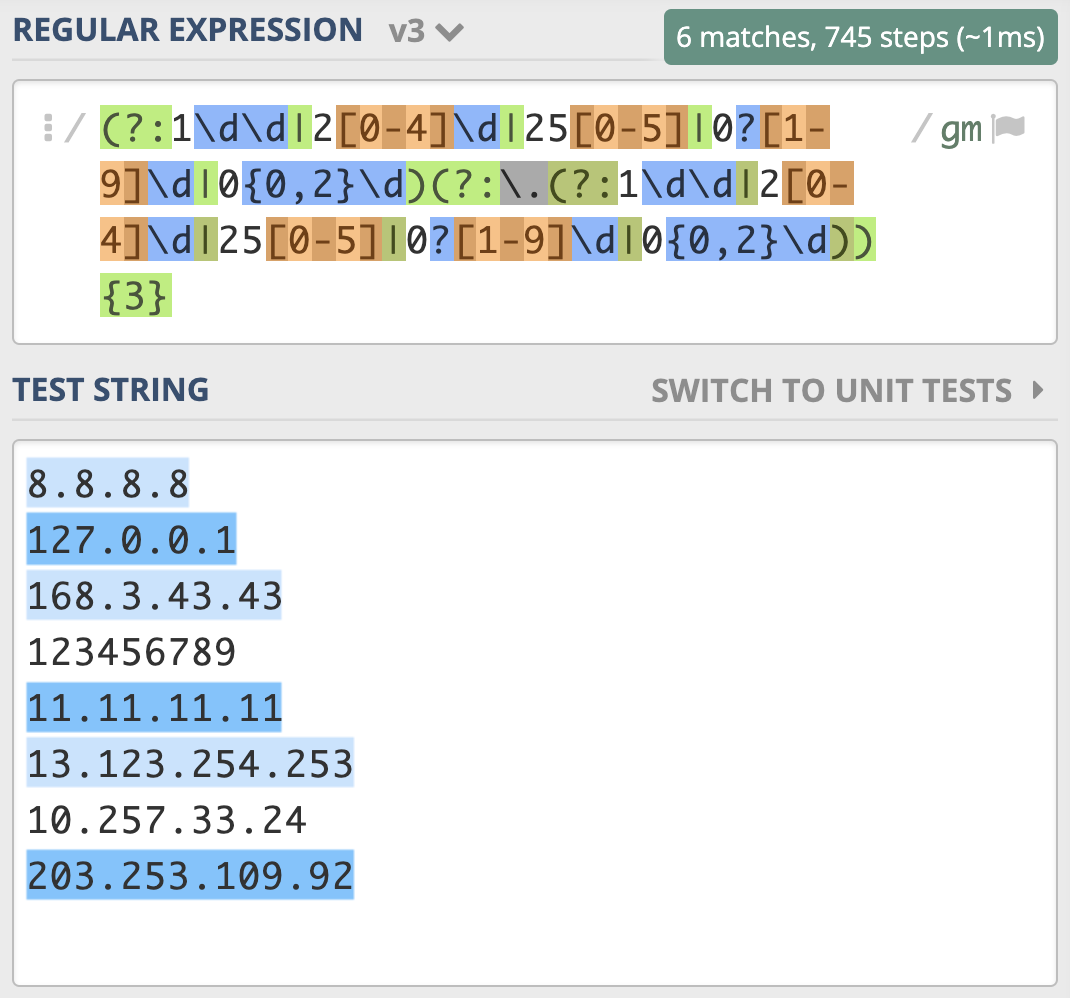
在这个案例里,我们通过一步步推导,得到最终的答案。其实是想让你明白,你在写正则的时候,需要以什么样的分析思路来思考,最终如何解决问题,复杂的正则也很难一下子写出来,需要写完之后进行测试,在发现不符合预期后,不断进行完善。
在这里我还是想说一下,如果只是验证是不是合法的 IPv4 地址,可以直接使用点号切割,验证一下是不是四个部分,每个部分是不是在 0-255 之间就可以了,比使用正则来校验要简单很多,而且不容易出错。总之正则不是解决问题的唯一方法,我们要在合适的时候使用它,而不是说能用正则的都要用正则来解决。
假设日期格式是 yyyy-mm-dd,如果不那么严格,我们可以直接使用 \d{4}-\d{2}-\d{2}。如果再精确一些,比如月份是 1-12,当为一位的时候,前面可能不带 0,可以写成 01 或 1,月份使用正则,可以表示成 1[0-2]|0?[1-9],日可能是 1-31,可以表示成 [12]\d|3[01]|0?[1-9],这里需要注意的是 0?[1-9] 应该放在多选分支的最后面,因为放最前面,匹配上一位数字的时候就停止了( 示例),正确的正则( 示例)应该是 \d{4}-(?:1[0-2]|0?[1-9])-(?:[12]\d|3[01]|0?[1-9])。
时间格式比如是 23:34,如果是24小时制,小时是 0-23,分钟是 0-59,所以可以写成 (?:2[0-3]|1\d|0?\d):(?:[1-5]\d|0?\d)。12小时制的也是类似的,你可以自己想一想怎么写。
另外,日期中月份还有大小月的问题,比如2月闰年可以是29日,使用正则没法验证日期是不是正确的。我们也不应该使用正则来完成所有事情,而是只使用正则来限制具体的格式,比如四位数字,两位数字之类的,提取到之后,使用日期时间相关的函数进行转换,如果失败就证明不是合法的日期时间。
> 邮箱示例:
> weizhong.tu2020@abc.com
> 12345@qq.com
邮箱的组成是比较复杂的,格式是 用户名@主机名,用户名部分通常可以有英文字母,数字,下划线,点等组成,但其中点不能在开头,也不能重复出现。根据 RFC5322 没有办法写出一个完美的正则,你可以参考一下 这个网站。不过我们可以实现一些简体的版本,比如: [a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+。
日常使用应该也够了。
配对出现的标签,比如 title,一般网页标签不区分大小写,我们可以使用 (?i)<title>.*?</title> 来进行匹配。在提取引号里面的内容时,可以使用 [^"]+,方括号里面的内容时,可以使用 [^>]+ 等方式。
我们通过一些常见的问题,逐步进行分析,讲解了正则表达式书写时的思路,和一些常见的错误。这些正则如果用于校验,还需要添加断言,比如 \A 和 \z(或\Z),或 ^ 和 $。如果用于数据提取,还应当在首尾添加相应的断言。
总结
好了,今天的内容讲完了,我来带你总结回顾一下。
今天我们了解了下正则处理问题的基本思路,通常是将问题拆解成多个小问题,每个小问题见招拆招:某个位置上可能是多个单字符就⽤字符组,某个位置上可能是多个字符串就⽤多选结构,出现次数不确定就⽤量词,对出现的位置有要求就用断言。遇到问题,你遵循这些套路,写出正则其实并不难。
我们从一些日常的问题入手,详细地讲解了一些常见的案例,也讲解了可能会遇到的一些坑,比如在使用多选结构时要注意的问题,你在后续工作中要注意避开这些问题。
我在这里给你放了一张今天所讲内容的总结脑图。
课后思考
最后,我们来做一个小练习吧。你可以根据今天我们学习 IPv4 的方法,来写一下 IPv6 的正则表达式么?说一下你的分析思路和最终的答案,建议自己动手测试一下写出的正则。
IPv6示例
ABCD:EF01:2345:6789:ABCD:EF01:2345:6789
这种表示法中,每个X的前导0是可以省略的,例如:
2001:0DB8:0000:0023:0008:0800:200C:417A
上面的IPv6地址,可以表示成下面这样
2001:DB8:0:23:8:800:200C:417A
备注:这里不考虑0位压缩表示
好,今天的课程就结束了,希望可以帮助到你,也希望你在下方的留言区和我参与讨论,并把文章分享给你的朋友或者同事,一起交流一下。
加餐 | 从编程语言的角度来理解正则表达式
你好,我是林耀平,你也可以直接叫我的网名笨笨阿林。很高兴能在极客时间和你聊聊我理解的正则表达式。
在我看来,正则表达式是那种典型的,对没用过的人来说,不觉得对自己有什么影响,可是一旦用过了,就再也回不去的神器。当然,我这里所说的“用过”,不是指简单使用一些正则的基本功能,而是指能够熟练运用基本功能和高级功能。所以说,对于正则表达式,你用得越熟练,就会越会惊叹于它的强大与神奇。
对于正则表达式的分析和解读,目前大多数文章和书籍多集中在正则表达式自身,比如对正则表达式的各个元字符、元转义序列以及匹配原理的分析和解读上。这些当然十分重要,是我们学习正则的基础。但这一节作为加餐,我将尝试给你提供一个新的理解角度:在我看来,正则表达式也是一门编程语言。为啥这么说呢?下面我将带你从编程语言发展史的角度,以及编程范式的角度来具体看看。
为啥说正则表达式也是一门编程语言?
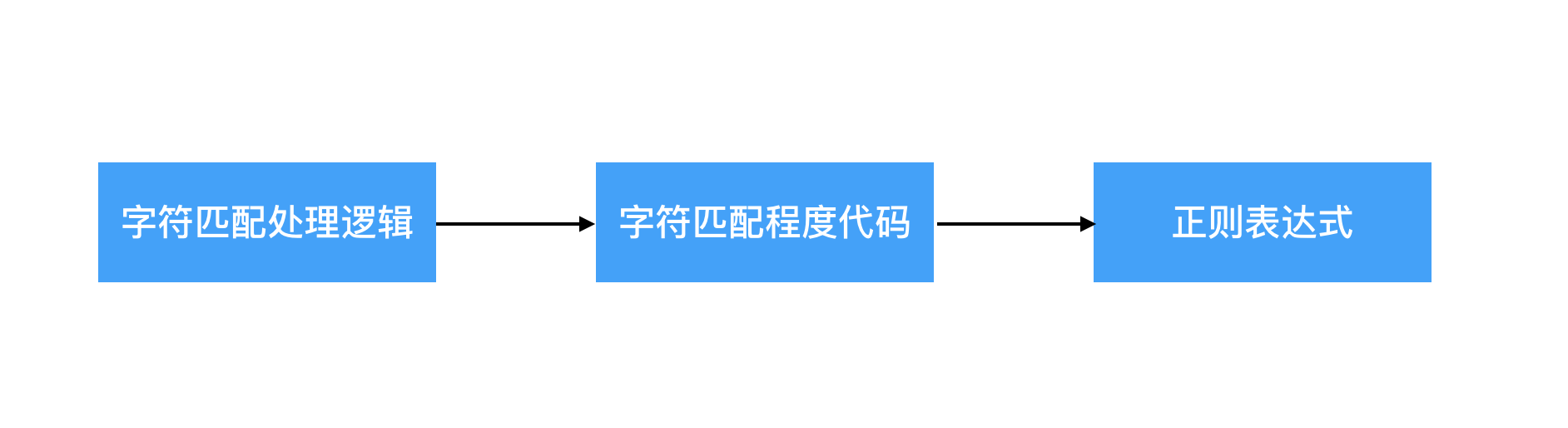
我们知道,程序代码是对现实事物处理逻辑的抽象,而正则表达式,则是对复杂的字符匹配程序代码的进一步抽象;也就是说,高度简洁的正则表达式,可以认为其背后所对应的,是字符匹配程序代码,而字符匹配程序代码,背后对应的是字符匹配处理逻辑。
因此,我们可以这么认为,字符匹配处理逻辑,可以抽象为字符匹配程序代码;字符匹配程序代码,可以再进一步,抽象为高度简洁的正则表达式。怎么理解呢?我们举个例子来说。
如果我们要在一段文本中同时查找“张三”和“李四”这两个名字,字符匹配处理逻辑就是:当查找到了“张三”,则提示“找到了‘张三’”,当查找到了“李四”,则提示“找到了‘李四’”;如果将这段字符匹配处理,逻辑抽象为字符匹配程序伪代码,就是下面这样:
var str = "张三正在学习正则表达式......"
if (find("张三", str) == true) then showMessage("找到了'张三'")
else if (find("李四", str) == true) then showMessage("找到了'李四'")
else showMessage("没有找到")
上面的这两行字符匹配程序伪代码,如果进一步抽象为正则表达式,就是:张三|李四。
你看,相对于字符匹配程序代码,正则表达式不需要使用if、then、else等关键字,也不需要调用find、showMessage等函数,这些在正则表达式中都已经隐含了。也就是说,正则表达式解析引擎,会自动按类似逻辑进行解析,这也就是正则表达式“高度简洁”的体现。
从编程语言发展史角度来理解
那说了这么多,我们下面来看看编程语言的发展历程。我把它们大致上分为了5代。你可以看一下下面这个表。
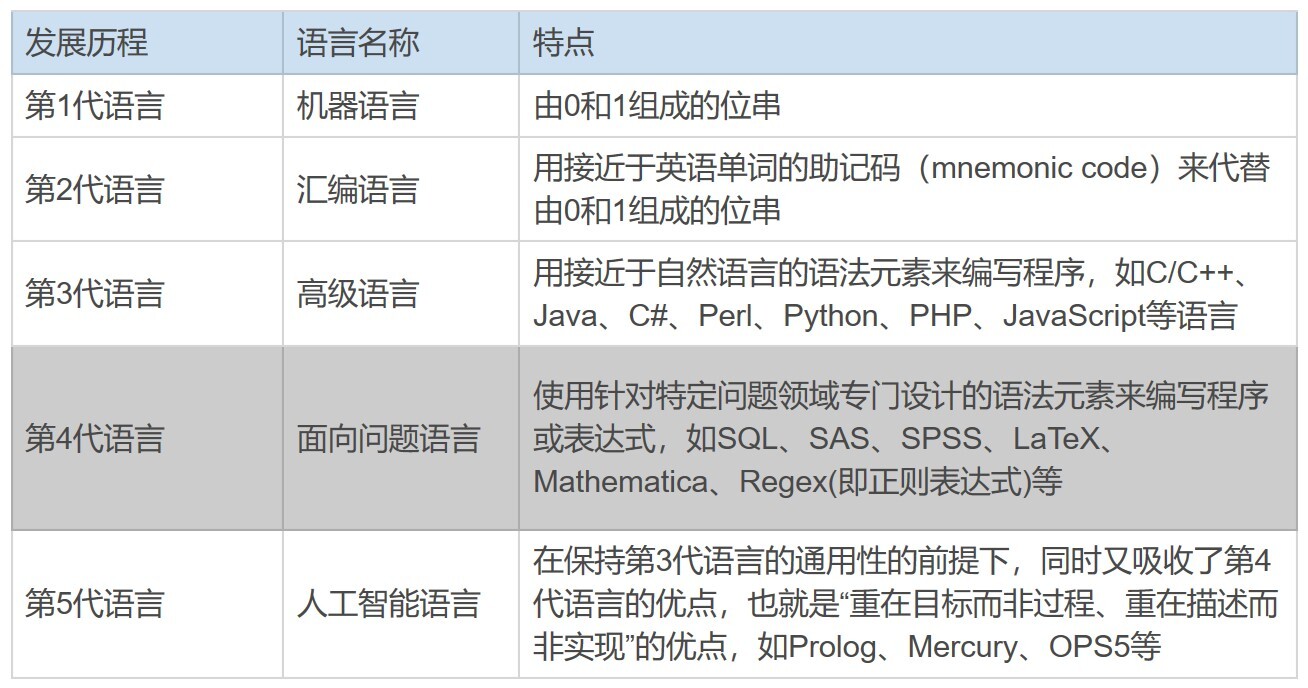
显然,正则表达式也是一种编程语言,而且是属于第4代语言——面向问题语言中的一种。
可以看到,第4代语言相对于第3代语言,更专注于某个特定、专门的业务逻辑和问题领域。程序员主要负责分析问题,以及使用第4代语言来描述问题,而无需花费大量时间,去考虑具体的处理逻辑和算法实现,处理逻辑和算法实现是由编译器(Compiler)或解释器(Interpreter)这样的语言解析引擎来负责的。
事实上,最初之所以提出第4代语言的概念,其目的就是希望非专业程序员也能做应用开发,不过就目前情况来看,这个目的并没有得到很好的实现。
从编程范式角度来理解
编程范式(Programming Paradigm),指的是计算机编程中的基本风格和典范模式,是程序员在其所创造的程序虚拟世界中自觉不自觉地所采用的世界观和方法论。
常见的编程范式大致上有:命令式、声明式(包括了函数式、逻辑式等)、面向对象式、泛型式、并发式、切面式等。每种编程范式都引导着程序员,根据其特有的倾向(即世界观)和思路(即方法论)去分析和解决编程问题。
下面我们来重点讲一下命令式和声明式这两种编程范式。
我们先来看第一种, 命令式编程范式。
命令式编程范式,主要就是模拟电脑运算的过程。更进一步地来说,是直接模拟目前主流的冯·诺依曼机(Von Neumann Machine)的运算过程,是对冯·诺伊曼机运行机制的抽象。
冯·诺伊曼机的基本特点是,在程序计数器的集中控制下,按顺序依次从内存中获取指令和数据,然后进行执行,因此它是以控制驱动的控制流方式工作的。与冯·诺依曼机相对应的还有以数据驱动的数据流方式工作的数据流机,以及以需求驱动的数据流方式工作的归约机等。
采用命令式编程范式的程序,是由若干行动指令所组成的有序指令列表,也就是由一系列指明执行顺序的祈使句——“先做这,再做那”所组成,属于行动导向,强调的是定义问题的解法——即“怎么做”,因而算法是显性的而目标是隐性的。
因此,从编程范式的角度来看:
- 命令式编程的世界观是:程序是由若干行动指令组成的有序列表;
- 命令式编程的方法论是:用变量来存储数据,用语句来执行指令。
如果追根溯源的话,几乎所有基于冯·诺伊曼机的编程语言,其实都可看作汇编语言的升级,而作为与机器语言一一对应的汇编语言来说,它自然是命令式的,因而命令式编程范式最为基础和普及。不过,从纯粹性的角度来说,命令式编程范式的代表语言为Fortran、Pascal、C等。
第二种是声明式编程范式。
声明式编程范式,主要是模拟人脑思维的过程。声明式重目标、轻过程,专注问题的分析和表达,而不是算法实现。它不用指明执行顺序,属于目标导向,强调的是定义问题的描述——即“做什么”,因而目标是显性而算法是隐性的。
因此,从编程范式的角度来看:
- 声明式编程的世界观是:程序是由若干目标任务组成的有序列表;
- 声明式编程的方法论是:用语法元素来描述任务,由解析引擎转化为指令并执行。
事实上,前面所说的第4代,面向问题的语言,基本上都属于声明式编程范式,而且往往也只支持声明式编程范式。声明式编程范式的主要特点就是,重在目标而非过程、重在描述而非实现,以声明式语句直接描述要解决的目标任务,专注于任务的分析和表达。声明式没有专注于处理逻辑和算法实现的过程,它具体的处理逻辑和算法实现是由语言解析引擎来负责的。
声明式编程的代表语言为SQL、SAS、SPSS、LaTeX、Regex(即正则表达式)等。
讲到这里你可能会有疑问,既然是程序,那它总是要实现功能的,通过声明式编程语言所编写的程序,到底是如何实现功能的呢?事实上,这是由语言解析引擎,也就是编译器或解释器,最终通过命令式编程来实现功能的。不过,这仅限于冯·诺依曼机中的编程语言,非冯·诺依曼机中的编程语言就不一定是这样了。
换句话说,声明式编程是建立在命令式编程的基础之上的。这也是声明式编程比命令式编程更为高级、更加简单、更省人工的原因。事实上,正如前面所讲过的,目前基于冯·诺依曼机的几乎所有编程语言都是以命令式编程为基础。
相较于通用编程语言GPPL,正则表达式属于领域特定语言DSL。
当然,这样一来,这些由语言解析引擎所实现的处理逻辑和具体算法,它们的通用性就会比较差,只能适用于某些特定业务或特定领域。也正是因为这个原因,第4代语言基本都是局限于某些特定领域,大多被认为是领域特定语言DSL(Domain Specific Language),也称为领域专用语言。
与领域特定语言相对应的是通用编程语言GPPL(General-Purpose Programming Language),作为第3代语言的高级语言大都属于通用编程语言,基本上都支持命令式编程范式。
通用编程语言解决问题的处理逻辑和算法实现,可以由程序员灵活设计、自由发挥,然而,正像是前面所说的,由于领域特定语言大都只属于声明式编程范式,解决问题的处理逻辑和算法实现,是由语言解析引擎自动完成的,程序员一般只需要也只能够声明式地描述问题,而不需要也不能够命令式地自行自由设计解决问题的处理逻辑和算法实现,程序员灵活设计、自由发挥的空间很小。
因此,领域特定语言几乎没有通用性,而且也大都是非图灵完备的语言。这里的图灵完备是什么意思呢?一个能计算出每个图灵可计算函数(Turing-computable function)的计算系统,就被称为图灵完备的;一个语言是图灵完备的,就意味着该语言的计算能力与一个通用图灵机(Universal Turing Machine)相当。
这里又提到了两个新概念:图灵可计算函数和通用图灵机。我们只需要记住下面这么一个关键点:当我们说一门编程语言是图灵完备的语言时,说明这门语言所拥有的编程能力,是现代计算机语言所能拥有的最高能力。
而领域特定语言大都不是图灵完备的语言,因此在计算能力、表达能力和功能上,相对于通用编程语言这样的图灵完备的语言来说,要受到很大的限制,只能专用于解决特定业务方向和特定业务领域的专门问题。
比如,SQL是专用于解决数据库操作问题的语言、SAS和SPSS是专用于解决统计分析问题的语言、LaTeX是专用于解决排版问题的语言,Mathematica是专用于解决科学计算问题的语言;而我们这里所讨论的正则表达式(Regex,Regular expression),则是专用于解决文本查找匹配问题的专门语言。
正则表达式的语法元素本质上就是程序逻辑和算法
前面说了,正则表达式从编程语言发展史的角度上来看,其实是属于第4代的面向问题语言。正则从编程范式的角度上来看,其实是属于声明式编程范式,并且是专用于处理文本查找匹配这个特定领域的专门语言。理解了这些,我们就比较容易理解之前所提到的,正则表达式是文本查找匹配处理逻辑和文本查找匹配程序代码的抽象这一点了。
实际上,更进一步地来说,正则表达式中的语法元素——元字符、元转义序列与特殊结构,可理解为某种具体的程序逻辑和算法的体现。注意,这里提到的元转义序列,指的是相对于将元字符转义为字符本义的普通转义序列来说的。
比如,正则表达式中的星号量词“ *”这一元字符,就是高级语言的处理逻辑“循环结构”的体现。具体来说,星号量词“ *”代表的是不定次数循环结构,而前后多个星号量词的嵌套就是多层不定次数循环结构的嵌套;或运算符,也就是竖线“|”这个元字符,就是高级语言的处理逻辑“分支结构”的体现;而用于分组的圆括号“()”,就相当于高级语言的作用域。
而当或运算符“|”出现在由星号量词“ *”所限定的分组圆括号“()”中时,其实就是在“循环结构”中嵌套了“分支结构”;而如果进一步地,“循环结构”所嵌套的“分支结构”中的某个分支,又被某个星号量词“ *”所限定,那么则相当于“循环结构”所嵌套的“分支结构”又嵌套了“循环结构”。
比如下面这个正则表达式:(张三|李四*)*。这里我们就不写匹配程序伪代码了,我们以图示的形式来展示处理逻辑,这样更为直观和形象。
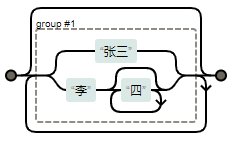
另外,从语法结构的角度来看,正则表达式的基本语法结构与一般高级编程语言差不多,主要就是顺序结构(也称为连接结构)、分支结构(也称为选择结构)、循环结构(也称为重复结构)三种,其他都是这三种基本语法结构的组合,再加上一些语法糖。
这里我们还是以前面提到的“(张三|李四 *) *”这个正则表达式为例。“张”和“三”以及“李”和“四”这两组字符内部的结构,都属于顺序结构。“张三”和“李四 *”这两者则属于分支结构中的两个分支。而“四*”和整个正则表达式“(张三|李四 *) *”都是循环结构,并且前者嵌套在后者内部之中。
根据上面的分析,从正则表达式作为一个声明式编程范式的领域特定语言DSL的角度来讲,正则表达式的顺序结构、分支结构、循环结构这三种基本语法结构是非常简洁、紧凑的。这几乎是作为声明式编程范式的领域特定语言的基本特点,而正则表达式将这一点体现得尤为淋漓尽致。
其中,由于连接结构最为普遍和常见,因此不通过元字符来表示,而是直接以前后顺序来表示;分支结构通过竖线元字符“|”这个或运算符来表示;而循环结构则通过量词元字符“ *”、“+”或“{n,m}”等来表示。
这三种基本语法结构在使用时,只需要简单直接地进行声明式描述,不需要程序员通过复杂的命令式程序语句来进行匹配逻辑和匹配算法的设计,从而大大简化了文本查找匹配功能的实现。
总结
好了,今天的内容讲完了,我来带你总结回顾一下。
今天我为你提供了一个新的角度,那就是除了从正则表达式自身的语法元素、功能特性等角度来理解正则表达式之外,我们还可以站在编程语言以及编程范式的层面去理解正则表达式。
其实啊,正则表达式是一门第4代面向问题的编程语言,使用针对特定问题领域专门设计的语法元素来编写表达式。第4代语言相对于第3代语言,更专注于某个特定、专门的业务逻辑和问题领域。它的各个语法元素本质上就是常见的通用编程语言中的处理逻辑和算法实现的体现,并且同样具有三大基本语法结构,也就是顺序结构、分支结构和循环结构。
思考题
最后,还是给你留一个思考题。对于从编程语言的发展和演化角度,以及从编程范式的角度来理解正则表达式,给你带来了什么启发呢?这对于其他编程语言的学习和程序设计,究竟又有什么作用和实际意义呢?
欢迎留言参与讨论。今天的课程就结束了,希望可以帮助到你。如果有收获,也欢迎你把这节课分享给你的朋友或者同事,一起交流一下。
使用正则提高你的人生效率
你好,我是伟忠。
时间过得真快,我们这门《正则表达式入门课》到这里也就告一段落了。
虽然我之前做过每日一课的课程,也经常给朋友像讲课一样讲正则。但实际上,想要真正把正则用一门课的形式来呈现出来,还是不简单的。我每篇文章的写稿时间基本都在十个小时以上,可以说,正则这个专栏倾注了我很多的心思。每次深夜绞尽脑汁写稿略感疲惫的时候,看看大家充满热情的留言,真是给了我很多的力量。
所以借着这个宝贵的机会,我想特别感谢所有参与这个专栏的同学,感谢你们一路的陪伴和坚持,借着这个机会,我也再和你唠叨唠叨,如何运用正则以及如何进一步成长。
正则涉及的编程语言和工具非常多,我没有办法去完全讲完,因为那样专栏会变得比较琐碎。在我看来,咱们学习任何内容,在一开始时,都不要过分去注重细节,重要的是掌握正确的方法,先从整体上入手,掌握核心的概念。比如当你学习了字符组、多选结构、量词、锚点、贪婪&非贪婪、流派、匹配原理这些核心知识之后,你要在后续遇到问题时,查阅一下相关文档,很快就可以解决掉了。
熟练运用,而不滥用
有些同学在学习正则之后,遇到问题总是想“展示一下身手”,这种心理无可厚非,但一定要记住在使用正则的过程中,一定要克制。
我之前在课程里面提到的,“ 密码是6位,且不能有连续两个数字出现”这个例子,如果你要高效解决这个问题,没必要非得用正则,完全可以遍历一下字符串,看下有没有两个连续的数字,这样解决起来容易。
所以啊,不要总想着非得用正则来完成事情,也不要总是想使用一个正则来完成整件事情,如果你把一个正则拆分成多个正则更方便、更易于理解和维护,我们就拆成使用多个正则来完成。比如刚刚说的例子,我们可以先判断输入的内容是不是符合 \w{6}, 再判断里面是不是有连续的两位数字,这样通过分步解决会简单很多。
我们要熟练运用正则,但不能滥用正则,不要手里拿着锤子,看啥都是钉子。用普通字符串就能很好解决的问题,就不要使用正则。用多个正则更清晰,更不容易出错,就不要有“非得要用一个正则解决所有问题”的执念。毕竟我们学习正则的目的,就是想高效地完成文本处理工作,但完成这个目标有很多方式,正则只是其中一种。
如何进一步成长?
在这个技术太多,变化太快的时代,我们需要不断地学习。同样,我也很庆幸正是在这个时代,有了像极客时间这样的平台,我们能够以专栏这种全新的方式来进行学习。可能你会觉得技术太多,压根学不完,但不要担心,基础原理性的东西绝对可控。我们需要做的就是沉下心来,不要浅尝辄止,越是基础的内容越重要,一次性多投入些时间,弄清楚,搞明白。多动手练习,实践出真知。
当你觉得你掌握了正则之后,你可以尝试把它教给别人,或者你可以想一下,如果让你来讲正则,你会怎么讲? 这样能够让你有更深刻的理解,用这个方法,你就能知道,自己到底是不是真的搞懂正则了。
如果你坚持学完了这个专栏,那么你对正则的掌握已经超过了绝大多数人,在日常工作中使用应该没什么问题了。另外,如果你觉得还没有学过瘾,可以再去看一下《精通正则表达式》(第3版)和 《正则指引》(第2版)这两本书。第一本书不用多说,这应该是正则方面最为权威的一本书了,对正则的原理等都有比较深入的讲述。第二本是余晟写的,有大量的编程语言示例,比较接地气,对正则表达式如何处理中文有比较详细的讲解。
到此,我的《正则表达式入门课》也就告一段落了。不过课程结束并不是终点,我们还可以在留言区互动交流。我也会不定期更新专栏,以加餐等方式来继续完善这篇专栏,和你一起继续精进。我坚信正则表达式这个工具,掌握之后一定会让你受益终生,愿正则能提高你的人生效率。
当然,我知道很多同学都喜欢“潜水”,但是在本篇专栏的最后,我希望你能 分享一下你的学习方法。此外,我给你准备了一份毕业调查问卷,题目不多,希望你花两分钟填写一下,我非常想听听你对这个课程的收获和建议。最后,再次感谢!我们留言区见。

特别加餐 | ChatGPT类AI聊天机器人能看懂正则表达式?
你好,我是伟忠。
最近 ChatGPT 非常火,相信大部分同学也做过一些尝试,我们可以使用 ChatGPT辅助完成部分代码,在基础上做一些修改、调试,基本上就可以用了,确实给编程效率带来了很大的提升。
但同时也有一些同学焦虑,觉得 ChatGPT 可能会取代程序员,造成自己失业。但我认为也不用太担心,使用多了你就会发现,虽说ChatGPT 确实可以帮助回答一些编程上的问题,但都是一些知识片段,而且有时候会出现错误,也需要用户自己去判断。我们可以把ChatGPT这一类的AI聊天工具当成一个老师,或者知识渊博的朋友,你有想了解或者有困惑的地方,都可以和他聊聊。既不用担心请教同事问题太简单让自己没面子,也不用担心麻烦对方。
我们今天的主题就聚焦在正则表达式与ChatGPT类AI智能聊天机器人,看看AI聊天机器人能在哪些方面帮助我们更好地使用正则表达式。
AI聊天机器人在正则方面的应用
在正则方面,ChatGPT的重要作用表现在它可以 提供参考示例、 自动检测错误、 解释正则表达式 以及 提供练习和测试 等多个方面的功能,让用户能够更加容易入门、更加熟练地掌握正则表达式的使用。

提供参考示例
首先我们来看下提供参考示例,AI对话机器人可以帮助用户查找和提供与其输入相关的正则表达式示例。比如我们需要一个校验邮箱的正则,可以直接问“验证邮箱的正则表达式”,就可以得到对应的答案,连自己看网页从里面挑选的时间都省了。示例里面我使用的是 New Bing,不仅给出了Python代码的示例,还给出了它参考了哪些网页上的信息综合得到的答案。
我们也可以要求他使用Go语言实现,很快就能给出对应的代码。

自动检测错误
接着,我们来看一下自动检测错误:AI对话机器人可以帮助用户检测正则表达式中的常见错误,并提供相应的建议。比如我问了这样的一个问题“正则表达式 [a-zA-Z]+ 无法匹配上所有的单词,请给出原因”,我们可以看到,解释还是挺好的。
对于正则中容易出现的错误,ChatGPT类对话机器人也可以检查表达式语法、结构、语义和常见的逻辑错误,来为用户提供建议和错误提示。
以下是10个在正则表达式输入时ChatGPT可能会检测到的常见错误。
-
忘记转义特殊字符:如正则表达式中忘记对.、+、*等特殊字符进行转义,导致匹配结果与预期不符。
-
括号不匹配:如正则表达式中括号未正确配对,或者圆括号和方括号混淆使用,导致表达式无法编译或导致匹配结果出错。
-
错误的字符类别:如意外使用了一些不被支持或无效的字符类别,导致表达式无法解析或处理。
-
量词位置错误:如在量词前加上一个无效的字符或在其后离开空格,导致表达式无法解释或产生语法错误。
-
命名捕获组错误:如在捕获组中错用了命名参数,或者命名参数定义之前已经开始匹配,导致表达式无法编译或导致匹配错误。
-
长度限制错误:如使用过长的表达式,导致匹配速度缓慢,甚至崩溃应用程序的性能。
-
字符集错误:如正则表达式使用了过于复杂的字符集和逻辑,导致表达式需要花费大量的时间来匹配字符串。
-
贪婪匹配错误:如使用贪婪匹配操作符(如.*)时,出现了意料之外的匹配结果,导致表达式无法满足需要。
-
边界匹配错误:如在表达式中使用了^和$进行边界匹配时,导致匹配结果出错或无法处理。
-
错误的优先级:如在表达式中使用了优先级不正确的操作符,导致匹配结果出错或无法处理。
对于以上错误,ChatGPT可以通过分析正则表达式的语法和结构,检查其逻辑和语义上的正确性,帮助用户检测错误并提供相应的建议。
解释正则表达式
接着,我们看一下AI对话机器人在解释正则表达式方面的应用,如果你有看不懂的正则表达式,它可以帮助用户解释每部分的功能,并提供与之相关的文档和资源。
我们这里使用之前课程中的一些示例,尝试让它来进行解释。
练习和测试
最后,我们来看一下如何使用AI对话机器人进行练习和测试,进而加深对正则表达式的理解和熟练度。
AI聊天机器人的不足
虽然 ChatGPT类AI对话机器人非常强大,在学习正则方面,可以是一个得力助手,但它并不完美,有时给出的答案不是最佳答案,甚至是错误的回复。所以对于AI给出的内容,我们一定要自己动手验证,不能全信。
下面是一个示例,我尝试纠正它的错误,我们可以看到,虽然它认识到转义符号只能有一个,但最终给出的代码还是两个转义符号,猜测可能是网页内容呈现上还需要进一步优化。

所以我们还是需要自己有一定的识别能力,不能完全靠AI。我们也需要自己去了解更多的领域知识,只有自己了解后,才知道如何向 ChatGPT类聊天机器人提问,也才能判断它给出的答案是不是靠谱。但AI的进步飞快,相信会越来越完美的。
总结
AI智能聊天机器人给我们知识检索带来了很大的便利性,让我们可以使用自然语言去提问,也很大程度上提高了我们的工作效率。在工作和生活中要用好这类AI智能聊天助手,把它当作一个向导,让它们更好地为我们提供服务。
我们可以利用它给出正则示例、检测正则中的错误、解释正则表达式,以及利用它来练习和测试正则表达式。
课后思考
目前国内外聊天机器人产品非常多,比如国外的 OpenAI 的 ChatGPT、谷歌的 Bard、微软的 New Bing、国内的百度的文心一言、阿里的通义千问等,你使用过哪些AI对话机器人呢?你觉得它们是如何学会正则表达式的呢?
期待你的留言,我们评论区一起交流讨论。
结课测试 | 这些正则知识,你都掌握了吗?
你好,我是涂伟忠。
《正则表达式入门课》这门课程已经完结一段时间了,在完结的这段时间里,我依然收到了很多留言,很感谢你一直以来的认真学习和支持!
为了帮助你检验自己的学习效果,我特别给你准备了一套结课测试题。这套测试题共有20道题目,包括 11道单选题和9道多选题,满分 100 分,系统自动评分。
还等什么,点击下面按钮开始测试吧!
